On this page
GreptimeDB stores time-series data through a storage engine named Mito. Mito is responsible for accepting writes, making them durable, organizing data for later reads, and cleaning up old or overlapping files in the background.
Time-series data has a recognizable shape. Writes are frequent. Most rows are appended with newer timestamps. Queries usually ask for a time range, a subset of series, and a few columns. Deletes and updates exist, but they are less common than inserts. Mito is designed around this shape instead of behaving like a general-purpose transactional storage engine.
This article explains Mito from the top down: why it uses an LSM-tree design, how data moves through the write path, how data is laid out inside storage files, how scans skip unnecessary data, and how indexes and compaction fit into the engine.
Why LSM Fits Time Series
Mito uses an LSM-tree style design. In an LSM tree, new data is first written to memory and durable logs, then later flushed into immutable files. This works well for time-series workloads because it keeps the write path fast and turns many small writes into larger sequential file writes.
Mito stores data by region. A region is a physical shard of table data. Each region owns its metadata, in-memory buffers, SST files, manifest, and storage options. An SST is an immutable storage file, and the manifest is the metadata log that records changes to the region, such as newly flushed files or files removed by compaction.
The following diagram shows the main components around Mito and how data moves between memory, durable logs, SST files, metadata, and object storage.
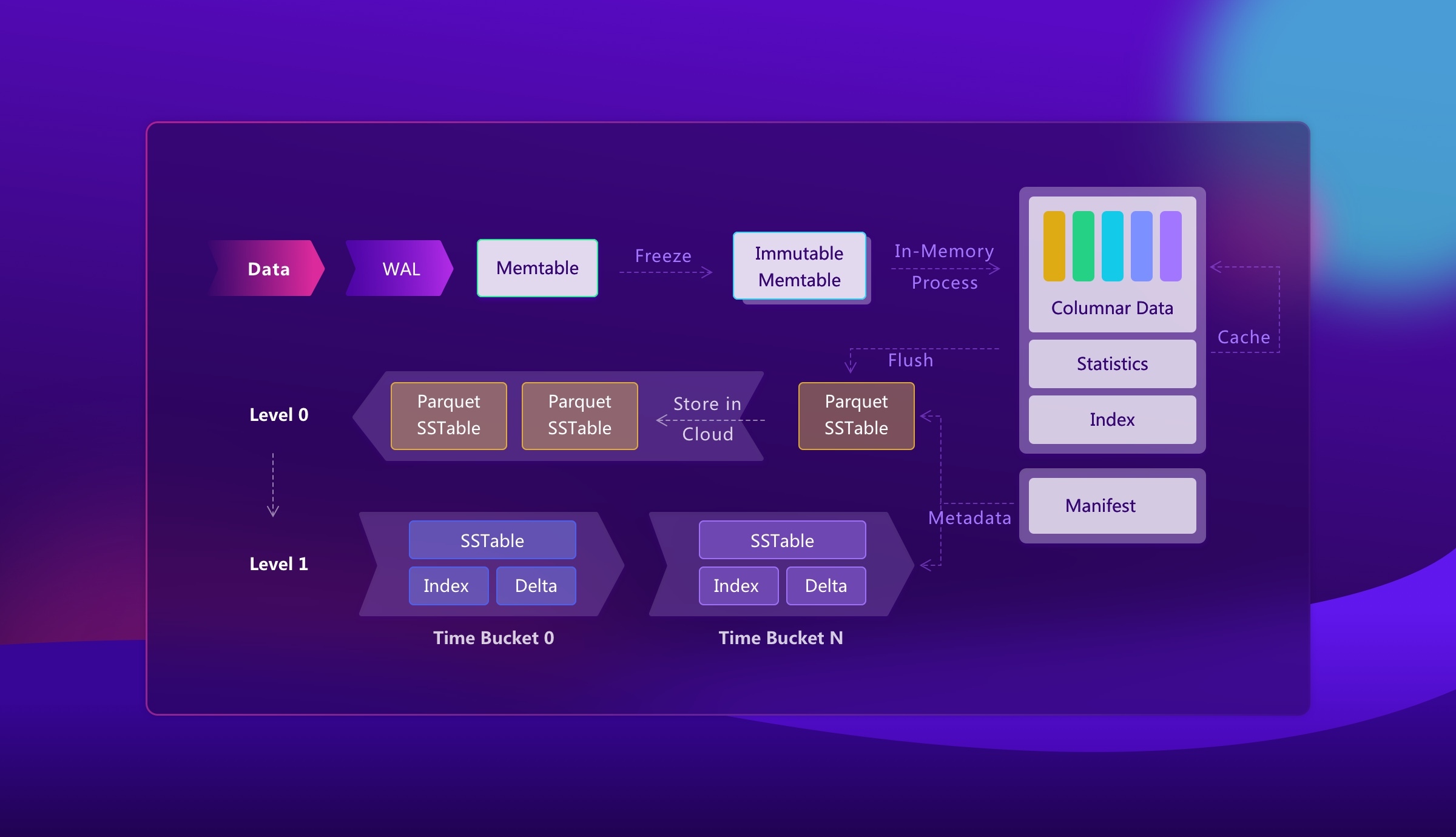
The write path has three main steps:
- Mito writes incoming rows to the WAL first. The WAL, or write-ahead log, makes the write durable before it is flushed into immutable files. Depending on deployment, the WAL can be stored on local disk, cloud block storage such as EBS, or Kafka.
- Mito inserts the same rows into a mutable memtable. A memtable is an in-memory buffer that serves recent writes and accumulates data before persistence.
- When the memtable is ready to persist, Mito flushes it into Parquet SST files and records the file metadata in the region manifest.
This design keeps ingestion simple: acknowledge a write after it is durable in the WAL and visible in memory, then turn buffered data into columnar files in the background.
How Data Is Organized
Mito organizes data for the common time-series read pattern: narrow the time range, choose a set of series, then read only the needed columns.
Within a region, rows move from the mutable memtable to immutable memtables and then to SST files. Freshly flushed SST files may overlap in key and time range. Background compaction later rewrites them into fewer, better-organized files.
The following diagram shows the logical layout of an SST file and the metadata used during reads.

