
On this page
Observability for LLM applications doesn't work like traditional microservices. An LLM call produces far more telemetry than an HTTP request, but the harder problem is the shape of that data. Prompts and completions are large text blobs. Tool call parameters take a different structure every time. An agent's multi-step reasoning can't be captured in a fixed schema. And beyond the usual "which model was called and how long did it take," you also need to know how many tokens were consumed, how much the call cost, and whether the answer was any good.
Traditional OTel semantic conventions don't cover any of this. http.request.method and db.system.name are meaningless for LLM calls. The community needed a dedicated spec.
In April 2024, OpenTelemetry formed the GenAI Special Interest Group (GenAI SIG) under the Semantic Conventions SIG[1]. The original scope was LLM client call tracing. Since then it has expanded to cover agent orchestration, MCP tool calling, content capture, and quality evaluation: six layers in all. As of this writing, the OTel docs site shows Semantic Conventions v1.41.0[2], with the latest GitHub release at v1.41.1 (a k8s codegen fix only, no GenAI changes)[3].
Each layer below covers what the spec defines, why it's designed that way, and where it stands in maturity. If you read our earlier piece on Agent Observability, this is the spec companion: how the community is standardizing around the challenges that article described.

How the Spec Evolved: From Early Days to v1.41
When GenAI SIG kicked off in April 2024, the goal was straightforward: define a standard set of attributes for LLM client calls (model name, token usage, latency) so that different instrumentation libraries produce consistent telemetry. Early versions introduced gen_ai.system, gen_ai.request.model, and a pair of histogram metrics.
v1.37 was the turning point. It overhauled how chat history is recorded[4]. The old per-message events (one event per message) were replaced by three aggregated attributes (gen_ai.system_instructions, gen_ai.input.messages, gen_ai.output.messages) stored either on the span or in a new gen_ai.client.inference.operation.details event. The reason was practical: per-message events flooded multi-turn conversations with fine-grained events that were painful to query and correlate.
Every subsequent release has included GenAI changes:
| Version | GenAI Changes |
|---|---|
| v1.37[4:1] | Chat history revamp; gen_ai.system replaced by gen_ai.provider.name |
| v1.38[5] | Evaluation event; tool definitions and call details; invoke_agent kind guidance; embeddings dimension; multimodal JSON schema |
| v1.39[6] | MCP semantic conventions |
| v1.40[7] | Retrieval span; cache token attributes; Anthropic input token calculation guide |
| v1.41[8] | execute_tool span naming requires tool name; reasoning tokens; invoke_workflow; streaming metrics; split invoke_agent into CLIENT/INTERNAL |

As of May 2026, the GenAI and MCP semantic conventions remain in Development status[2:1]. The docs say it plainly: "This transition plan will be updated to include stable version before the GenAI conventions are marked as stable." No public timeline for stabilization. The 2026 Semantic Conventions Roadmap[9] is collecting proposals from each sub-SIG, but nothing's committed.
Attribute names and structures may still change. The core concepts have settled though, and the spec provides OTEL_SEMCONV_STABILITY_OPT_IN to manage version transitions. Building on the spec today is a reasonable bet.
Layer 1: Client Spans — Standardizing Model Calls
This is the base layer of the spec. It defines the spans produced when application code calls a GenAI model[10].
Inference
Each LLM call generates a span with gen_ai.operation.name set to chat, text_completion, or generate_content (for multimodal). Span kind is CLIENT, since models typically run on remote services.
Core attributes:
| Attribute | Meaning | Example |
|---|---|---|
gen_ai.provider.name | Provider identifier | openai, anthropic, aws.bedrock |
gen_ai.request.model | Requested model | gpt-4o-mini |
gen_ai.response.model | Actual responding model | gpt-4o-mini-2024-07-18 |
gen_ai.usage.input_tokens | Input token count | 142 |
gen_ai.usage.output_tokens | Output token count | 87 |
gen_ai.response.finish_reasons | Completion reason | ["stop"], ["tool_calls"] |
Here's what this looks like in a trace viewer (Jaeger, Grafana Tempo, etc.):
json
{
"operationName": "chat gpt-4o-mini",
"spanKind": "CLIENT",
"duration": "1.23s",
"attributes": {
"gen_ai.operation.name": "chat",
"gen_ai.provider.name": "openai",
"gen_ai.request.model": "gpt-4o-mini",
"gen_ai.response.model": "gpt-4o-mini-2024-07-18",
"gen_ai.usage.input_tokens": 142,
"gen_ai.usage.output_tokens": 87,
"gen_ai.response.finish_reasons": ["stop"],
"server.address": "api.openai.com",
"server.port": 443
}
}Note: This is a logical view for readability. The actual OTLP wire format uses
KeyValuearrays with typed values (stringValue,intValue, etc.) and nanosecond Unix timestamps.
