On this page
Why do you need a TSDB inside a car?
As automotive intelligence progresses, vehicles generate increasing amounts of time-series data from various sources. This leads to high costs in data collection, transmission, and storage. GreptimeDB's Integrated Vehicle-Cloud Solution addresses these issues by leveraging the advanced computational capabilities of modern on-vehicle devices. Unlike traditional vehicle-cloud coordination where vehicles are mere data collectors, this new approach treats them as full-fledged servers capable of running complex tasks locally. The evolution from 32-bit MCUs to powerful chip modules like Qualcomm’s 8155 or 8295 has enabled intelligent vehicles to perform edge computing efficiently, reducing transmission costs and improving overall efficiency.
The challenges and how GreptimeDB solved them
GreptimeDB is a cloud-native time-series database built on a highly scalable foundation. However, we did not initially anticipate it running on edge devices such as vehicles, which has presented significant challenges.
The first challenge is resource usage constraints. GreptimeDB runs in the vehicle's cockpit domain controller and must minimize CPU and memory usage to avoid interfering with infotainment systems.
The second concern is robustness; GreptimeDB collects critical diagnostic metrics from the CAN bus, so any crashes could result in data loss.
Lastly, unlike servers in datacenters, vehicle-based GreptimeDB operates under various conditions—frequent power cycles, fluctuating ADAS data rates due to changing road traffic, etc.—and needs to adapt while remaining stable and efficient.
