On this page
Introduction of Vector
Vector, a high-performance end-to-end observability data pipeline written in Rust, frequently encounters scenarios where upstream and downstream processing rates don't match. Often, Vector's actual throughput exceeds the processing capacity of downstream databases like Elasticsearch or ClickHouse.
To prevent overloading downstream services, Vector typically employs a rate-limiting mechanism. For example, in the HTTP Sink, users can configure request.rate_limit_duration_secs and request.rate_limit_num to control the rate. Below is an example where Vector limits the downstream rate to 10 ops(operations per second):
yaml
sinks:
my-sink:
request:
rate_limit_duration_secs: 1
rate_limit_num: 10However, static rate limiting isn't a perfect solution, as it struggles to adapt to dynamic conditions.
Why Adaptive Request Concurrency is Needed
There are two major challenges with static rate limiting:
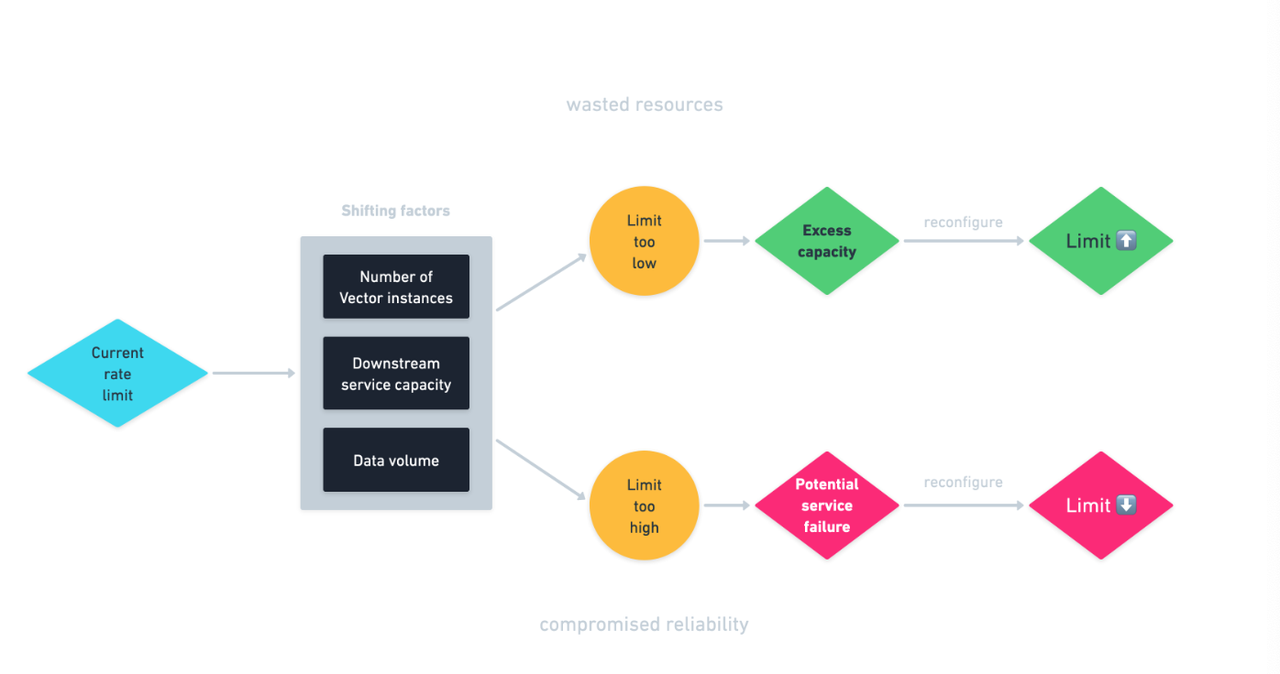
- Under-utilization of Resources: If the rate limit is set too low, the downstream database, which is capable of handling more traffic, may experience under-utilization of its resources.
- Overloading Downstream Databases: Conversely, if the rate limit is set too high, excessive traffic may overwhelm the downstream database, causing cascading system failures.
The optimal rate is always constrained by factors like the number of Vector instances, the capacity of downstream services, and the volume of data being sent. Static rate limiting can't dynamically adjust to these ever-changing factors.
Limitations of Static Rate Limiting
The following diagram illustrates the limitations of static rate limiting:
Adaptive Request Concurrency: Overcoming the Static Rate Limiting Bottleneck
To address the limitations of static rate limiting, the Vector team designed an** Adaptive Request Concurrency mechanism (ARC)**, inspired by the experiences shared in Netflix's blog post, Performance Under Load. ARC dynamically adjusts the data flow rate based on current system statistics, maximizing system throughput and preventing the resource wastage and overload issues associated with static rate limiting.
