On this page
GreptimeDB is an excellent data processing system for you to get value out of time series in real time.
Why Greptime
A few years back, I worked at a major financial technology company where I was asked to build an ultra-large-scale (It supported tens of millions of monitoring indicators, hundreds of thousands of containers, and a microservice call network composed of thousands of applications.) monitoring solution. After researching popular solutions like InfluxDB, Prometheus, and more, I found that there was no open-source solution in sight that met our needs (those needs have now spread all over):
- Process massive, high-cardinality time series data points at a reasonable cost
- Handle at least 100K queries and 500M data points per second in real-time
- Meet various high requirements for data analytics
To tackle those issues, me and my team have built an ultra-large-scale data processing system specifically for time series over the past few years. We managed to write hundreds of millions of data points per second uninterruptedly, analyze millions of indicators in multi-dimensional and real-time (for alerts, root cause analysis, etc.), and store tens of millions of legacy metrics at a low cost. Meanwhile, we provide powerful analysis capabilities of SQL/Python that help data science teams to build AIOps/FinOps and other intelligent applications easily. All the data we process is time series data.
As IoT sensors generates enormous amounts of data, it occurs to me how time series data can help us build a much better society, and its value is understated. You are now, in fact, benefiting from time series data. Take the growing number of connected cars, for example. Based on the data we have aggregated, science teams can build technology in our vehicles. We could identify telltale signs that best predict that a car accident is going to take place in the next five seconds and and save a passenger's life because it can identify when he/she is losing attention at the moment. Our job is to ensure users can use the devices and the data more reliably and efficiently. We help people and technology make critical decisions more accessible and quicker, so we emphasize real-time.