server.address and server.port are general networking attributes. They're not part of the GenAI spec, but instrumentation typically emits them anyway.
provider.name and request.model are intentionally separate. The same model name can be accessed through different providers (Azure OpenAI and OpenAI direct both serve GPT-4o), and provider.name determines which provider-specific attributes apply.
request.model vs response.model matters in practice too: you request gpt-4o, but the response might come from gpt-4o-2024-08-06. For fine-tuned models, response.model should be more specific than the base name.
Embeddings and Retrievals
Embeddings (gen_ai.operation.name=embeddings) cover vector embedding operations, with gen_ai.embeddings.dimension.count recording the vector dimension. Retrievals cover the retrieval step in RAG pipelines.
One-Line Integration
With Python + OpenAI SDK, instrumentation takes one line[11]:
python
from opentelemetry.instrumentation.openai_v2 import OpenAIInstrumentor
OpenAIInstrumentor().instrument()
# OpenAI SDK calls will emit semconv-compliant spans and metrics.
# Prompt/completion events require content capture to be enabled explicitly.
client.chat.completions.create(model="gpt-4o-mini", messages=[...])opentelemetry-instrumentation-openai-v2 is the most mature GenAI instrumentation. Anthropic, AWS Bedrock, and others are covered by community libraries.
Layer 2: Agent & Workflow Spans — Beyond Microservices
This is where GenAI semantic conventions diverge most from traditional OTel. Distributed tracing has HTTP spans, RPC spans, and DB spans, but nothing for "agent invocation." The GenAI spec introduces a new set of operation types[12].
create_agent
Describes agent creation, typically for remote agent services (OpenAI Assistants API, AWS Bedrock Agents). Span kind is CLIENT.
Span: create_agent support-router
Kind: CLIENT
Attributes:
gen_ai.operation.name = create_agent
gen_ai.agent.name = support-router
gen_ai.provider.name = openaiinvoke_agent
Invokes an agent to perform a task. v1.41 explicitly splits two scenarios[8:1]: CLIENT for remote calls, INTERNAL for local framework execution (e.g. LangGraph running agent logic in-process).
invoke_workflow
Describes execution of a predefined workflow (added in v1.41[8:2]). Agents reason autonomously; workflows follow predetermined paths.
execute_tool
Tool execution span, kind INTERNAL. Starting with v1.41, the tool name must appear in the span name (execute_tool {gen_ai.tool.name})[8:3]. gen_ai.tool.call.arguments and gen_ai.tool.call.result are recorded only when privacy policies permit.
Why These Span Types Matter
Our Agent Observability article discussed a core challenge: the agent's reasoning process shows up as a black box in traces. Agent span conventions crack that open:
invoke_agent research-assistant (INTERNAL)
├── chat gpt-4o (CLIENT) ← Model decides to search
├── execute_tool web_search (INTERNAL) ← Search executed
├── chat gpt-4o (CLIENT) ← Continues reasoning with results
├── execute_tool summarize (INTERNAL) ← Summarization
└── chat gpt-4o (CLIENT) ← Generates final answerEvery step carries standardized attributes, and any compatible backend (Jaeger, Tempo, Datadog) can render the structure correctly.
Layer 3: MCP Semantic Conventions — Fixing Broken Traces
Model Context Protocol (MCP) spread fast in 2025, but brought an observability problem: traces from the agent side and the MCP server side are disconnected.
Glama's analysis laid it out clearly[13]: the agent produces Trace A, the MCP server produces Trace B, no context propagation between them. The OTel MCP semantic conventions, introduced in v1.39[6:1], fix this[14].
Core Design
MCP runs on JSON-RPC, but the spec recommends MCP conventions over generic RPC semantic conventions. MCP spans carry context that generic RPC conventions miss, such as session and tool call details.