The two most important ordering concepts are the primary key and the time index.
The primary key is usually made of tag columns that identify a time series, such as host and region. Rows with the same primary key belong to the same series. The time index is the timestamp column. It orders points within a series and is the dominant pruning dimension for time-range queries.
For example, consider a table that stores host metrics:
sql
CREATE TABLE host_metrics (
host STRING,
region STRING,
ts TIMESTAMP TIME INDEX,
cpu DOUBLE,
memory DOUBLE,
PRIMARY KEY (host, region)
);Conceptually, rows are grouped by primary key and ordered by time:
| host | region | ts | cpu | memory |
|---|---|---|---|---|
| host-a | us-east | 10:00 | 0.42 | 7.1 |
| host-a | us-east | 10:01 | 0.47 | 7.4 |
| host-a | us-west | 10:00 | 0.31 | 6.8 |
| host-b | us-east | 10:00 | 0.80 | 8.6 |
In storage, host and region are primary-key columns, ts is the time index, and cpu and memory are field columns. Mito also stores internal columns, such as encoded primary-key data, sequence numbers, and operation types, so it can merge, deduplicate, and apply deletes correctly when reading from multiple memtables and SST files.
Each Parquet SST is split into row groups. A row group is the main unit that Parquet can read or skip efficiently. For each row group, Parquet stores column statistics such as minimum value, maximum value, and null count. Mito also records file-level metadata, including the file time range, row count, file size, row-group count, available indexes, and primary-key range when available.
Time windows are another important part of the layout. A time window is a timestamp range used later by compaction and retention.
How Mito Scans Data
A scan starts with the data visible to the query: current memtables and relevant SST files. It also knows the predicates and time range. Mito uses this information to reduce the amount of data that must be opened, decoded, and filtered.
The following diagram shows the pruning flow. The key point is that Mito does not rely on a single pruning mechanism. It combines time ranges, row-group statistics, and indexes.

Take this query as an example:
sql
SELECT ts, cpu
FROM host_metrics
WHERE host = 'host-a'
AND region = 'us-east'
AND ts >= '2026-05-29 10:00:00'
AND ts < '2026-05-29 11:00:00'
AND cpu > 0.7;Mito first extracts the time range from predicates on the time index. Files and memtables whose stored time ranges do not intersect the query range can be skipped before opening readers. This is usually the cheapest and most important pruning step for time-series data.
Next, Mito uses min-max statistics. If a row group's statistics prove that no row can match a predicate, the row group is skipped. For example, a row group with cpu maximum value 0.6 cannot match cpu > 0.7. Row-group statistics are coarse, but they are cheap and work well when data has locality.
Indexes provide more selective pruning when statistics are not enough. An index is auxiliary data built for one or more columns so a scan can rule out more rows or row groups before decoding the data columns. Mito stores index data in Puffin files. Puffin is an auxiliary file format used to keep index data next to SST metadata without placing it inside the main Parquet data file.
During scan planning, Mito checks whether the query predicates can use available indexes. Index results are combined with the row groups that survived time-range and min-max pruning. The reader then scans the remaining data and applies exact filters.
For tables that may contain updates or deletes, Mito also merges and deduplicates rows according to sequence information and operation type. Append-only tables can scan with less ordering work when the query does not require ordered series output.
Indexes And Compaction
Indexes are part of the storage layout. When Mito writes SST files, it can also build index files for columns that benefit from selective pruning. The SST metadata records which indexes exist and which columns they cover.
This design fits object storage well. Data files and index files can be managed together, cached together when useful, and skipped together when metadata proves they are irrelevant to a query.
Compaction keeps the LSM tree healthy. Without compaction, many small or overlapping SST files would accumulate, making reads more expensive. During compaction, Mito reads selected SST files, merges their rows, writes new SST files, updates related index metadata when needed, and commits the result through the region manifest.
The following diagram shows time windows at the region level. Each window is a timestamp bucket that may contain multiple SST files. TTL can remove expired files from older buckets, and compaction can merge overlapping SST files within a bucket.

Mito uses Time Window Compaction Strategy, or TWCS, as the default compaction strategy. TWCS groups candidate files by timestamp range, so files in the same window are compacted together. When a table has TTL configured, compaction can also remove expired SST files whose data is outside the retention window.
Summary
Mito is GreptimeDB's storage engine for time-series workloads. It combines a fast LSM-style write path with a columnar SST layout, region-level metadata, row-group statistics, optional index files, and time-window compaction.
The design focuses on avoiding unnecessary work. Time ranges skip whole files. Min-max statistics skip row groups. Indexes prune selective predicates. Compaction rewrites overlapping files into cleaner time windows and removes expired data.
Together, these pieces let GreptimeDB handle high-frequency time-series ingestion while still making common time-range and series-oriented queries efficient.
If you are interested in GreptimeDB's storage engine, join us on Slack or GitHub.