We have gone through over ten years of battle testing and backed successful applications. We have faith in delivering to our customers with the engineering capabilities we have gained, the business strengths we have earned, and the resources we have been granted. We want to commit to that vision through open-source and cloud services. So Greptime was born. We use the verb "grep", a frequently used search command in *nix systems, and hope to empower customers to dig deeper into time series data and find hidden value — "Invest in data, Harvest over time".
Limitations for traditional time-series database solutions
If you look at a traditional time series processing system, it often works like this:
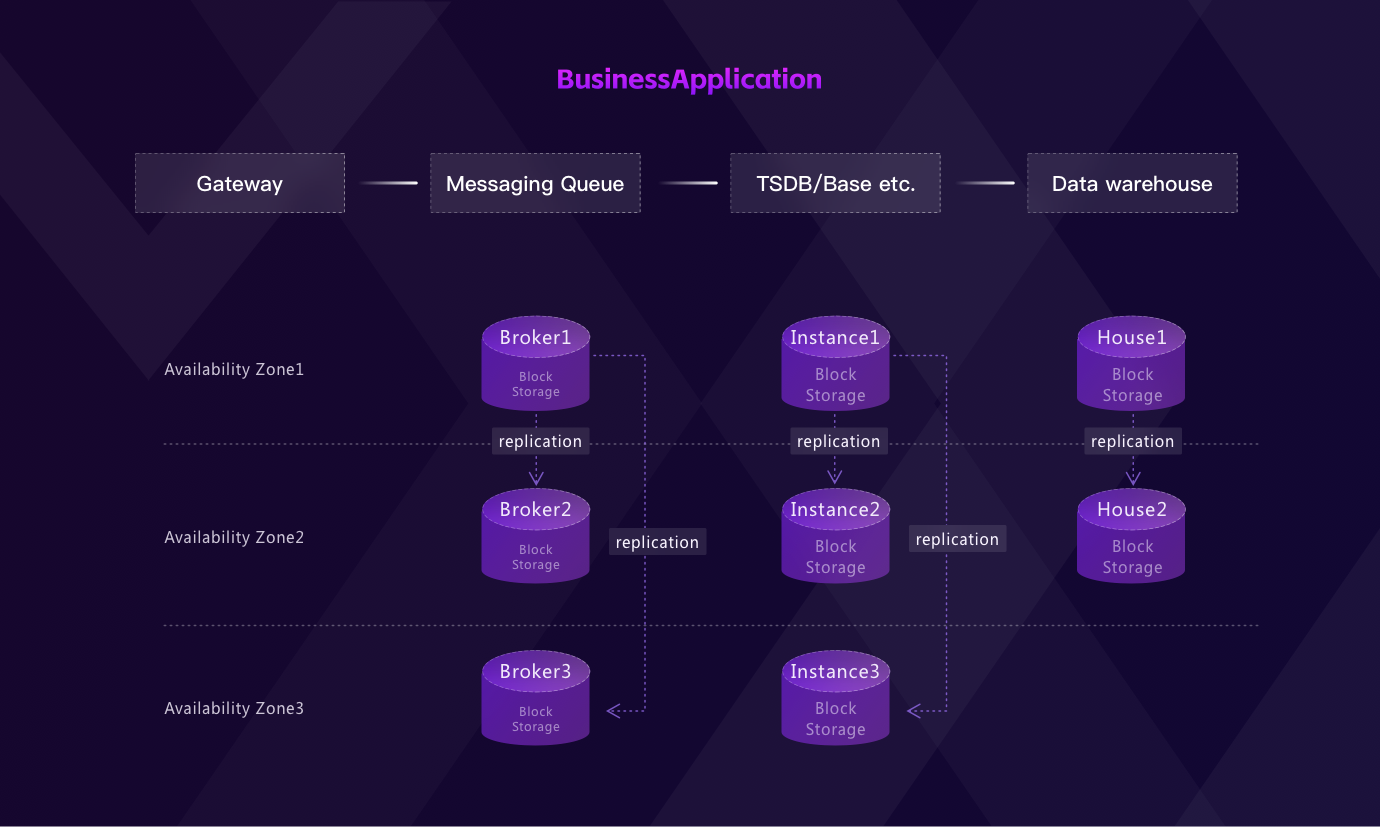
After being collected through the gateway into the system, a stream of data needs to be pre-processed(ELT) in messaging queue services (like Kafka), normalized, and then persisted to time series databases or HBase. To facilitate data analytics (such as BI reports), it has to export a copy of the data to the data warehouse. As it shows:
- There are multiple redundant copies of data.
- To ensure high availability and reliability, a user ends up overprovisioning either storage or compute when deploying message queues, databases, and data warehouses, which means you have to pay triple.
- If you use block storage services like EBS, the storage triples again, and your costs balloon further. In IoT and Observability scenarios, the volume of data is enormous, and the storage cost is even more headache.
- Not to mention the cost of deployment, upgrades, and maintenance of such complex architecture.
With the rise of cloud-native data warehouses like Snowflake, separating storage and compute is proven to allow for cost savings as well as improved performance and elasticity. When shifting data infrastructure into the cloud, we believe it's critical to redesign the services around performance, maintainability, and cost. Use commodity storage such as S3 to replace expensive EBS and serverless containers to provide elastically scalable compute resources. Users pay only for the storage and compute resources they actually use, with no over-provisioning costs brought by additional architectures. Delivering cost-effective, high-performance, reliable cloud services to users has been our goal from day one.
How GreptimeDB differentiate from others
Cloud-native
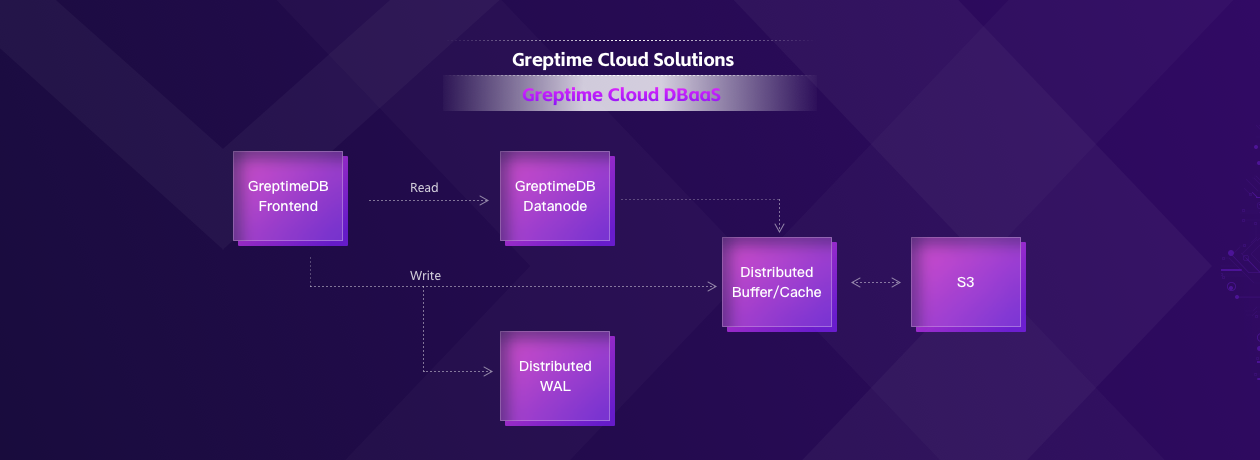
From the ground up, we built GreptimeCloud, a multi-tenant, distributed, and cloud-native real-time processing system for time series data. The picture below shows the basic architecture.
