
On this page
This article was co-authored by Li Auto's Vehicle Data team and Greptime.
When a vehicle fault occurs, all you typically see is a few dozen seconds of data around the event. But what if the root cause was planted days ago?
At Li Auto, we applied software-style observability to the vehicle: collecting data during R&D and after-sales to flag risks early, diagnose faults, and understand how each car actually behaves on the road. For a fast-iterating EV platform, this is the difference between guessing and debugging.
The pipeline itself is nothing new: collect data on the vehicle, compress and upload it, then clean and store it in the cloud. In practice, though, this pipeline often samples too little at too low a resolution. When something actually goes wrong, you're left squinting at shadows.
That led us to a fundamental question: can we capture raw data from every vehicle subsystem and actually put it to work?
Why Raw Data?
Raw data preserves the full picture. Just as software engineers rely on logs and traces to follow a request end-to-end, vehicle engineers need millisecond-level (sometimes microsecond-level) traces across subsystems — especially when you're trying to align signals across ECUs and buses. Routine sampling smooths exactly that detail away.
The industry's first answer was the on-board "black box": continuously monitor in-vehicle signals, and when a predefined rule triggers (say, a specific DTC), package and save the data around the event for later upload. It's a pragmatic approach:
- Storing data only on events minimizes storage pressure and protects flash longevity.
- Transmitting only short clips keeps bandwidth and cloud processing costs low.
- The vehicle only needs to record, so the performance impact is minimal.
But optimizing so aggressively for cost and performance comes at a real cost to observability:
- Data is only captured around faults, leaving everyday vehicle behavior invisible.
- Rule-driven capture means you only see known problems — the "unknown unknowns" stay hidden.
- At its core, this is still a post-mortem tool. It's monitoring, not observability.
True observability requires continuous, low-cost raw data collection. That immediately raises a cascade of new questions:
- Raw bus messages, or decoded signals?
- Structured or unstructured storage?
- What does the upload pipeline look like, and how should the cloud side manage the data?
Behind all of these is a constant tension between data value, collection overhead, and cost. With raw data, pressure comes from every direction: CPU consumption for on-vehicle parsing, cloud compute for processing, query latency, and — the one nobody escapes — bandwidth bills.
Li Auto's Approach: Bringing a Time-Series Database On Board
After weighing the trade-offs, we decided to deploy the data collector, signal decoder, and a time-series database together on the vehicle. The reasoning was straightforward:
- Reduce the volume of data transmitted between vehicle and cloud to cut bandwidth costs.
- Leverage on-vehicle compute to shift processing upstream, easing the load on the cloud.
Concretely, the collector decodes raw bus messages on the spot, moving the ETL work that traditionally happens in the cloud to the vehicle itself. From that point on, every downstream component works directly with structured, semantically meaningful data.
Once structured, data compresses far more efficiently. Using columnar techniques like delta encoding and run-length encoding, followed by general-purpose compression, the resulting files are over 30% smaller than raw messages with generic compression alone.
Because the data now takes the form of block-organized files — and at volumes much larger than traditional downsampled telemetry — streaming over TCP or MQTT became a poor fit: it's harder to make non-blocking and predictable under spotty connectivity, and risks interfering with the vehicle's real-time communication with the control center. We switched to uploading files directly to object storage over HTTP.
The On-Vehicle Time-Series Database: Balancing Performance and Cost
With the architecture settled, the next step was finding a time-series database that could run on a Qualcomm Android platform. It needed to:
- Handle high-throughput writes with high compression ratios.
- Produce files that could be ingested cheaply on the cloud side.
- Eventually support pushing query and compute capabilities further down to the vehicle.
We evaluated multiple embedded TSDB options under the same constraints (ARM/Android, CPU budget, flash wear, file-based ingestion). The table below summarizes the gating criteria rather than naming specific vendors.
