On this page
The world has shown that we want a database that can handle huge amounts of read/write requests, powerful and fast analytic workloads, and at a low cost so that we could carefreely store legacy data. Folks are also looking for seamless shifting and scaling because they are holding too much data but receiving too little value from it. They are keen to have better analysis and insights. It's hard, but it's not all impossible.
GreptimeDB has three main features:
- High availability, reliability, and scalability
While guaranteeing high-frequency reads and writes of massive time-series data, the roadmap of GreptimeDB also reflects outstanding scalability. From an embedded stand-alone database (even purely in-memory database) to a traditional large-scale distributed dedicated cloud system to a completed cloud-based Cloud Native version, users can flexibly select appropriate deployment structures depending on their actual situations and seamlessly scale between different versions.
- Built for cloud
To achieve better resource isolation and access control, GreptimeDB builds a multi-tenant system at the bottom layer. It decouples storage and compute, which allows commodity object storage as well as elastic computing scaling. With the whole process encrypted, users' data is entirely safe and controllable. Besides designing this architecture, we are also providing out-of-the-box services including deployment, Ops, managing and controlling systems on the cloud (even multi-cloud), so far as commercialized full management.
- Enhanced analytical ability
Embedded SQL analysis and Script computing ability (especially Python), GreptimeDB empowers complex computing and AI training, reducing delays and, more importantly, lowering the learning, using, and long-term maintenance costs for users.
To achieve these three key goals, GreptimeDB adopts the following design concept and outline.
Architecture Overview
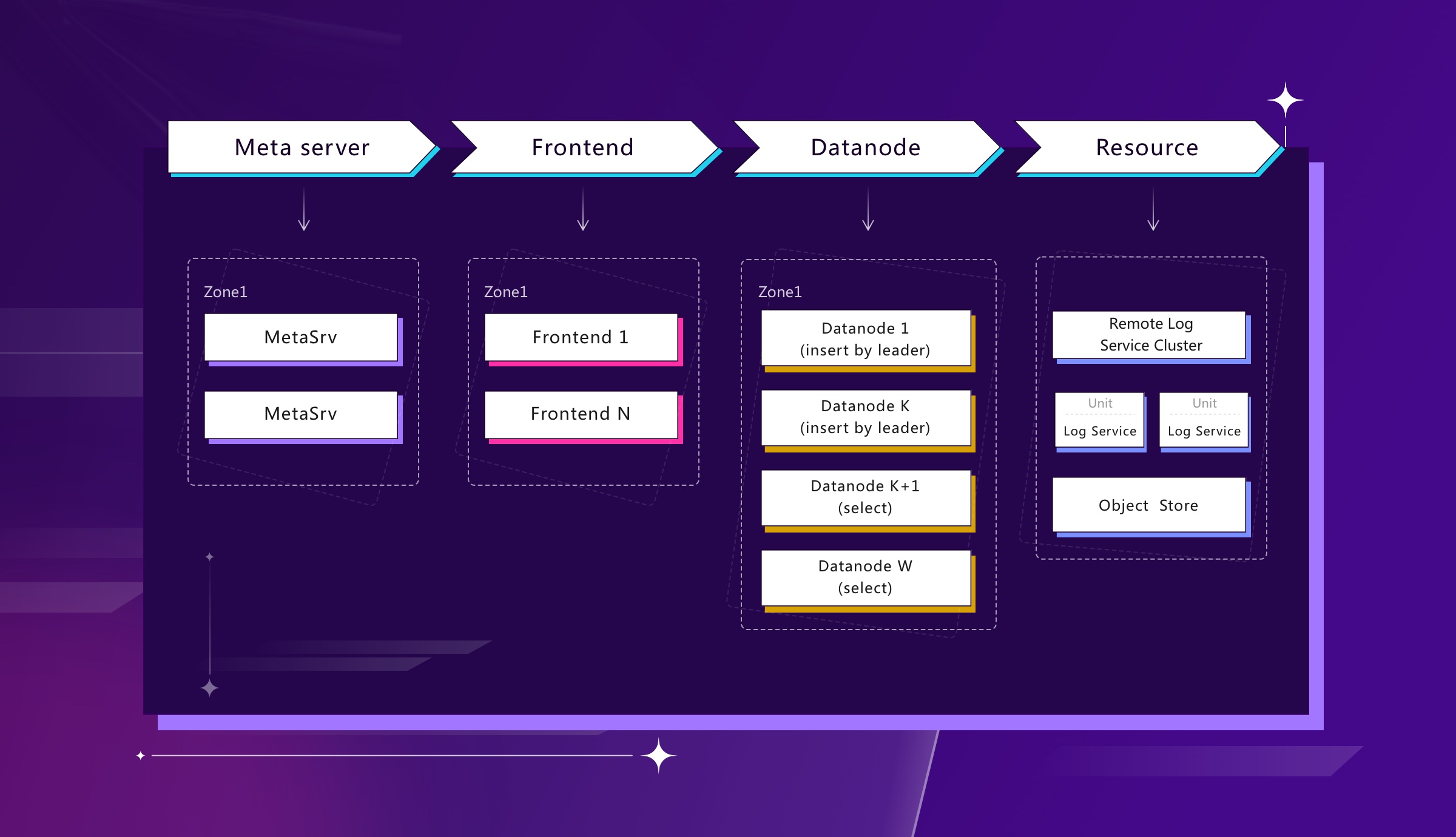
