
On this page
Preface
To respond to a query request, a database typically needs to retrieve rows of data from the storage engine that meet the query criteria. Without optimization, the execution method often scans all files to find the matching data rows.
This approach is highly inefficient. To improve query speed, developers usually optimize system performance from two perspectives: reducing the query workload, such as minimizing the number of files and rows that need to be scanned, and enhancing computational power, such as implementing multitasking parallel processing or increasing machine processing capabilities.
This article delves into the indexing techniques in the GreptimeDB database, specifically designed for large-scale time-series data, and their key role in improving query performance. It focuses on how GreptimeDB uses MinMax indexes and the newly introduced Inverted Indexes in version 0.7 to reduce the query workload, thereby enhancing query performance.
Data Storage Structure
First, we need to understand the basic structure of data storage in GreptimeDB. The storage engine of GreptimeDB divides the time-series data belonging to the same Region into multiple files. Each file can store millions to billions of rows of time-series data, with rows consisting of Tag columns, Timestamp columns, and Field columns. Within a file, data rows are first sorted by the Tag columns and then by the Timestamp column. The Tag columns and Timestamp columns may overlap across different files.
TIP
Region: In GreptimeDB, users can partition a data table into multiple partitions using the CREATE TABLE statement. Each partition is assigned to an individual Region.

MinMax Index: A Simple and Efficient Data Exclusion Strategy
The MinMax index is based on a simple principle: it records the maximum and minimum values for each data set. When query conditions exceed these extreme values, the data set can be directly excluded, avoiding unnecessary scans.
In GreptimeDB's storage structure, MinMax indexes are applied at two levels: the Region level, where the minimum and maximum values of the Timestamp column for each file are recorded, and the file level, where the minimum and maximum values of all columns within each Row Group are recorded.
TIP
Row Group: In GreptimeDB, data files are divided into structural units called Row Groups, with each Row Group containing 102,400 rows.
When a query condition includes specific requirements for the Timestamp, the Region-level MinMax index can effectively exclude files that do not meet the time conditions. During file scanning, the file-level MinMax index can quickly identify and skip Row Groups that do not meet the conditions, significantly reducing the number of data rows that need further inspection. This strategy has proven effective in practice for most time-series data queries, especially when the Tag columns are appropriately arranged, showing excellent filtering performance for queries on the first Tag column and the Timestamp column.
However, the MinMax index has some limitations:
Coarse Filtering Granularity: Even if only a few data rows meet the query conditions, the storage engine still needs to read the entire Row Group, meaning 102,400 rows need to be processed. Reducing the capacity of Row Groups can refine the filtering granularity, improving this situation, but this approach increases the number of Row Groups, putting additional pressure on metadata management.
Limited Index Filtering Capability: The MinMax index mainly optimizes the first column in sorted data rows. From the second column onward, the column values become increasingly irregular, and the filtering effect of the MinMax index diminishes.
To address these issues, GreptimeDB introduced a new indexing structure in version 0.7— the Inverted Index, to complement the MinMax index.
Inverted Index: Precise Positioning and Efficient Filtering
Read the design document at https://github.com/GreptimeTeam/greptimedb/blob/main/docs/rfcs/2023-11-03-inverted-index.md
By adopting Inverted Indexes, GreptimeDB's storage engine has made significant progress in reducing the workload of table scans, especially in specific query scenarios, where query performance can sometimes improve by several folds. The advantages of the Inverted Index are mainly reflected in two aspects:
More Precise Index Information: The Inverted Index records the distribution position of each Tag column value within the file.
Finer Filtering Granularity: The Inverted Index's distribution unit is a smaller Segment, with a default size of only 1,024 rows.
Compared to the MinMax Index, the Inverted Index provides finer granularity and higher precision data filtering capabilities.
Performance Comparison
This section compares the performance of three states: No Index, MinMax Index, and Inverted Index, focusing on the TSBS single-groupby-5-8-1 scenario. The following chart shows the differences in scan row numbers, the number of scanned Row Groups, and average response times for different indexing strategies.