In the following sections, we will detail the challenges we encountered and how we addressed them.
CPU usage
Like other databases running on data centers, GreptimeDB tends to occupy as much CPU resource as necessary when required-this is also a key metric for assessing the scalability of a database. However, things are a bit different in cars. The Human-Machine interface (HMl) on cars not only performs essential data collection tasks but also provides infotainment functions to passengers. Therefore, we need to limit the CPU resources consumed by the on-vehicle database to avoid impacting other processes.
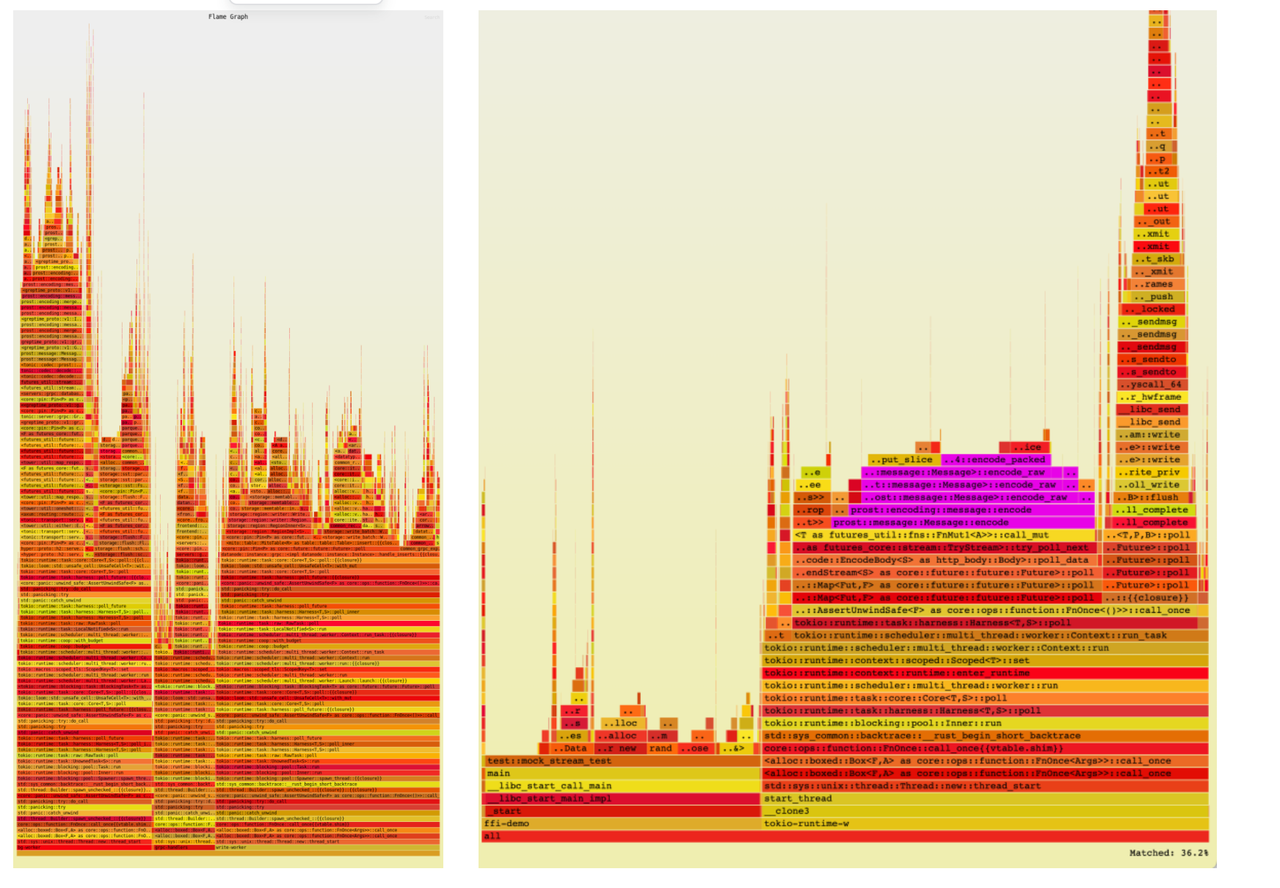
Since #1694, GretpimeDB offers a convenient tool for recording and analyzing CPU usage. During continuous data ingestion, it captures the CPU cycles spent on various tasks and generates a flamegraph illustrating the CPU usage of each component, as shown below.
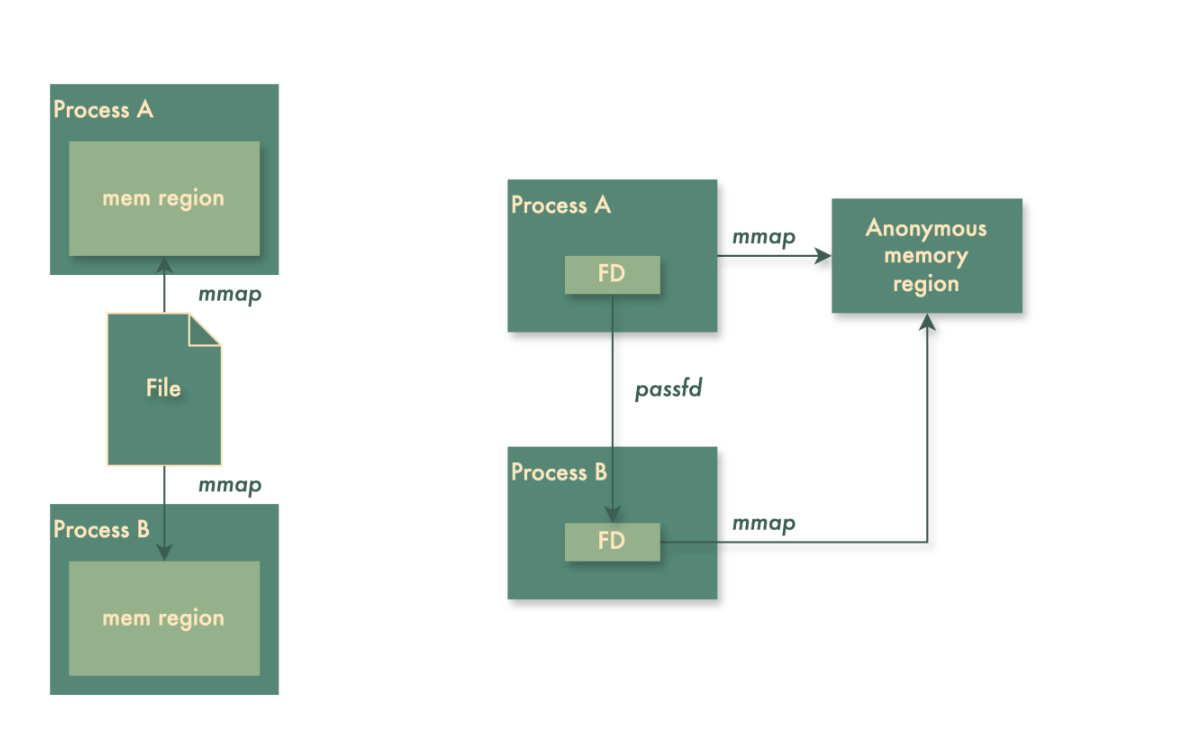
Proprietary SDK based on shared memory lPC
The above graphs show that protocol encoding/decoding consumes about 30% of CPU cycles on the database side and around 36% on the SDK side. Optimizing protocol handling will significantly reduce average CPU usage. Currently, the open-source GreptimeDB SDK uses gRPC as its protocol. While gRPC is fast and user-friendly, its codec overhead becomes significant with large volumes of data ingestion, especially when dealing with nested message structures.