| Capability | Why It Matters | GreptimeDB | Option A | Option B |
|---|---|---|---|---|
| Time-series data model | Vehicle signals are inherently time-series; a purpose-built model is essential for efficient storage and query | ✅ | ✅ | ✅ |
| Runs on ARM / Android | All vehicle SoCs are ARM-based — if it can't run there, nothing else matters | ✅ | ❌ | ✅ |
| Single-process, low resource footprint | On-vehicle resources are limited; the database cannot steal CPU from navigation, cockpit, or other critical functions | ✅ | ❌ | ❌ |
| Columnar data layout | Sensor signals are highly repetitive; columnar storage dramatically improves compression, directly reducing bandwidth cost | ✅ | ❌ | ❌ |
| Flash-friendly I/O | Vehicle storage is flash-based; frequent small writes accelerate wear and shorten hardware lifespan | ✅ | ❌ | ❌ |
| Vehicle-cloud homogeneity | Files generated on the vehicle can be loaded directly into the cloud database with no ETL, saving massive cloud compute | ✅ | ❌ | ❌ |
Selection was only the first step. The real challenge was adapting to the production vehicle environment. At Li Auto, CPU budget is non-negotiable — the data service must be lightweight enough that it never impacts other on-board functions.
We made extensive targeted optimizations. For the write path, gRPC was easy to integrate but its per-message serialization and copy overhead was too expensive for our on-vehicle CPU budget. Instead, we designed a custom mechanism based on RingBuffer and Arrow IPC specifically for the vehicle platform. By leveraging shared memory and a zero-copy serialization protocol, we significantly reduced CPU overhead.
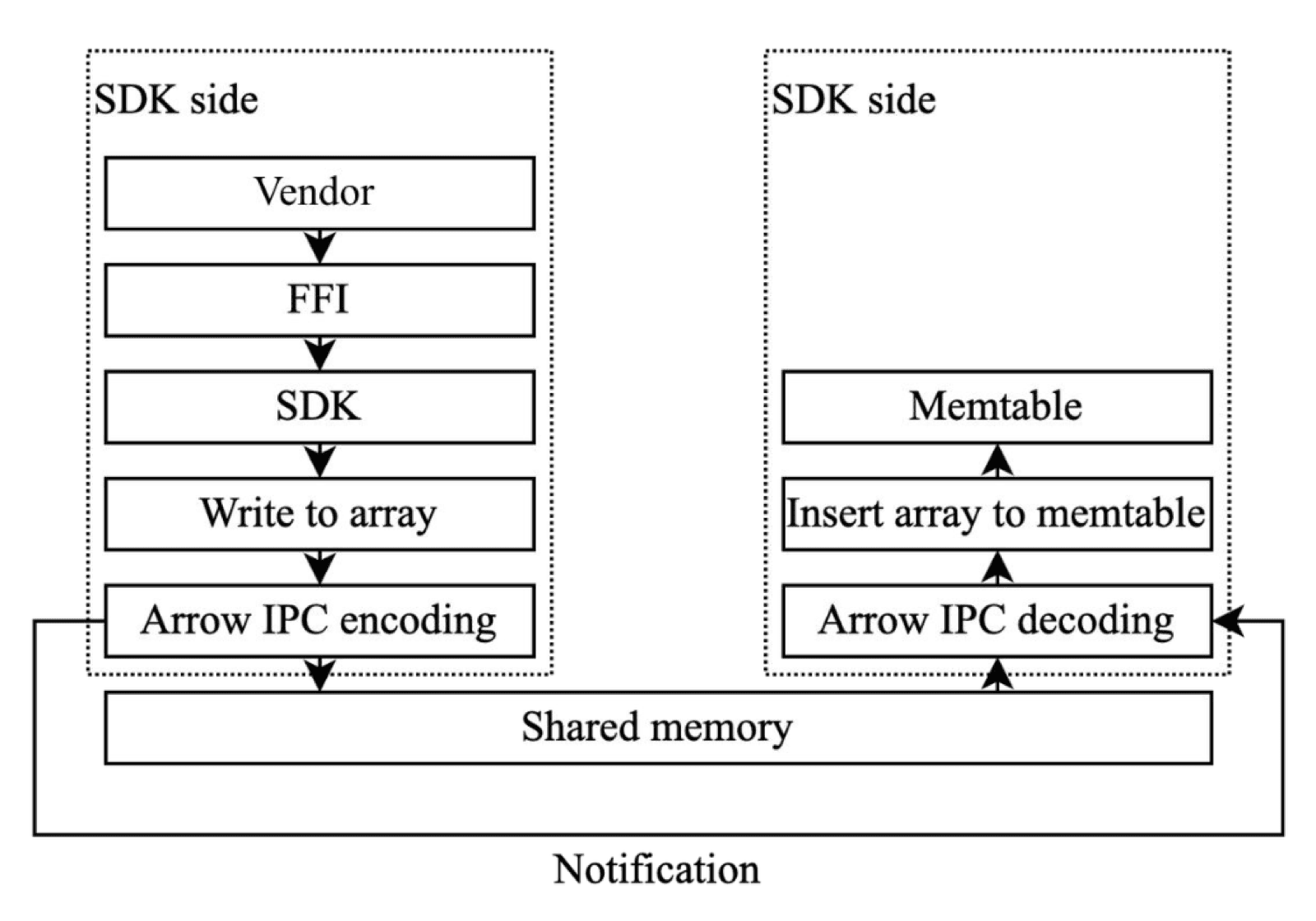
High-performance writes via shared-memory RingBuffer
Flushing data to disk also required careful engineering. Writing one record at a time yields poor compression and creates swarms of small files that accelerate flash wear. So we optimized the I/O path in depth:
- Tuned columnar encoding for the characteristics of automotive sensor data, significantly reducing raw data volume.