This picture shows the overall architecture of GreptimeDB. 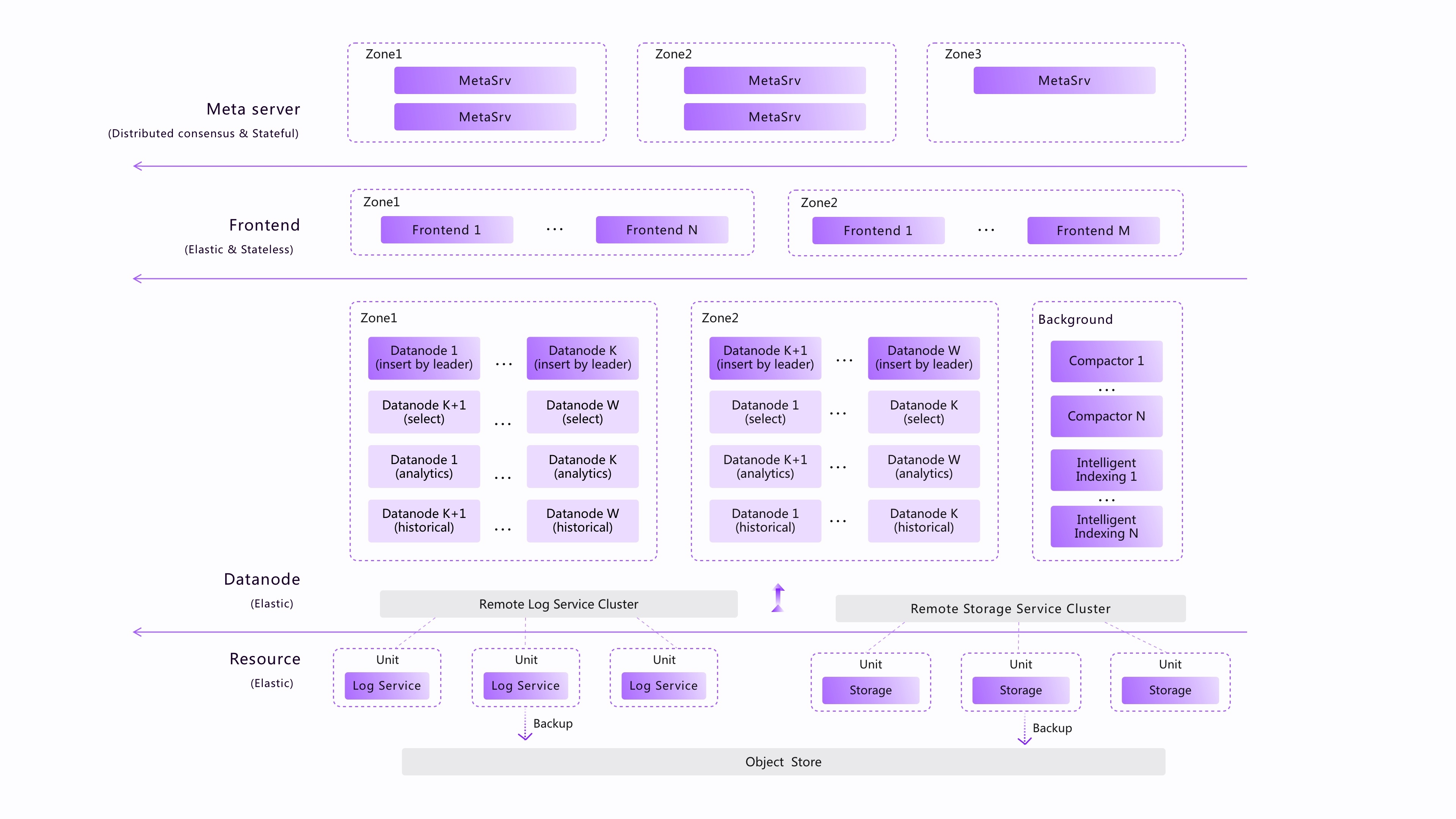
Main components of GreptimeDB:
- MetaServer cluster
The MetaServer cluster stores and manages the metadata of the entire GreptimeDB cluster, including node meta information (IP address, port, role, etc.), address information for tables (region and distribution), meta information for tables (Schema, options, etc.) and status management for clusters (Node status, various global status and global task status, etc.).
The metaserver cluster uses Raft to achieve a robust consensus, and open-source components such as etcd/zookeeper can also be directly used as the backend.
- Frontend cluster
Working as a proxy and a router, the frontend node routes a read and write request to the right backend node according to the location information of the table and load-balancing rules. Also, it undertakes the distributed query function across regions or tables. The Frontend supports data write-in through popular open-sourced protocols, such as MySQL/PostgreSQL/OpenTSDB/InfluxDB/Prometheus and our private gRPC and HTTP RESTful protocols, etc. We support the diversity of writing protocols to the maximum extent, so users can have quick access to GreptimeDB.
As to query, we mainly enable SQL considering that it has a broad crowd among developers and a powerful environment. Users can also use SQL through MySQL/PostgreSQL/RESTful/gRPC and other protocols to query and analyze data in GreptimeDB. We are going to allow PromQL in the future because it has a wider group of users in cloud-native observability.
- Datanode cluster
It's the datanodes that are doing the actual processing of the read/write requests. They manage to hold most of the processes and functions like a time-series engine, a SQL query engine, a Python analysis engine, etc. They are the compute pillars of the architecture to accomplish decoupling storage and compute.