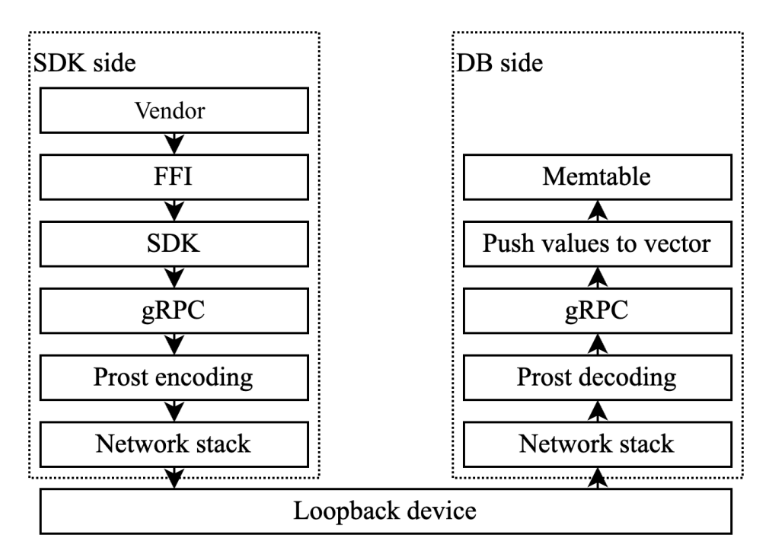
Since the SDK and GreptimeDB instance are on the same host, we chose shared memory (shm) to bypass the kernel network stack and used Arrow IPC format for inter-process communication. Data rows submitted to the SDK are first buffered in Arrow arrays, then encoded into a memory region shared between the SDK and database. The SDK then notifies the database to read and decode this data region. The picture below shows the data flow in shared memory solution.
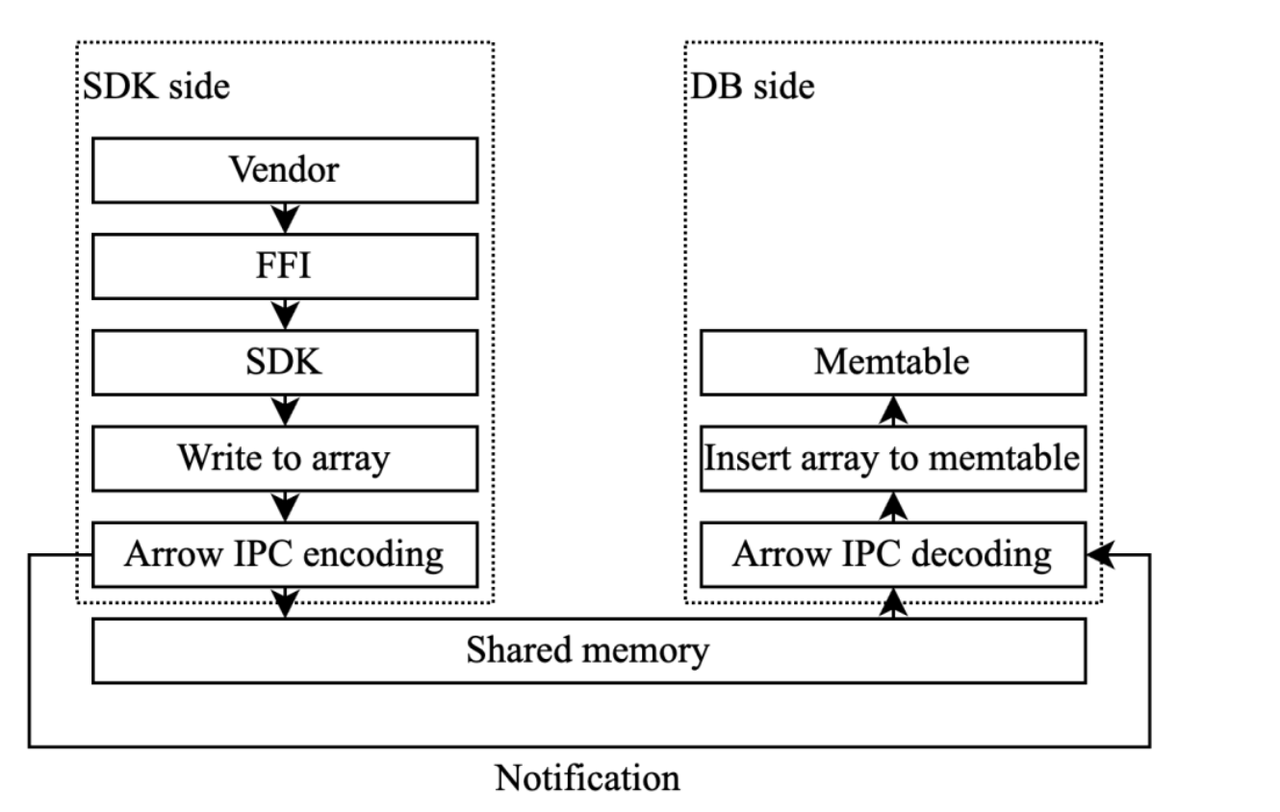
To efficiently use the shared memory region, we designed a circular buffer. Encoded data must be written in a continuous memory area, similar to buffers used in Direct Memory Access (DMA). Therefore, the circular buffer must ensure that bytes are not split when the write offset reaches the end of the memory region.
Smooth flush and compaction
Like other LSM tree-based databases, GreptimeDB schedules periodic flush and compaction tasks in addition to handling data writes. These background tasks can cause CPU spikes due to their encoding and compression processes. Therefore, it is crucial to limit these activities.
GreptimeDB allows different compression and encoding algorithms for various columns. Based on our field experience and benchmarks with diverse data patterns, we have selected specific algorithms for each sensor's data to balance compression rates and CPU usage.
Controlling the timing of background tasks is also important. If all tasks run simultaneously, they can cause CPU spikes that lead to noticeable lags in infotainment operations for passengers. In GreptimeDB, flush and compaction tasks run in a dedicated runtime. By properly configuring the number of threads and the yielding strategy within this runtime, we can maintain low CPU consumption while meeting performance requirements for data writes.
Currently, these limitations are soft constraints; during periods of extremely high write traffic, CPU spikes may still occur. To address this comprehensively, we have initiated a research program under the OSPP (Open Source Promotion Plan) activity to explore mechanisms similar to cgroups for imposing hard constraints on GreptimeDB's resource consumption. This aims to fully resolve such issues.
In benchmarks on production grade Qualcomm 8295 modules, vehicle side GreptimeDB can ingest 600K of data points per second which less than 8% of CPU usage and 300MB of memory, without data loss or out-of-order.