- Layered zstd compression on top, with a novel use of pre-trained dictionaries — generated offline from historical data and deployed without any runtime computation cost — to boost compression on small batches.
- Implemented single-file sequential append writes in the storage engine to batch data into a unified file, reducing write amplification on flash.
Together, these optimizations dramatically cut flash write volume and write amplification while keeping CPU overhead low.
Memory usage was equally tightly controlled. We designed a compact in-memory buffer structure for batch writes, using Arrow IPC's columnar layout rather than traditional BTree or SkipList structures. In production, memory usage dropped from 1.4 GB to roughly 300 MB.
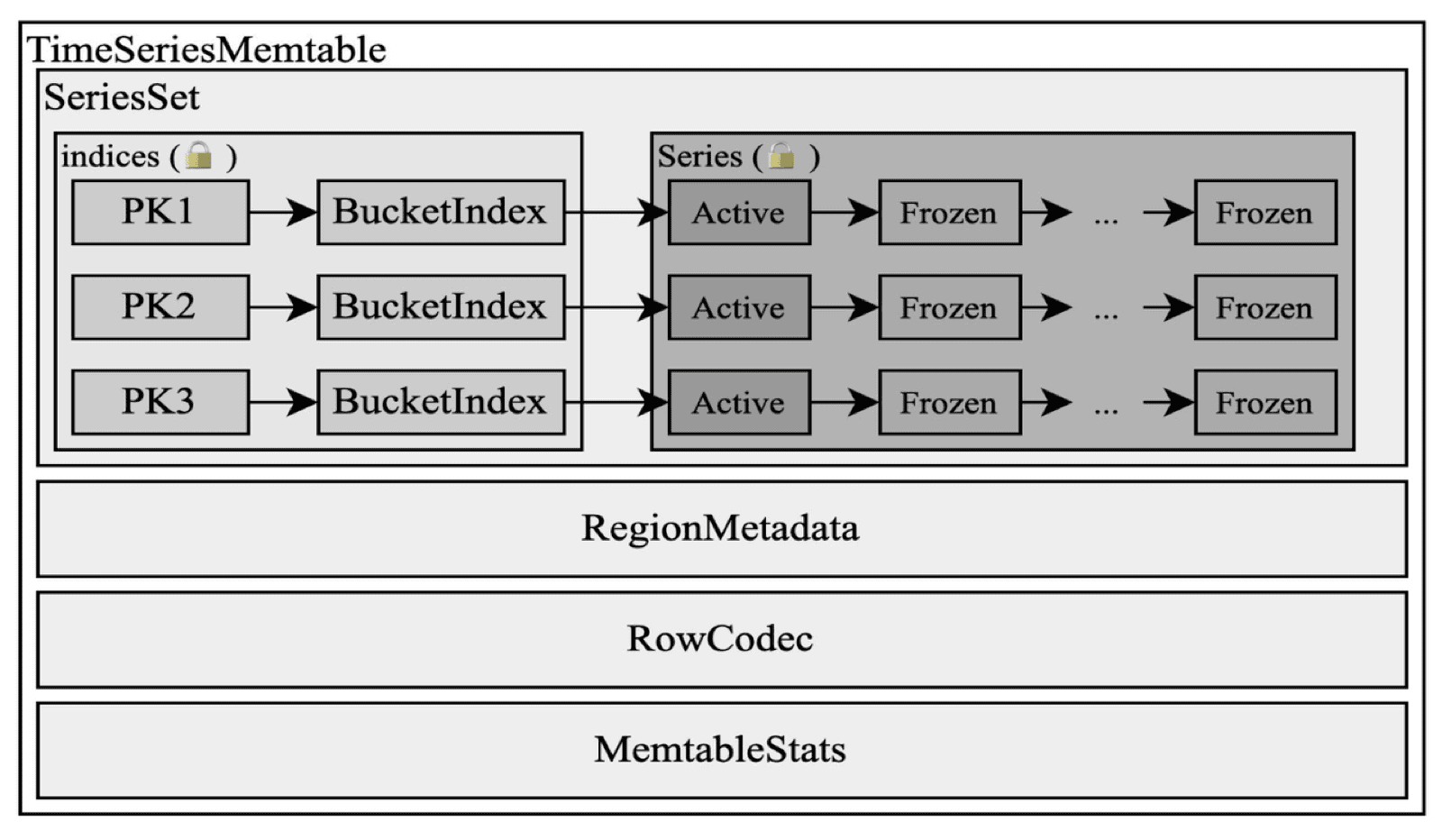
Compact memory layout reduces footprint
Vehicle-Cloud Unity: A Natural Extension of Data Flow
Because the vehicle and the cloud share the same data architecture (what we call vehicle-cloud homogeneity), files generated on the vehicle can be loaded directly into the cloud database with no conversion or reprocessing. As Li Auto's fleet grows, the cloud compute savings from this approach are substantial.
The surge in data volume also challenges storage. Thanks to a disaggregated storage-compute architecture, we can park massive datasets in low-cost object storage — often an order of magnitude cheaper than keeping everything on local disks in a warehouse-style setup (depending on retention period and access patterns). Both storage and compute scale elastically on demand, so you truly pay only for what you use.
Zooming out, every on-vehicle database and the cloud database together form a single logical cluster. Vehicles handle write sharding; data syncs to the cloud over the vehicle-cloud link; the cloud takes on complex analytical queries.
