On this page
What Are Read Replicas?
Read Replica is a core feature in GreptimeDB Enterprise, designed to enhance overall read/write performance and horizontal scalability.
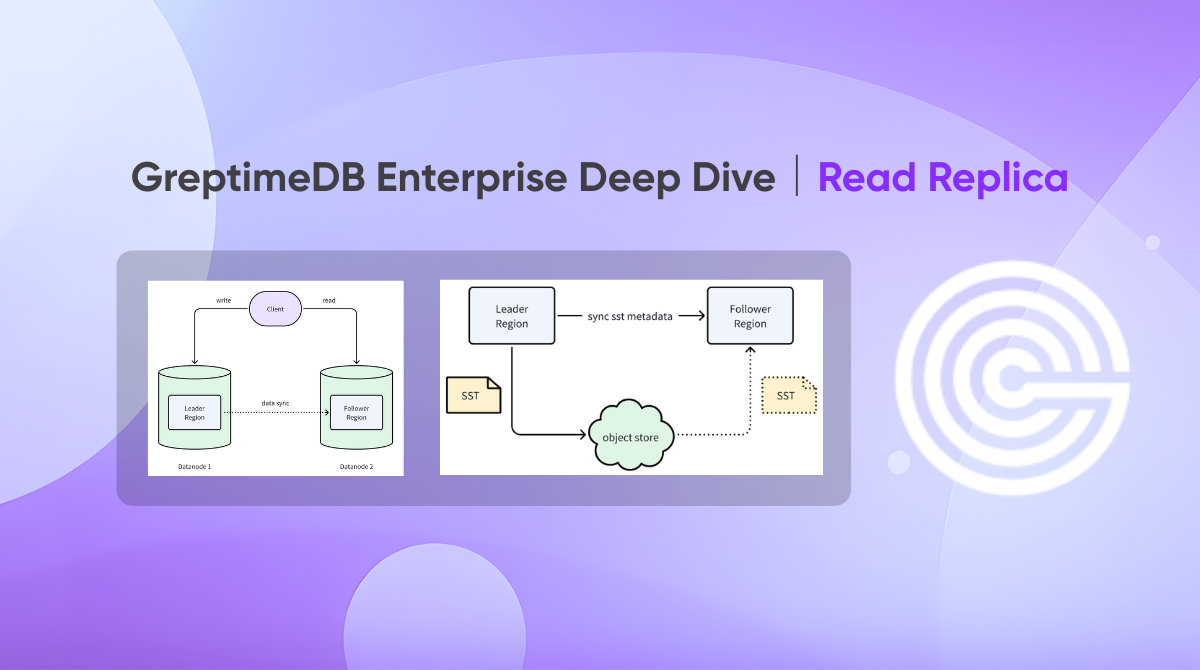
In this model, all client writes are directed to the Leader Region, which then synchronizes data to one or more Follower Regions. Followers are read-only replicas of the Leader.
By deploying Leader and Follower Regions on separate Datanodes, GreptimeDB cleanly separates read and write traffic, preventing resource contention and ensuring a smoother user experience:
How It Works
Data Synchronization
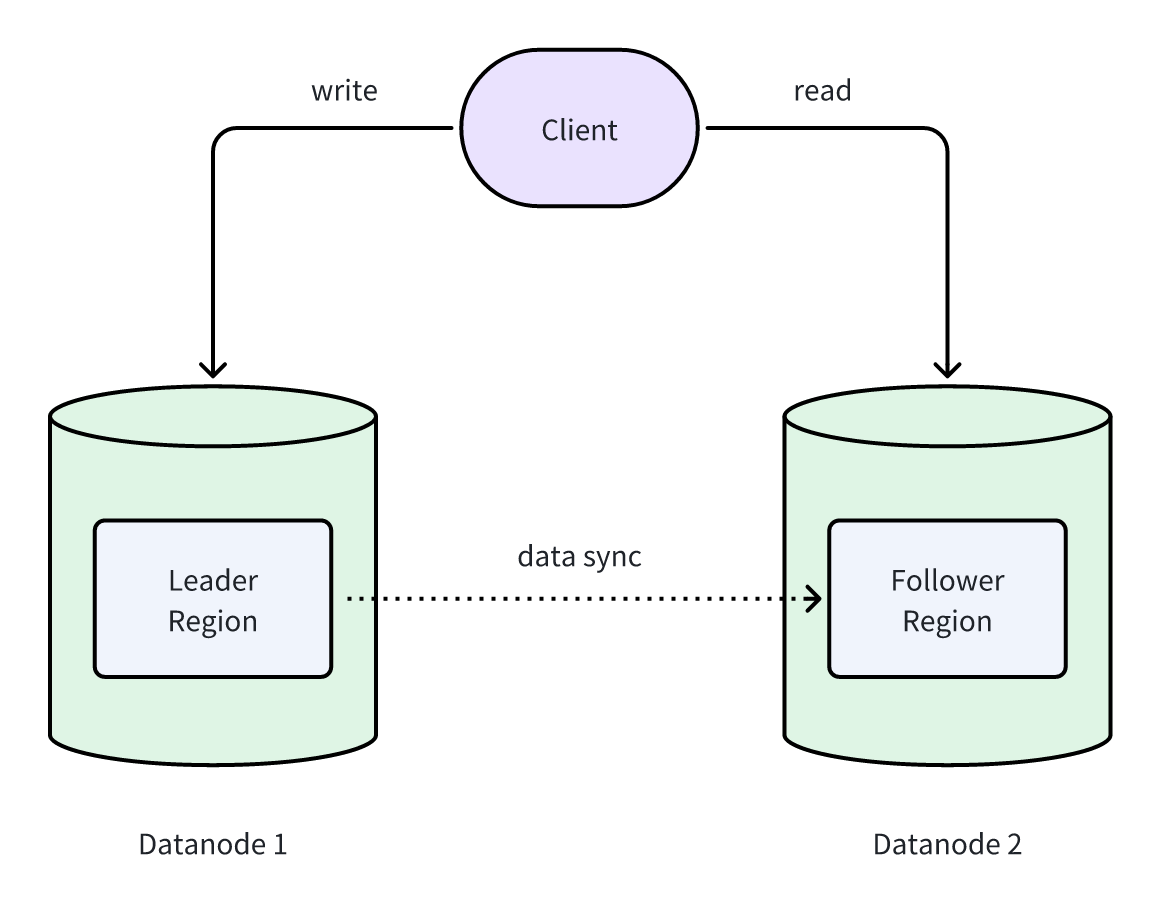