Memory usage
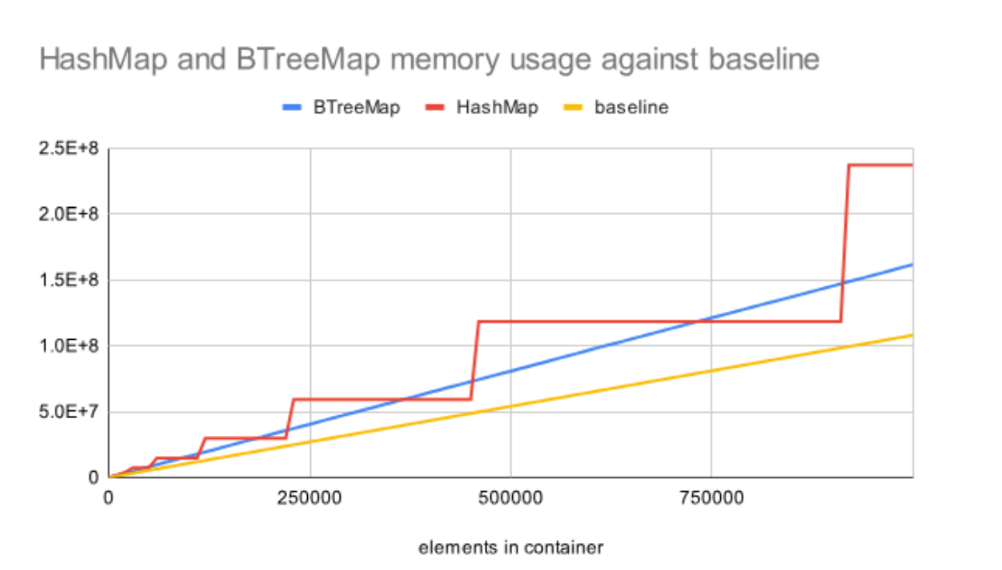
Similar to CPU profiling, GreptimeDB offers a memory profiling tool. For more details, check out our blog. If you're familiar with LSM trees, it's easy to guess that the memtable consumes most of the memory, and the profiling results confirm this. Although GreptimeDB provides a global_write_buffer_size parameter to control memory usage, the default BTree memtable's overhead often causes memory usage to exceed the threshold. The image below from Nicole's blog illustrates the overhead of different collections in Rust.
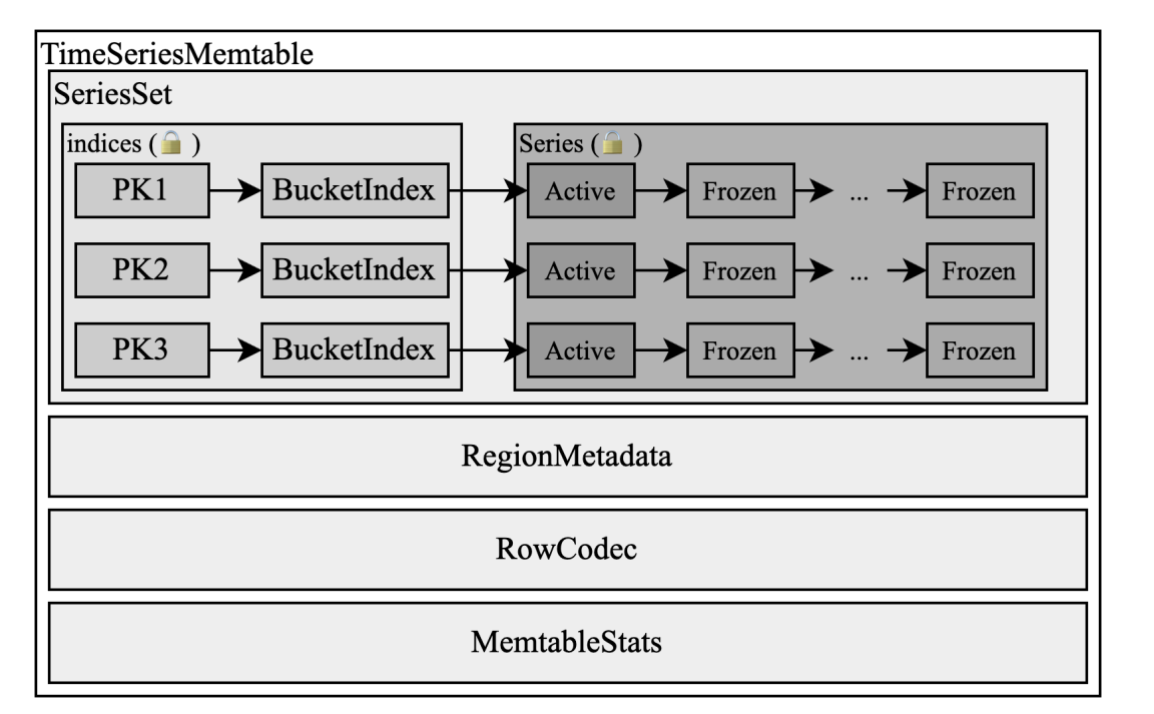
GreptimeDB is currently in rapid development, and its primary memory buffer component, the memtable, has undergone multiple iterations. In subsequent iterations, we resolved the memory bloat issue by introducing the time series memtable, and provided extremely high write performance under workloads with a low data cardinality. The diagram below shows the structure of time-series memtable.