Client span example (stdio transport):
Span: tools/call get-weather
Kind: CLIENT
Attributes:
gen_ai.operation.name = execute_tool
mcp.method.name = tools/call
mcp.session.id = session-xyz
mcp.protocol.version = 2025-03-26
gen_ai.tool.name = get-weather
jsonrpc.request.id = 42
network.transport = pipe # stdio maps to pipeFor HTTP transport, use network.transport = tcp (or quic) with network.protocol.name = http[14:1].
When both sides propagate W3C Trace Context, the server span nests under the client span, and trace continuity is preserved across the protocol boundary.
Compatibility with execute_tool
The spec handles deduplication: if MCP instrumentation detects that an outer GenAI instrumentation already tracks tool execution, it enriches the existing span with MCP-specific attributes (mcp.method.name, mcp.session.id, etc.) instead of creating a duplicate.
A complete agent + MCP call chain[14:2]:
invoke_agent weather-forecast-agent (INTERNAL)
├── chat {model} (CLIENT) ← GenAI model
├── tools/call get-weather (CLIENT) ← MCP client
│ └── tools/call get-weather (SERVER) ← MCP server
└── chat {model} (CLIENT) ← GenAI modelMCP-Specific Metrics
Four MCP metrics: mcp.client.operation.duration / mcp.server.operation.duration (operation latency) and mcp.client.session.duration / mcp.server.session.duration (session lifetime).
Layer 4: Events and Content Capture — Balancing Privacy and Observability
Traditional OTel HTTP spans rarely need to worry about "should we record the request body?" LLM applications are different: prompt and completion content is both the most valuable debugging data and the most sensitive.
Two Core Events
gen_ai.client.inference.operation.details (added in v1.37)[15]: records full input and output for a GenAI call. It's opt-in, and backends can process it as events/logs, decoupled from trace lifecycle and storage policies.
gen_ai.evaluation.result: records quality evaluation results via gen_ai.evaluation.score.value and gen_ai.evaluation.score.label[15:1]. A relevancy evaluator might return score.value=0.85, score.label="relevant".
Here's the operation.details event with content capture enabled:
json
{
"eventName": "gen_ai.client.inference.operation.details",
"attributes": {
"gen_ai.system_instructions": [
{"type": "text", "content": "You are a helpful customer support agent."}
],
"gen_ai.input.messages": [
{
"role": "user",
"parts": [{"type": "text", "content": "Where is my order #12345?"}]
}
],
"gen_ai.output.messages": [
{
"role": "assistant",