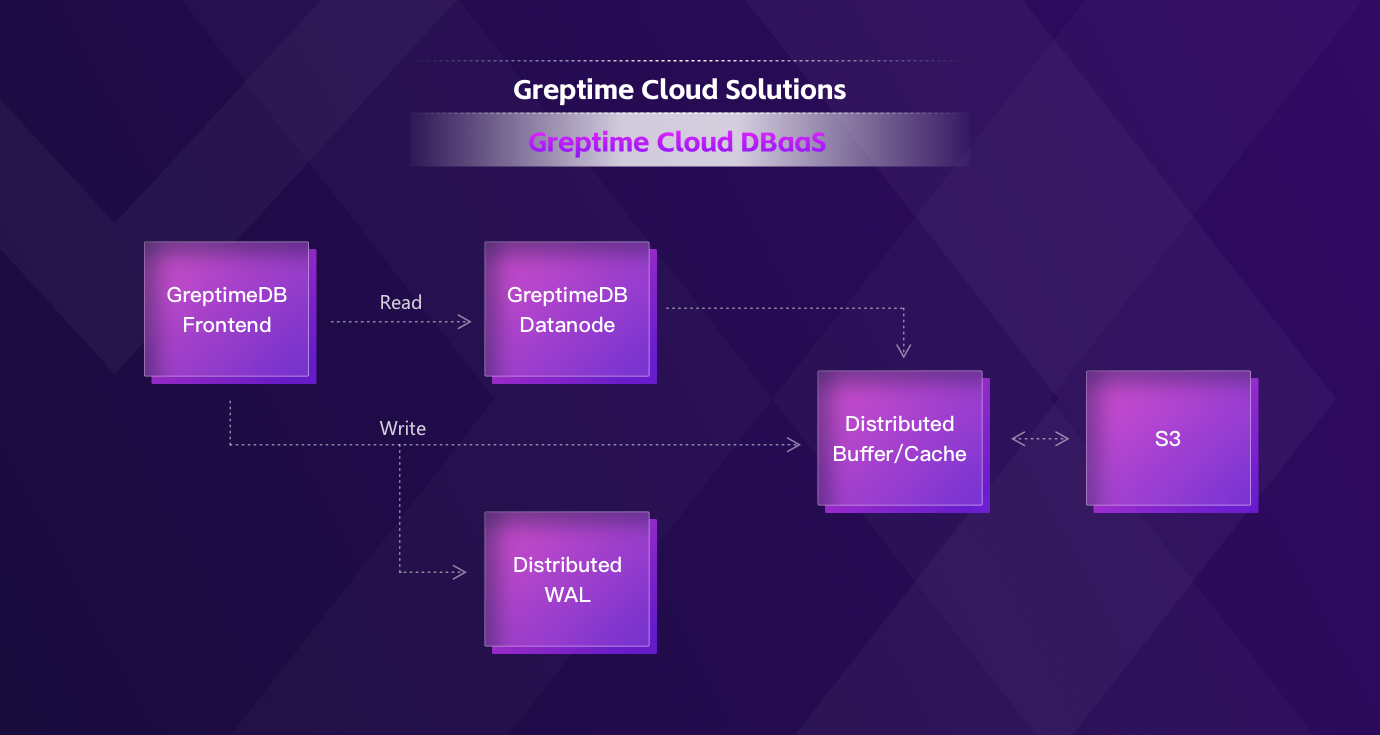
It offers multi-tenant, out-of-the-box, fully managed services, and each user runs a secure and efficient data lifecycle: ingesting, storing, analysis, data management, visualization, anomaly detection, prediction, etc.