In addition to the memtable, the memory usage of other components must also be carefully examined—such as the logging component. On the Android platform, our log output is bridged to logcat, so the buffer for the default log appender can be disabled. This change can save us tens of megabytes of memory.
Flash wear out
Vehicle HMI systems typically use NAND Flash storage rather than solid-state disks (SSDs). NAND Flash has a limited write-erase lifespan, so it's crucial to minimize write amplification when running a time-series database on such storage. This is a known issue with databases based on LSM tree architecture.
To address this problem, the GreptimeDB instance running on vehicles supports configurable Write-Ahead Logging (WAL) strategies for different tables. For tables with high write volumes, WAL can be disabled to reduce write amplification. Conversely, for tables with lower data volumes but higher reliability requirements, WAL can remain enabled. Given that modern electric cars are typically always on, ensuring data consistency through WAL in the event of unexpected power loss is often unnecessary. This allows for more flexible and efficient use of NAND Flash storage. In case of manual power off, GreptimeDB also provides a hook to persist all pending data in flash.
For compactions involving data reading and writing, considering the relatively small data volume on the vehicle side that will soon be uploaded to the cloud and merged by the ingester component, GreptimeDB allows disabling compaction on the vehicle side. This also helps reduce flash wear.
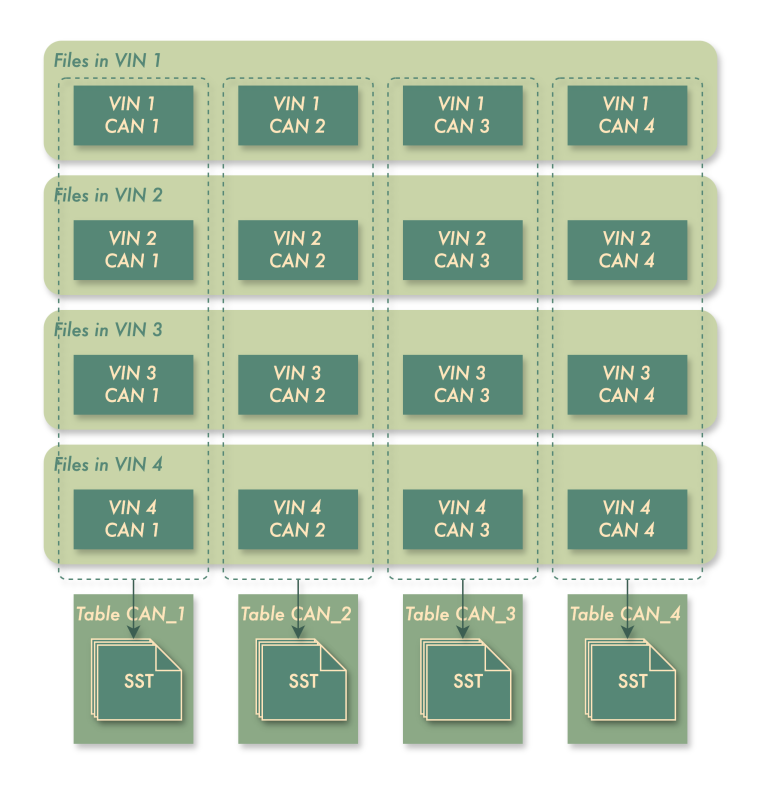
In addition to the above measures, we explored the shared memory method based on anonymous memory. On Linux, this mechanism typically creates a file under /dev/shm, which both the SDK and database map in their own processes. Unfortunately, Android does not support /dev/shm. Initially, we created physical files on flash storage but soon discovered that this caused severe wear and tear on flash. Eventually, we found that Android provides ashmem, which does not require writing physical files.