In GreptimeDB Enterprise, all data is ultimately stored as SST files in object storage. This design eliminates the need for Leaders to replicate entire SST files to Followers. Instead, only the metadata needs to be synchronized.
Since metadata is far smaller than an SST file, Leaders can synchronize it very efficiently. Once a Follower receives the metadata, it can reference the exact same SST files in object storage—instantly “owning” the same dataset.
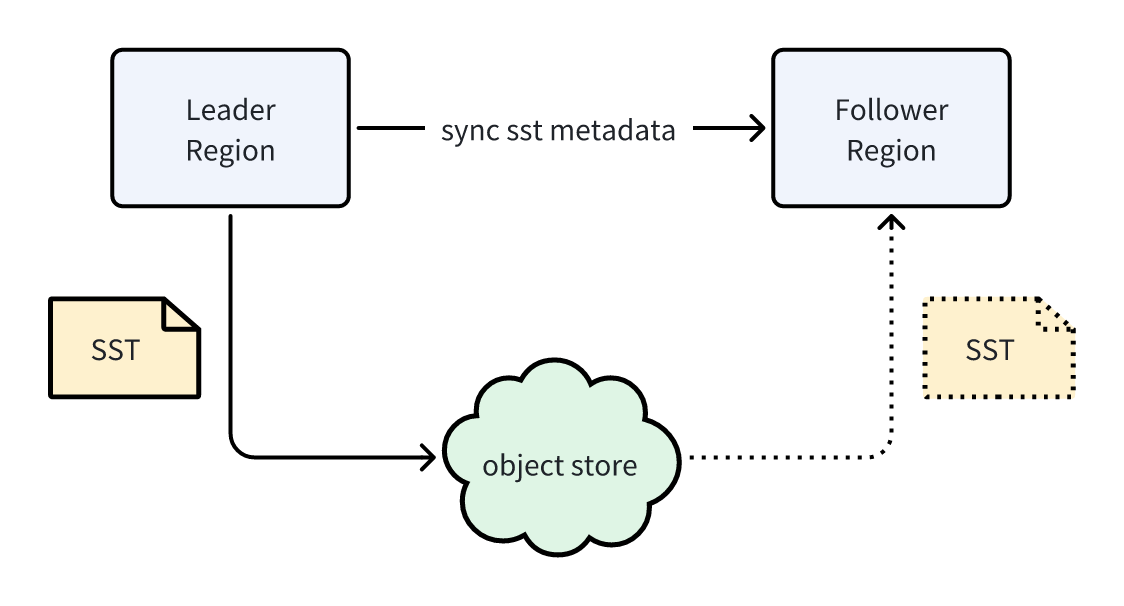
Manifest Files and Versioning
The metadata of SST files is persisted in a special manifest file, which, like SST files, resides in object storage. Each manifest file has a unique version number.