GreptimeDB Cloud service mainly consists of three components:
- Frontend: stateless, responsible for gateway protocol and distributed writes and queries;
- Datanode: the work node, stateless, built with time series storage engines and compute engines;
- Distributed WAL: a multi-tenant shared Write-Ahead-Log service used to support fault and disaster tolerance of Datanode.
The data is ultimately stored in cost-effective storage like S3. To address the problem of write throughput and query latency caused by the separation of storage and compute, we also designed a distributed buffer/cache system similar to Page cache in OS.
We provide this hybrid architecture to leverage the benefits of both shared-nothing (frontend, datanode) and shared-disk (wal, cache) architectures:
- Stores "cold" data in S3 and "hot" in the local disk.
- Users can horizontally scale compute nodes as needed.
- User requests will be dynamically scheduled. In case errors occur, the compute node will automatically be moved to another. When there is no traffic in the database, compute resources will be recycled, and users will only pay for what they use.
- The shared distributed WAL only needs a small amount of EBS to provide write disaster tolerance. After the data is flushed to S3, the log can be truncated.
Decoupling storage and compute
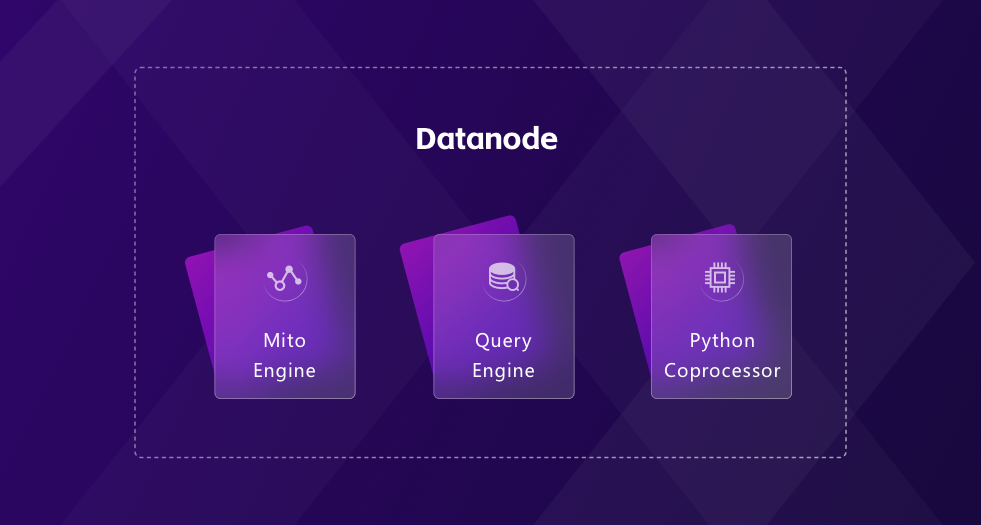
Our architecture decouples storage and compute. Datanode, the core component, has three functions:
- Storage engine: a table engine for time series data based on the LSM tree, called the Mito engine.
- Query engine: SQL supported; it converts SQL to logical/physical plans. With vectorized computation and user-defined functions, GreptimeDB can specifically work with vast amounts of data for many complex computations.
- Python co-processor: to avoid spending lots of time and effort transferring and transforming data, we provide the capability of executing Python scripts in the database. Besides, users can benefit from the robust community of Python.