Datanode possesses the capability of reading, writing, analysis, and computing, which can be distributed by their config and roles to different computing power pools: reading nodes, writing nodes, analysis, and computing nodes, etc., facilitating isolation and subdivision of different computing power. The cloud-native version additionally permits elastic scaling as needed.
- Remote storage (at the storage layer of the architecture)
The remote storage has both a remote log service of distributed WAL and a remote storage service for data storage. Using WAL, GreptimeDB achieves high reliability and high efficiency in data writes, and also shapes up high availability solutions and data replication, backup, etc. We have designed a distributed log architecture that grants high-throughput reads and writes, high reliability, and high availability. We will discuss that later in the blog.
The data and logs of GreptimeDB will be stored in ObjectStore (based on the OpenDAL project). It could be a commodity and reliable object storage, like S3, provided by cloud computing vendors, which is cloud native. Or it could be a type of local disk media, which is a typical traditional distributed solution for local disks. We offer both synchronous and asynchronous replication proposals to guarantee high data reliability.
We would like to emphasize that of the above four components, MetaServer and Remote storage are optional deployments, and Frontend and Datanode can be deployed in the same process.

Note: We will further illustrate the cloud-native architecture in the following blogs.
Users can select deployment methods according to their business situations and requirements. We also provide the K8s operator and the command line tool gtctl to help users conveniently operate and manage GreptimeDB clusters in the K8s environment. At the same time, we also plan to provide a fully managed GreptimeCloud service for testing and using GreptimeDB without barriers.