Thus, data synchronization between Leader and Follower Regions is essentially just the synchronization of this version number—an extremely lightweight process since it is merely an integer. Once a Follower receives the version number, it retrieves the corresponding manifest from object storage and gains access to the Leader’s SST metadata.
This process leverages the heartbeat mechanism between Regions and the Metasrv service:
- The Leader includes the manifest version number in its heartbeat to Metasrv.
- Metasrv then passes this version number to the Follower during its heartbeat reply.
In practice, this means that if synchronization relies only on SST files, the data visibility delay for Followers depends on the combined heartbeat intervals of Leader and Follower Regions.
For example, with a default heartbeat interval of 3 seconds per Region, Followers will see data that is flushed to object store 3–6 seconds old.
This latency may be acceptable in scenarios where strict real-time guarantees are not required. However, for applications demanding instant visibility of writes, GreptimeDB introduces an additional mechanism.
Data Reading Mechanism
The most recent writes are first buffered in the Leader’s Memtable. To allow Followers to serve the latest data, they use an internal gRPC interface to fetch the Leader’s Memtable content.
The Follower then merges two data sources:
- SST files synchronized via manifest metadata.
- The latest in-memory data fetched directly from the Leader’s Memtable.
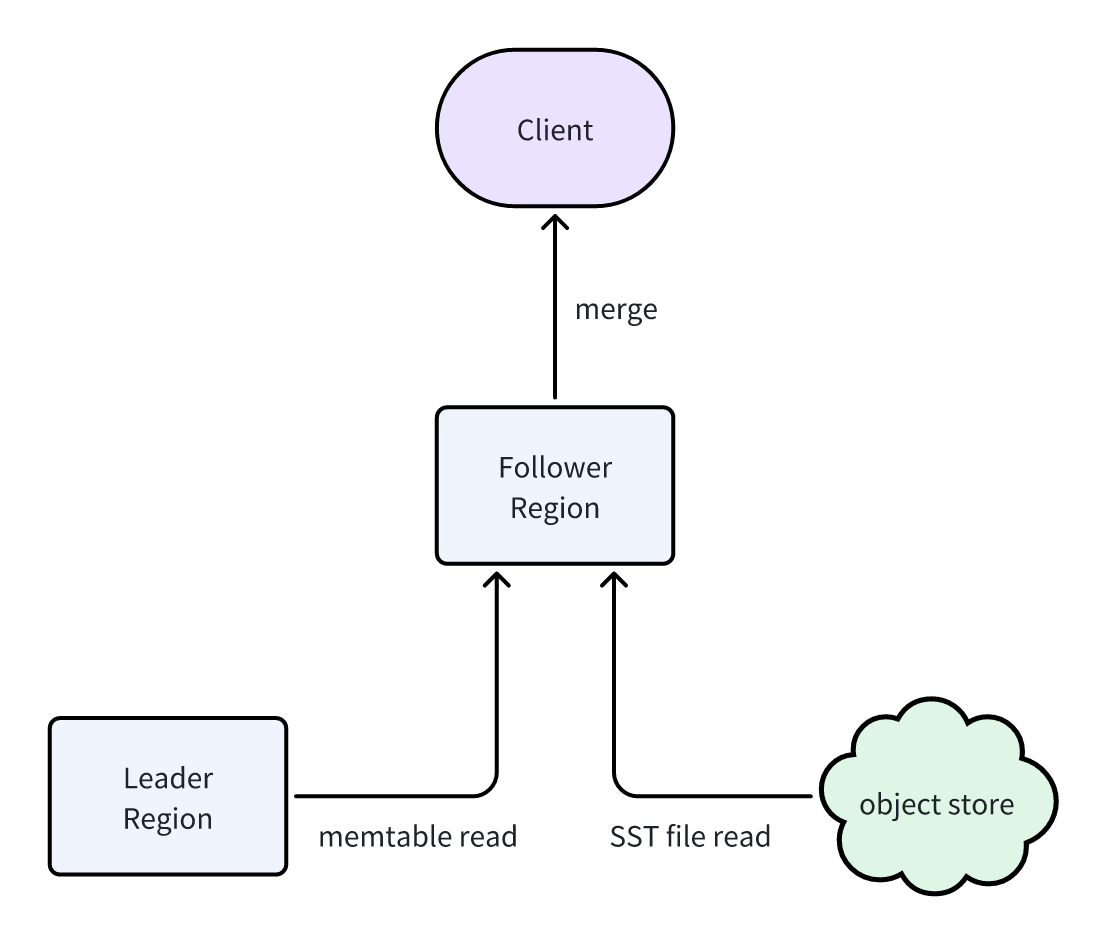
This design ensures that read replicas can return complete and up-to-date datasets identical to the Leader.