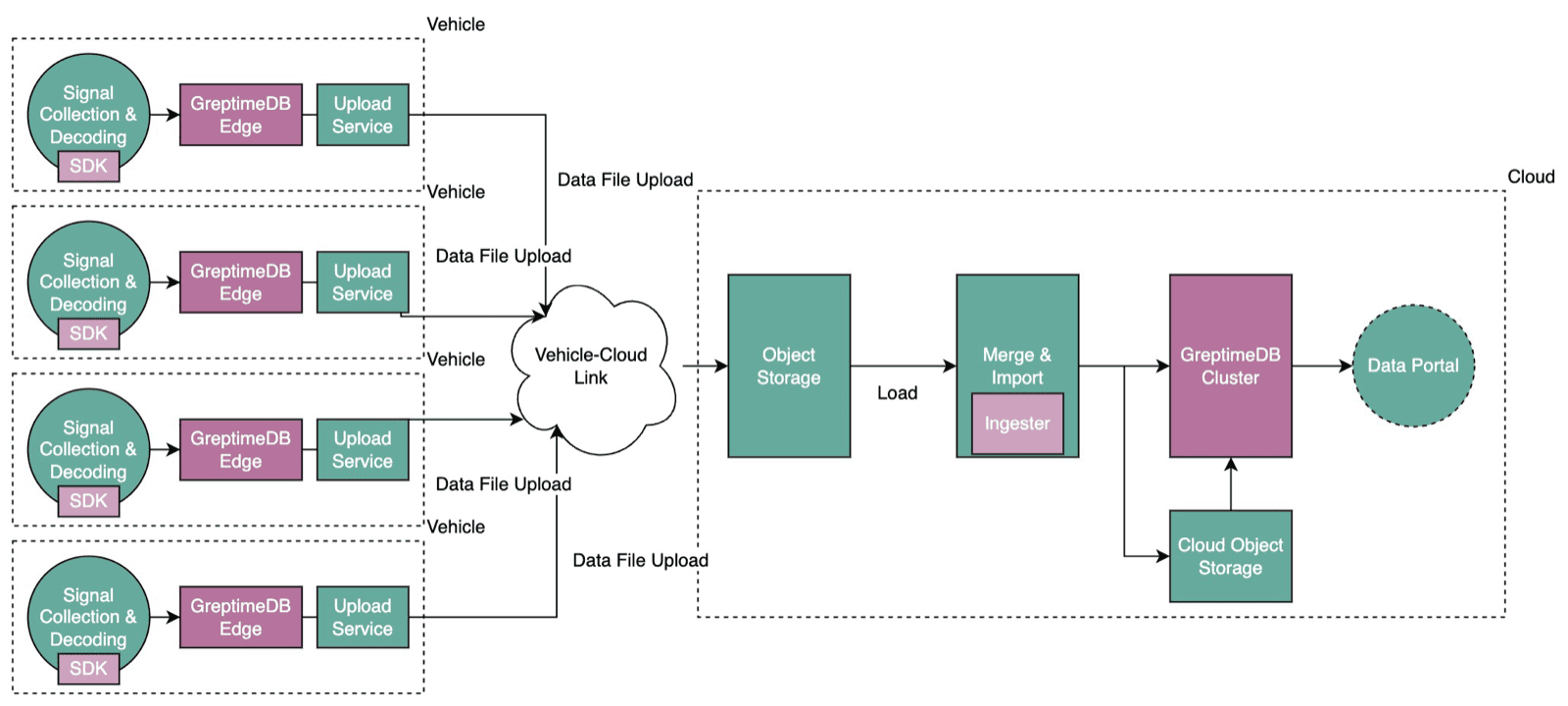
Seamless vehicle-cloud collaboration
Toward Vehicle Observability at Scale: How an On-Board TSDB Enables Advanced Diagnostics
Putting a time-series database on the vehicle started as a way to "store more and transmit affordably." But as the architecture matured, we discovered that having a complete, queryable database on the vehicle opens up possibilities far beyond storage — it is redefining advanced diagnostics and analytics.
From Fragments to Complete Records
A traditional black box captures only a few dozen seconds around each fault — a crime-scene photo with no context. With an on-vehicle time-series database, Li Auto can store the full set of structured signals and logs, building a complete operational record for every individual car.
When a customer reports "my car has been feeling a bit off lately, but I can't pinpoint what's wrong," the service team no longer has to rely on luck. They can scrub through days of millisecond-resolution signals, looking for the subtle anomalies hiding behind vague symptoms.
Seeing the Invisible
Some faults can't be explained by a single DTC. Intermittent degradation of the three-electric system, NVH anomalies under specific driving conditions — these are often the product of multiple signals interacting over time, and single-threshold alerts simply can't catch them.
With an on-vehicle time-series database, long-duration, high-frequency data can be analyzed on the vehicle or in the cloud: aligning voltage, current, temperature, and RPM signals on the same time axis and examining their temporal relationships and co-occurrence patterns. Complex faults that were previously invisible to traditional diagnostics become visible, analyzable, and predictable.