"parts": [{"type": "text", "content": "Your order #12345 shipped this morning and should arrive tomorrow."}],
"finish_reason": "stop"
}
]
}
}When recorded on the operation.details event, messages follow the spec's JSON schema in structured form[15:2]. On span attributes, where backends lack structured attribute support, serialized JSON strings work too.
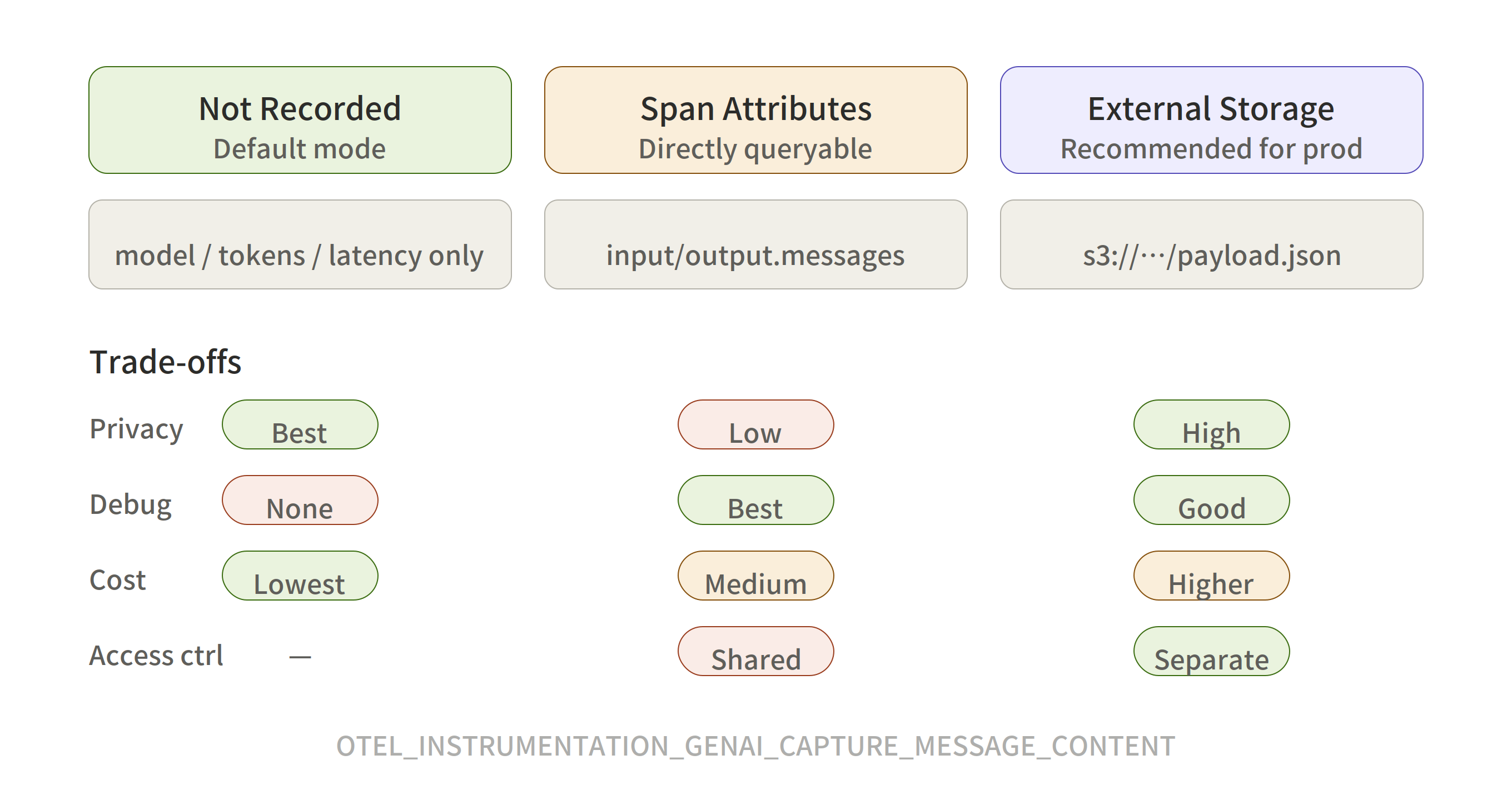
Content is absent by default. Many instrumentations gate it behind OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true. In production, most teams end up on mode three: external storage with a reference URL on the span.
Three Content Recording Modes
The spec defines three approaches[10:1]:
Not recorded (default). Content capture is off.
On span attributes. gen_ai.input.messages and gen_ai.output.messages as span attributes. Convenient, but size-limited and visible to anyone with trace access.
External storage + span reference. Full content in external storage (S3, GreptimeDB, etc.), span holds only a reference URL. Independent IAM and retention policies. The spec recommends this for production with significant telemetry volume or sensitive data[10:2].
Layer 5: Metrics — The Two Essential Client Histograms
The GenAI spec defines multiple metrics on both client and server sides. The two most used client histograms[16]:
gen_ai.client.operation.duration
End-to-end latency per GenAI operation, in seconds. Dimensions: gen_ai.operation.name, gen_ai.request.model, gen_ai.provider.name.
gen_ai.client.token.usage
Token consumption per operation, unit {token}. Recommended bucket boundaries follow exponential growth: [1, 4, 16, 64, 256, 1024, 4096, 16384, 65536, 262144, 1048576, 4194304, 16777216, 67108864], covering 1 token to 67M tokens.
Two counting rules worth knowing. When a provider reports both used and billable tokens, the instrumentation should report the billable count. When token counts can't be obtained efficiently, the instrumentation should omit them rather than guess.
These two metrics answer most operational questions: which model is most expensive, where latency is worst, how token consumption is trending. In our GenAI demo, they're written to GreptimeDB via OTLP and queried with PromQL:
promql
# p95 token consumption
histogram_quantile(0.95,
sum(rate(gen_ai_client_token_usage_bucket[5m])) by (le, gen_ai_token_type)
)Layer 6: Provider-Specific Conventions — From Generic to Specialized
Generic GenAI attributes cover common ground. Each provider has unique capabilities, handled through provider-specific conventions.