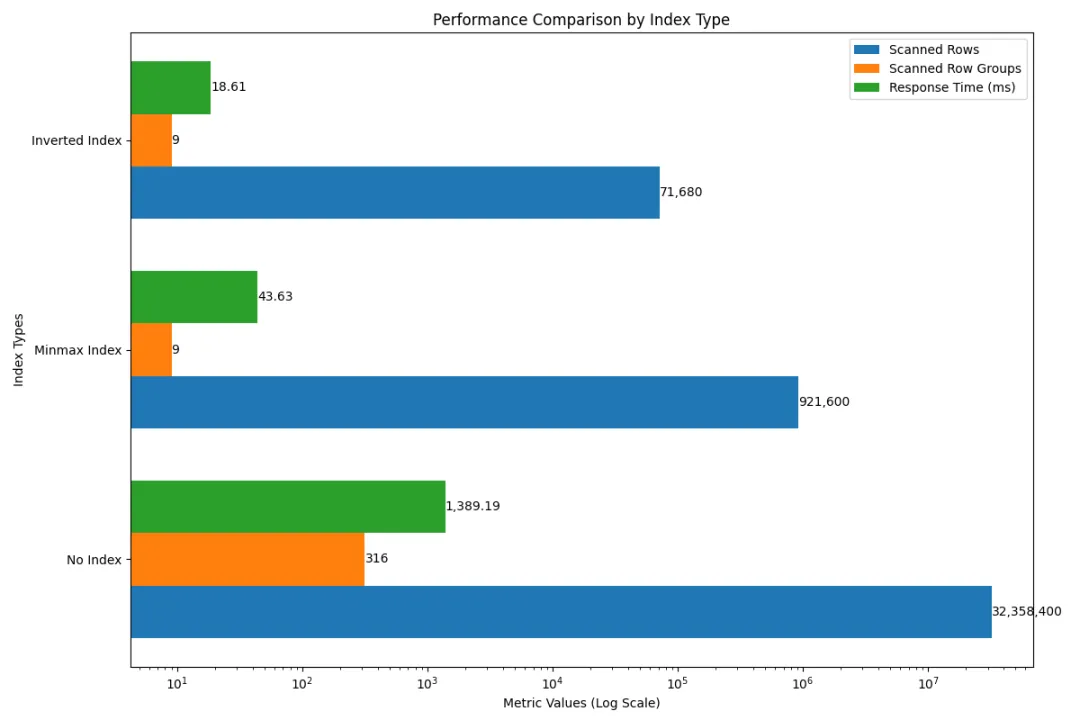
Through this chart, we can clearly see the performance differences between the various indexing strategies, with the Inverted Index performing the best.
Detailed Implementation of the Inverted Index
Specifically, GreptimeDB's Inverted Index is built at the file level. It constructs separate indexes for each Tag column in the file, allowing efficient handling of queries on any Tag column. Compared to the MinMax index, which shows significant filtering effects only on the first Tag column, the Inverted Index significantly expands the scope of applicable indexes. Additionally, the Inverted Index employs the Finite State Transducer (FST) technology, an efficient data structure for mapping keys to values, widely used in index construction for rapid data retrieval. FST supports various operations such as point queries, range queries, regular expression searches, and fuzzy searches, making the Inverted Index powerful in handling complex queries and demonstrating significant performance advantages in various query scenarios.
Unlike the MinMax index, which uses Row Groups as the filtering unit, the Inverted Index adopts adjustable-sized Segments. The choice of index granularity directly affects the filtering effect and index storage cost. To control the index storage cost, GreptimeDB sets the Segment size to 1,024 rows, which is one percent of a Row Group, making the query performance of the Inverted Index superior to the MinMax index in most cases.
In practical implementation, the storage engine constructs mappings from Tag column values to Segment number lists for each Tag column in the data file. These mappings use the FST data structure, with column values as keys and Segment number lists stored as bitmaps as values. During query execution, the storage engine searches the FST through query conditions to obtain the Segment number list and then reads only the corresponding Segments, significantly reducing the amount of data that needs to be scanned.
Future Prospects
Composite Indexes
To improve the performance of multi-column queries, GreptimeDB will explore composite Inverted Indexes. These indexes combine the values of multiple Tag columns into a composite key, providing more precise data filtering. Although this increases the cost of construction and storage, building indexes on demand, i.e., only creating indexes for frequently used column combinations, can effectively control resource consumption.
Full-Text Indexing
GreptimeDB plans to introduce full-text indexing for specific columns to provide query capabilities for log scenarios. Users will be able to perform keyword-based searches to quickly locate specific entries in the logs.
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