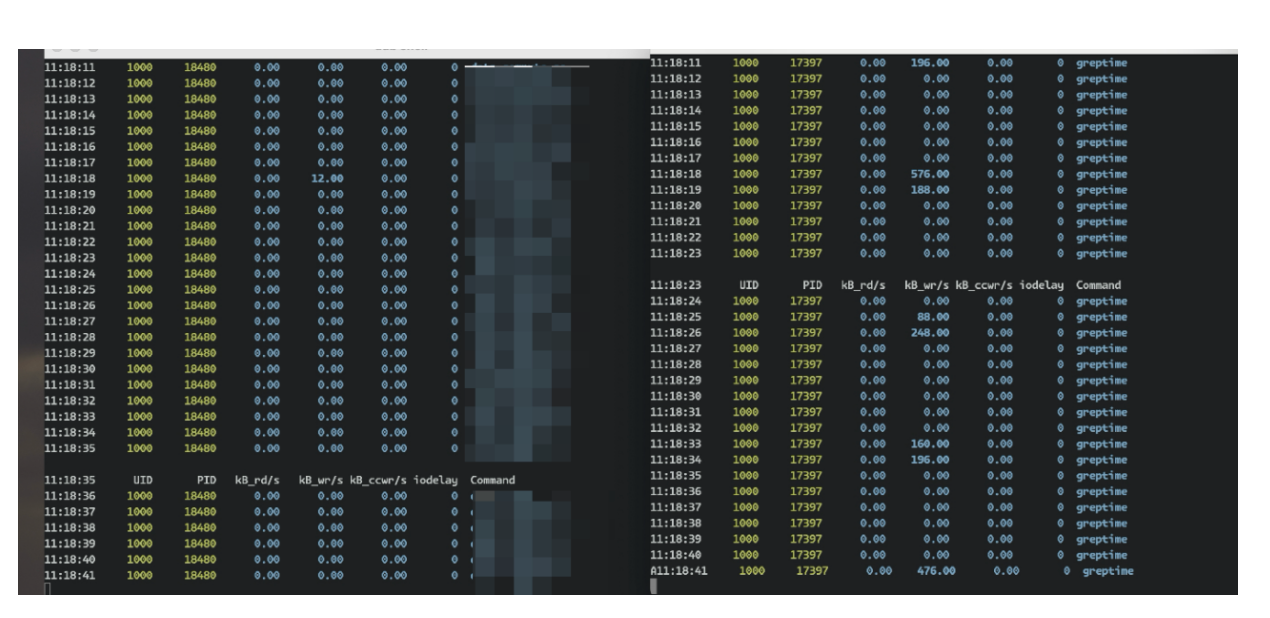
During performance testing on real-world cars, we observed that no disk I/O occurs on the SDK side; all I/O is related to database flush tasks. Thanks to its high compression rate, GreptimeDB writes only 2MB of files per second.
Build a binary that actually works on vehicles
Modern intelligent vehicle HMI often run on Android platform, so our primary challenge was how to compile GreptimeDB's source code into a binary that can run on Android and integrate with manufacture's code base. In traditional C/C++ system programming, cross-compilation is often a complex task. Fortunately, thanks to Rust's rich ecosystem, we found cargo-ndk, a Cargo plugin that helps set up cross-compilation for the Android platform. With cargo-ndk, we can compile binaries that run on Android from Linux, macOS, and Windows platforms.
bash
cargo ndk --platform 23 \
-t aarch64-linux-android \
build --bin greptime \
--profile release \
--no-default-featuresBesides cross compilation, to run a database on Android, you also have to provide polyglot components that fits Android systems, for example, logging, there's also an android-logger crate that addresses this issue. It can seamlessly bridge normal logging macros in Rust like debug!/info!/warn!/error! To logcat. GreptimeDB has integrated the verbose work into Github workflow, so you can download Android binaries from our Github release page.