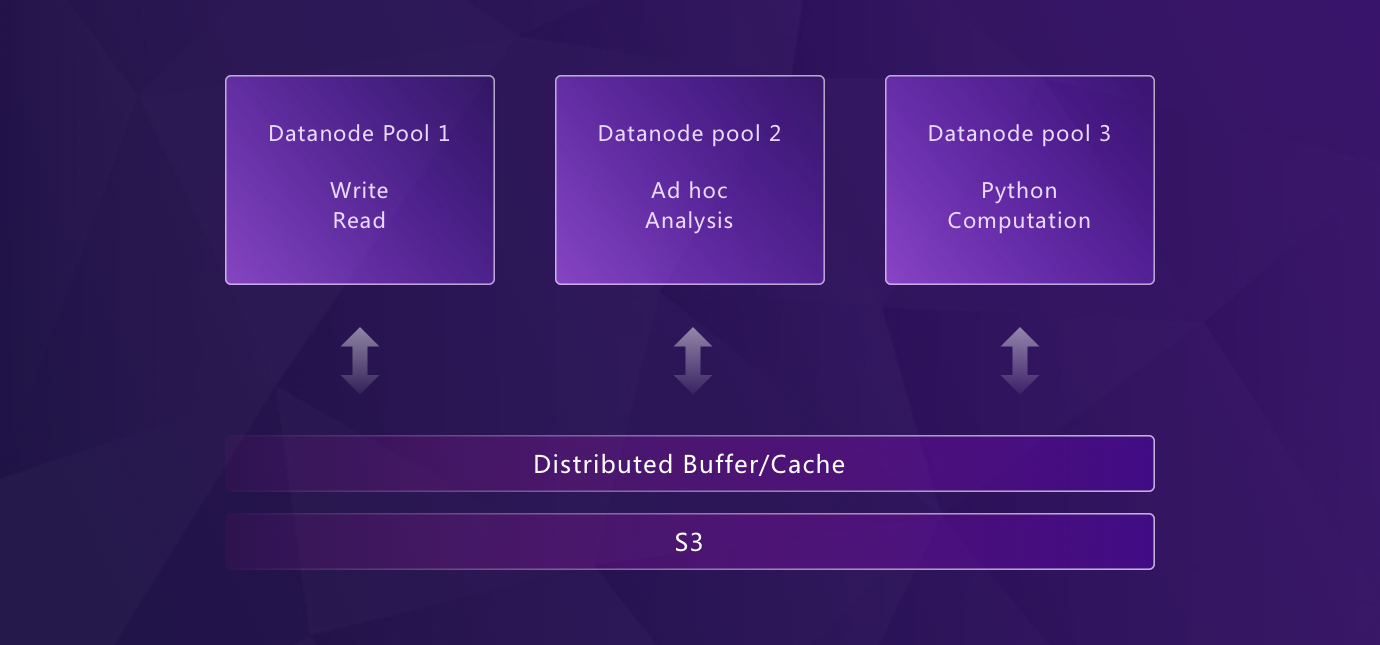
Each function can be started alone as a specific computing pool (we call it Datanode Computation pool), and loads of reads, writes, analysis, and Python computing can be isolated without affecting each other.
See our upcoming posts for more details.
Built in Rust
We have been using Rust to write our time series database since 2018. When it comes to infrastructures like databases, a high level of stability and performance is the top priority. It's better to avoid any Runtime/GC language because they cause inevitable overhead of memory and CPU. Created to ensure high performance similar to C/C++, Rust also emphasizes memory safety. More and more companies, from startups to large corporations, use Rust in production.
As a start-from-scratch TSDB, it has been running stable and efficiently for four years, and Rust is a key player. During years of development, we barely encountered any serious bugs related to memory safety, and there are also fewer other serious bugs thanks to sufficient testing.
Besides, the vibrant community of Rust drives the growth of Rust packages which makes it easier for developers to build things. And we all love Rust, so it's natural to choose Rust as our primary language to create Greptime.
Fully open-sourced
We decided to open source GreptimeDB from the first day. Instead of a stand-alone product, we are open-sourcing a complete distributed solution with high availability, high reliability, and capable of Python co-processing for time series data analysis and processing.
We believe in open source. Most of us have been very active in different communities. For many years we have been users, contributors, and maintainers. We benefit from the community, and it's time to give back.
GreptimeDB kicked off in April 2022, and many of our features are still on their way. We choose Apache 2.0, a more friendly open-source license, and invite you and all the developers to participate. Go ahead and build your own real-time processing system for time series data.
Future Plan for GreptimeDB
Powered by the vibration of the open-source community, we believe GreptimeDB will grow mature rapidly. Sticking to distributed high availability and high reliability, we will further deliver better storage&query engine optimization and compatibility with more open standard protocols.
Next Jan, we are about to release an invite-only beta of GreptimeCloud, which provides database services and an observability solution. Given that we have years of AIOps experience, the observability solution comes with out-of-the-box, automatic, low-cost monitoring services for infrastructure.
Truly appreciate your time. Visit us on the official website and subscribe to our newsletter. Or, catch up on Twitter @Greptime. If you are interested, join our GitHub community.
About me
I'm Dennis, co-founder and CEO of Greptime, and I have 15-year extensive experience in the industry of software development. I worked for some major corporations, including Taobao, LeanCloud, and Ant Group. My expertise includes Message Queues, BaaS, time series data storage, and ultra-large Observability product development.