Although this approach introduces some read load on the Leader, the impact is minimal. Memtable data is fully in-memory and bounded in size, keeping the overhead lightweight.
Adding Read Replicas
GreptimeDB makes adding read replicas straightforward—just a single SQL command:
sql
ADMIN ADD_TABLE_FOLLOWER(<table_name>, <follower_datanodes>)Parameters:
table_name: Name of the table.follower_datanodes: Comma-separated list of target Datanode IDs where Followers should be placed.
For example, in a cluster with 3 Datanodes:
sql
CREATE TABLE foo (
ts TIMESTAMP TIME INDEX,
i INT PRIMARY KEY,
s STRING,
) PARTITION ON COLUMNS ('i') (
i <= 0,
i > 0,
);Querying Region information:
sql
SELECT table_name, region_id, peer_id, is_leader
FROM information_schema.region_peers
WHERE table_name = 'foo';
+------------+---------------+---------+-----------+
| table_name | region_id | peer_id | is_leader |
+------------+---------------+---------+-----------+
| foo | 4402341478400 | 1 | Yes |
| foo | 4402341478401 | 2 | Yes |
+------------+---------------+---------+-----------+The table foo has 2 Regions on Datanodes 1 and 2. Now let’s add replicas:
sql
ADMIN ADD_TABLE_FOLLOWER('foo', '0,1,2');Afterward, querying information_schema shows new Followers created:
sql
+------------+---------------+---------+-----------+
| table_name | region_id | peer_id | is_leader |
+------------+---------------+---------+-----------+
| foo | 4402341478400 | 1 | Yes |
| foo | 4402341478400 | 0 | No |
| foo | 4402341478401 | 2 | Yes |
| foo | 4402341478401 | 1 | No |
+------------+---------------+---------+-----------+Now, two Followers are deployed on Datanodes 1 and 2.
Querying with Read Replicas
Clients can configure read preferences to decide whether queries should target Leaders or Followers. With JDBC connections (MySQL/PostgreSQL protocols), the following settings are available:
sql
-- Direct queries to Follower Regions only.
-- If no Followers exist, the query will error out.
SET READ_PREFERENCE='follower';
-- Prefer Followers, but fall back to Leader if none are available.
SET READ_PREFERENCE='follower_preferred';
-- Direct queries exclusively to the Leader Region.
SET READ_PREFERENCE='leader';Example: insert data into foo:
sql
INSERT INTO foo (ts, i, s)
VALUES (1, -1, 's1'), (2, 0, 's2'), (3, 1, 's3');
Then query with Follower preference:
SET READ_PREFERENCE='follower';
SELECT * FROM foo ORDER BY ts;Result:
sql
+----------------------------+------+------+
| ts | i | s |
+----------------------------+------+------+
| 1970-01-01 00:00:00.001000 | -1 | s1 |
| 1970-01-01 00:00:00.002000 | 0 | s2 |
| 1970-01-01 00:00:00.003000 | 1 | s3 |
+----------------------------+------+------+The read replica correctly returns the latest dataset.
Conclusion
The Read Replica feature in GreptimeDB Enterprise enables true read/write separation, significantly improving system throughput and scalability. By combining lightweight metadata synchronization with real-time Memtable reads, GreptimeDB delivers both low cost and low latency.
For read-intensive workloads—such as high-concurrency queries, reporting, and analytical dashboards—read replicas provide a powerful foundation for performance optimization and cost efficiency, making them a key capability for enterprise users.