It is worth noting that our SDK is also written in Rust, while the code base of car manufacturers usually use C/C++. Thus, we provide a foreign function interface (FFI) that wraps the Rust APIs and exposes them to C, as shown in the picture below:
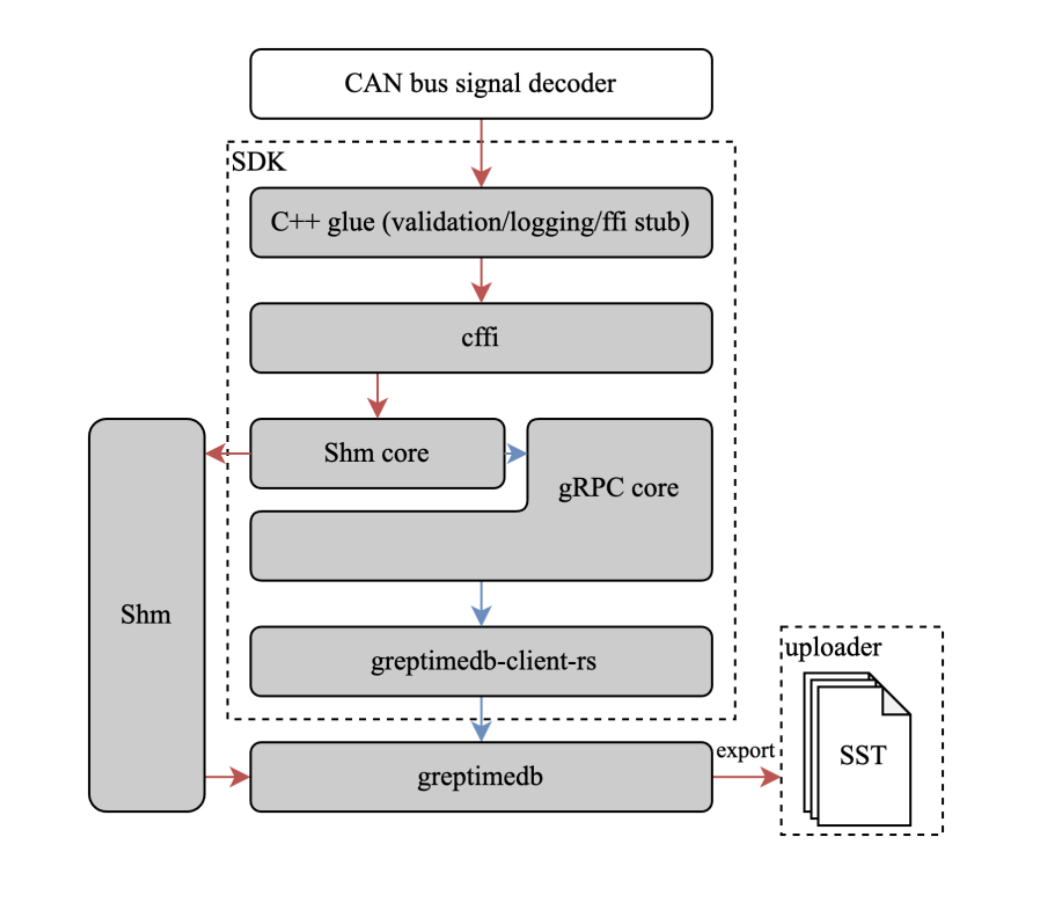
This architecture not only benefits from the ergonomic Rust ecosystem but also provides a stable, easy-to-integrate user interface. However, you should still be cautious with pointers and panics that cross the FFI boundary as mentioned in this blog post.
Towards the future of vehicle-side intelligence
This article introduces a low-cost, real-time vehicle-cloud integrated data solution built on Greptime's time-series database. It also discusses the issues we faced in this solution and the corresponding resolutions. So far, our solution has achieved excellent results in the collection and analysis of time-series diagnostic data on the vehicle side, saving manufacturers millions of dollars per year. However, our journey in exploring edge computing for smart cars has never ceased. With the rise of large language model (LLM) applications, smart cars can now leverage LLMs to provide richer passenger entertainment experiences and intelligent diagnostic tools. Under stringent privacy protection regulations, edge-side intelligence is gaining increasing importance, requiring smart cars to handle various multimodal data types such as vectors and images. GreptimeDB is exploring how to integrate multimodal data into the existing vehicle-cloud integrated solution, thereby accelerating the evolution of cars into more intelligent and versatile terminals.
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