How ARC Works
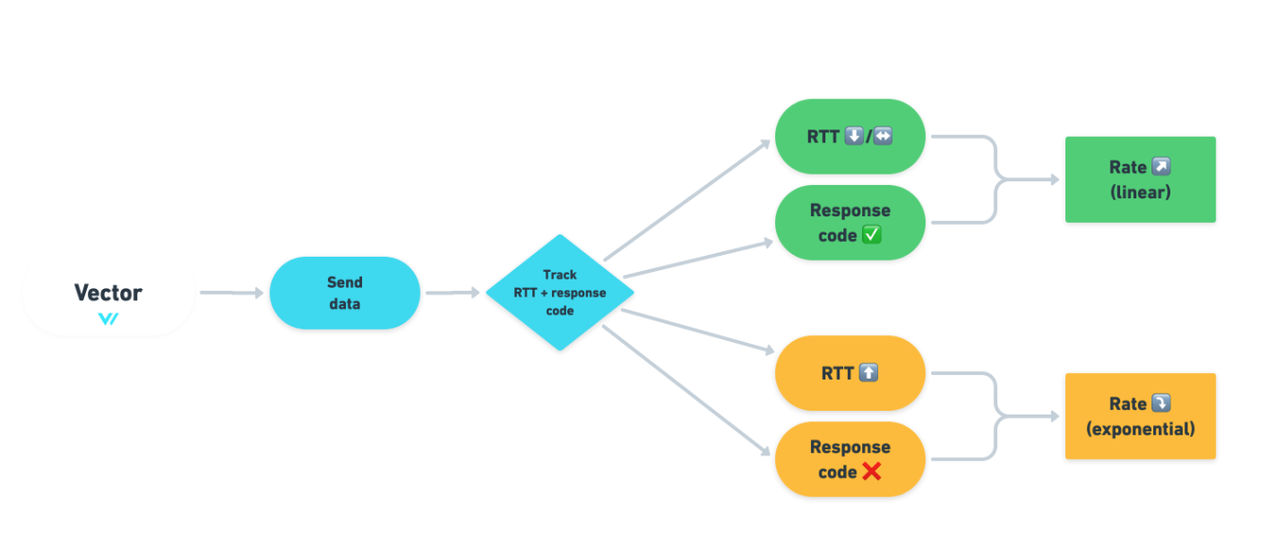
When ARC is enabled, Vector monitors two key metrics to dynamically adjust the flow control strategy:
- RTT (Round Trip Time): Reflects the latency of the requests, indicating the response speed.
- HTTP Response Codes: Indicates the success or failure of requests, with error codes (e.g., 429 and 503) providing insights into the health of downstream services.
Using these metrics, Vector employs the AIMD (Additive Increase Multiplicative Decrease) algorithm to adjust the traffic:
- Additive Increase: If RTT is stable or decreasing and HTTP response codes indicate success (e.g., 200 OK), it suggests that the downstream service can handle more traffic, prompting Vector to linearly increase the throughput. For example, it may increase operations per second from 10 to 11, then 12, and so on.
- Multiplicative Decrease: If RTT increases or HTTP response codes return errors (e.g., 429 Too Many Requests or 503 Service Unavailable), it indicates that the downstream service is overloaded. Vector then exponentially reduces the traffic, for example, reducing the operations per second from 20 to 10, and then to 5. The rate of decrease can be configured using request.adaptive_concurrency.decrease_ratio.
The following diagram illustrates how Vector dynamically adjusts traffic in ARC mode based on system load:
AIMD Algorithm and TCP Congestion Control
The AIMD algorithm is derived from TCP congestion control and is widely used in network protocols to effectively balance bandwidth utilization and network stability. In Vector, AIMD helps maintain high throughput while preventing system crashes caused by overload, ensuring system stability.
ARC is implemented as a Tower Layer in Vector. For those interested, the implementation details can be explored in this file.
Configuring ARC
ARC is currently supported by all HTTP data-receiving sinks. Taking ClickHouse Sink as an example, users can enable Adaptive Request Concurrency with the following configuration:
yaml
sinks:
clickhouse_internal:
type: clickhouse
inputs:
- log_stream_1
- log_stream_2
host: http://clickhouse-prod:8123
table: prod-log-data
request:
concurrency: adaptiveWith this configuration, Vector will use Adaptive Request Concurrency to write data to ClickHouse. After enabling ARC, Vector will automatically adjust the data transmission rate based on real-time system conditions, ensuring that the system remains stable and efficient, even under varying loads.
Adaptive Request Concurrency (ARC) is an effective solution
Adaptive Request Concurrency (ARC) is an effective solution for handling mismatched processing rates between upstream and downstream services in modern complex systems. By monitoring RTT and HTTP response codes in real-time, Vector can dynamically adjust the request rate, maximizing resource utilization and ensuring the health of downstream databases. Compared to static rate limiting, ARC provides a more flexible, intelligent approach that improves the overall efficiency and reliability of the system while maintaining stability.
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