Data model: Time-series table and Schemaless
We design our data model mainly based on the table model in relational databases while also considering the characteristics of time-series data.
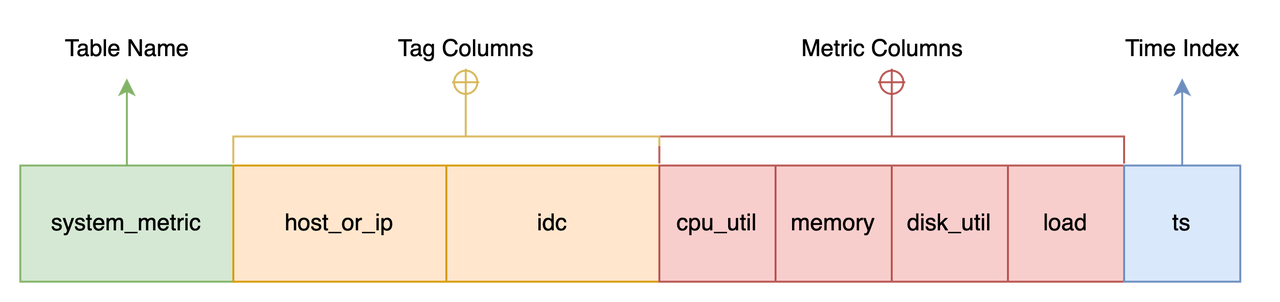
For example, when you want to design a system resource monitoring for a stand-alone device, you can create a table like this:
sql
CREATE TABLE system_metric {
host_or_ip STRING NOT NULL,
idc STRING default 'idc0',
cpu_util DOUBLE,
memory DOUBLE,
disk_util DOUBLE,
load DOUBLE,
ts TIMESTAMP NOT NULL,
TIME INDEX(ts),
PRIMARY KEY(host_or_ip, idc),
};host_or_ip is the hostname or IP address of the collected stand-alone machine. The idc column shows the data center where the machine is located, cpu_util, memory, disk_util, and load are the collected stand-alone indicators, and ts is the time of collection (Unix timestamp).
Those are very similar to the table model everyone is familiar with. The difference lies in the TIME INDEX(ts) constraint, which is used to specify the ts column as the time index column of this table.
We call this kind of table TimeSeries Table, which consists of four parts:
- Table name: often the same as indicator name, such as
system_metrichere. - Time index column: required and normally used to indicate the data generation time in this row. The
tscolumn in the example is the time index column. - Metric Column: data indicators collected, generally change with time, such as the four numerical columns in the example (
cpu_utilandmemory, etc.). The indicators are generally numerical values but may also be other types of data, such as strings, geographic locations, etc. GreptimeDB adopts a multi-value model (a row of data can have multiple metric columns), rather than the single-value model adopted by OpenTSDB and Prometheus. - Tag Column: labels attached to the collected indicators, such as the
host_or_ipandidccolumns in the example, generally to describe a particular characteristic of these indicators.
GreptimeDB is designed on top of Table for the following reasons:
- The Table model has a broad group of users and it's easy to learn. We just introduced the concept of time index to the time series, which will be used to guide the organization, compression, and expiration management of data.
- Schema is meta-data to describe data characteristics, and it's more convenient for users to manage and maintain. By introducing the concept of schema version, we can better manage data compatibility.
- Schema brings enormous benefits for optimizing storage and computing with its information like types, lengths, etc., on which we could conduct targeted optimizations.
- When we have the Table model, it's natural for us to introduce SQL and use it to process association analysis and aggregation queries between various index tables, offsetting the learning and use costs for users.
Nevertheless, our definition of Schema is not mandatory, but more towards the Schemaless way like MongoDB. GreptimeDB can dynamically create tables when writing data, and can dynamically add columns (for both metric columns and tag columns). Compatible with the data model of open source protocols such as Prometheus/OpenTSDB/InfluxDB, GreptimeDB will convert data under those protocols to time series, creating tables and adding columns automatically (single value models are mapped to greptime_value columns by default).
When you see a good database, before making the shifting decision, you must be curious about how it stores stuff. So in our upcoming post, we will cover how GreptimeDB gives high performance through its storage engines. Stay tuned.