From Reactive Response to Proactive Alerting
More fundamentally, pushing the database to the vehicle means diagnostic logic can follow. Service teams can push their accumulated diagnostic strategies — as algorithms or query jobs — down to the car, giving the vehicle the ability to perform advanced self-diagnosis.
Picture this: instead of waiting for a fault and then uploading data to "call for help," the vehicle continuously scans for anomalous patterns against its locally stored data during normal driving. When it detects signal combinations approaching a known precursor pattern, it can issue a proactive alert, trigger early intervention, or even schedule an inspection before the driver notices anything at all.
From "it broke — find out why" to "it might be about to break — let's take a look." That shift is exactly the diagnostic paradigm that an on-vehicle time-series database makes possible.
Conclusion
Through a vehicle-cloud unified data architecture built on GreptimeDB, Li Auto has created a next-generation raw-data observability platform. It dramatically improves data visibility and usability while striking an elegant balance between performance and cost through deep technical optimization. More importantly, it lays the data foundation for forward-looking capabilities like advanced diagnostics and proactive alerting.
This architecture has saved Li Auto tens of millions in bandwidth and cloud resource costs, and it validates a broader point: true observability doesn't have to come at the price of runaway costs and performance trade-offs. Data — the lifeblood of the intelligent vehicle — continues to drive product evolution and customer experience.
To learn more, visit Greptime's vehicle-cloud solution page.