OpenAI
OpenAI has the most detailed provider convention so far[17]. With gen_ai.provider.name set to openai, the spec adds:
gen_ai.usage.cache_read.input_tokens: tokens read from the provider's cachegen_ai.usage.cache_creation.input_tokens: tokens written to the provider's cachegen_ai.usage.reasoning.output_tokens: tokens consumed during reasoning (o1/o3 series, added in v1.41[8:4])
Cached input is typically cheaper than regular input (exact discounts vary by model). Reasoning tokens are an additional cost specific to reasoning models.
Anthropic, AWS Bedrock, Azure AI Inference
Anthropic (gen_ai.provider.name=anthropic) includes a calculation guide for gen_ai.usage.input_tokens[7:1], because its billing model differs from OpenAI's. AWS Bedrock (aws.bedrock) and Azure AI Inference (azure.ai.inference) extend platform-specific attributes.
Design principle: gen_ai.provider.name is the discriminator. It determines which provider-specific attributes should appear. An OpenAI span shouldn't carry aws.bedrock.* attributes, and vice versa.
A Complete Trace
Combining all six layers, here's what a full trace looks like when an agent calls an external tool via MCP:
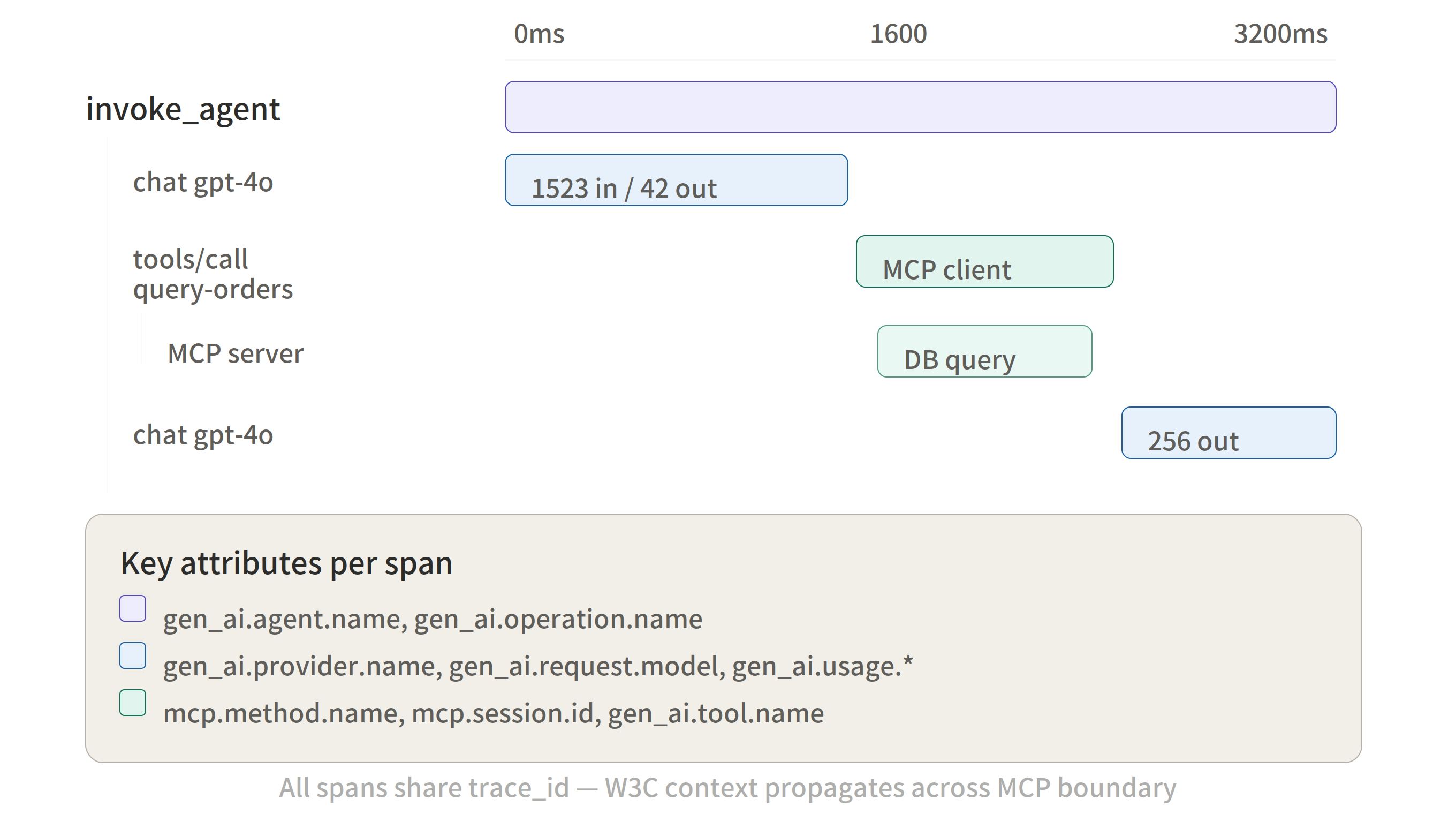
invoke_agent support-router (INTERNAL, trace=t1)
│
├── chat gpt-4o (CLIENT)
│ gen_ai.provider.name = openai
│ gen_ai.request.model = gpt-4o
│ gen_ai.usage.input_tokens = 1523
│ gen_ai.usage.output_tokens = 42
│ gen_ai.response.finish_reasons = ["tool_calls"]
│
├── tools/call query-orders (CLIENT) ← MCP client
│ mcp.method.name = tools/call
│ mcp.session.id = sess-abc
│ gen_ai.tool.name = query-orders
│ │
│ └── tools/call query-orders (SERVER) ← MCP server
│
└── chat gpt-4o (CLIENT)
gen_ai.usage.input_tokens = 2841
gen_ai.usage.output_tokens = 256
gen_ai.usage.cache_read.input_tokens = 1523 ← OpenAI-specific
gen_ai.response.finish_reasons = ["stop"]
Metrics (same time window):
gen_ai.client.operation.duration{model=gpt-4o}
gen_ai.client.token.usage{model=gpt-4o, token_type=input}
mcp.client.operation.duration{method=tools/call}
Events (opt-in):
gen_ai.client.inference.operation.details → full prompt/completion
gen_ai.evaluation.result → score.value=0.92, score.label="relevant"Note: metrics use Prometheus-style shorthand ({model=...}). Actual attribute names are gen_ai.request.model, gen_ai.token.type, etc., exported to Prometheus as gen_ai_request_model, gen_ai_token_type. Prometheus 3.0 has since added native support for OpenTelemetry naming conventions, so cross-system alignment no longer requires manual conversion.
A single trace_id links the entire chain, from the agent's initial decision through the MCP server's execution to the final response.
Current Status and Adoption
The spec is still in Development status. v1.36 is the transition baseline: existing instrumentations default to the old attribute format, while OTEL_SEMCONV_STABILITY_OPT_IN=gen_ai_latest_experimental switches to the latest version[2:2].
The OpenAI Python SDK instrumentation is the most mature[11:1]. Community libraries like OpenLLMetry[18] cover Anthropic, Cohere, and AWS Bedrock. Framework instrumentations for LangGraph and CrewAI are in progress.
Datadog was one of the first commercial platforms to natively support v1.37+ GenAI semantic conventions[19]. Elastic's 2026 observability report finds that 85% of organizations use some form of GenAI for observability, and 89% of OTel production users rate vendor compliance as "critical" or "very important"[20].
We built a full LLM observability stack on this spec in our GenAI demo, with OTLP going straight to GreptimeDB and all three signal types in unified storage:
bash
docker compose --profile load up -d
# Grafana: http://localhost:3000Wrap-Up
The six layers covered above (Client Spans, Agent Spans, MCP conventions, Events, Metrics, and Provider conventions) together span the full observability chain, from the initial model call to agent orchestration to tool execution.
The two pieces worth paying closest attention to today are Agent Spans and MCP conventions. Both are new to OTel, both target concrete problems (black-box agent reasoning and broken MCP traces), and both are likely to set the pattern for how the ecosystem instruments agents going forward. The three-mode design for content capture is the spec's pragmatic answer to a real conflict between privacy and debuggability.
The spec itself is still moving fast. Every release from v1.37 to v1.41 has touched GenAI. For teams building LLM or agent systems, the easiest place to start is the OpenAI Python SDK instrumentation. From there, the spec docs and our demo show how the layers fit together in practice.
References
Semantic Conventions for Generative AI Systems (docs v1.41.0, Development) ↩︎ ↩︎ ↩︎
Glama: OpenTelemetry for MCP Analytics and Agent Observability ↩︎




