On this page
We recently shared the major highlights and release roadmap for GreptimeDB v1.0. This week, we're releasing the second beta of v1.0.0—a key step toward v1.0 GA and an important milestone in making GreptimeDB production-ready.
Development Overview
Here are the statistics for beta2 (Nov 11 – Dec 2, 2025, 21 days):
- 83 PRs merged, affecting 626 files
- Lines changed:
+25,655 / -6,485 - 18 contributors participated, with 6 independent contributors accounting for 9.5% of commits
- New contributor: @McKnight22—welcome to the GreptimeDB community!
Breakdown of changes:
- 34 feature enhancements: batch Region migration, dynamic tracing toggle,
Dictionarytype support,COPY DATABASEparallelization, and more - 18 bug fixes: write stall in certain scenarios, potential Metric Engine deadlock during schema changes, index cache fixes, PostgreSQL/MySQL protocol compatibility, and more
- 8 refactoring improvements: export metrics legacy config removal,
SHOW TABLESperformance optimization, unified metadata loading, and more - 5 performance optimizations: TSID generation speedup, parallel Region loading, eliminate unnecessary merge sort, and more
👏 Thanks to all 18 contributors! Special welcome to @McKnight22!
We invite developers interested in observability databases to join the GreptimeDB community.
Highlights
Bulk Ingest Now Supports Flat Format
In v1.0.0-beta1, we introduced Flat Format to significantly improve write and query performance for high-cardinality primary key scenarios. However, Flat Format only supported traditional row-based protocols and couldn't be used with Bulk Ingest.
In beta2, Bulk Ingest (SDK) fully supports Flat Format:
- The previous limitation of Bulk Ingest not supporting primary keys has been removed
- Bulk Ingest's columnar batch write capability now works directly with Flat Format
- Write performance improved by over 60% compared to the previous Bulk Ingest
Here are the benchmark results on a laptop (Apple M2 Pro, 16GB):
| Write Method | Table Type | Throughput |
|---|---|---|
| Regular API | Regular Table | 104,237 rows/s |
| Bulk API | Regular Table | 155,099 rows/s |
| Bulk API | Flat Format Table | 257,136 rows/s |
The Bulk API + Flat Format combination delivers approximately 2.5x better performance than the Regular API.
Batch Region Migration
We've optimized Region migration scheduling. Multiple Region migrations targeting the same Datanode are now automatically batched into a single request, instead of separate distributed calls for each Region.
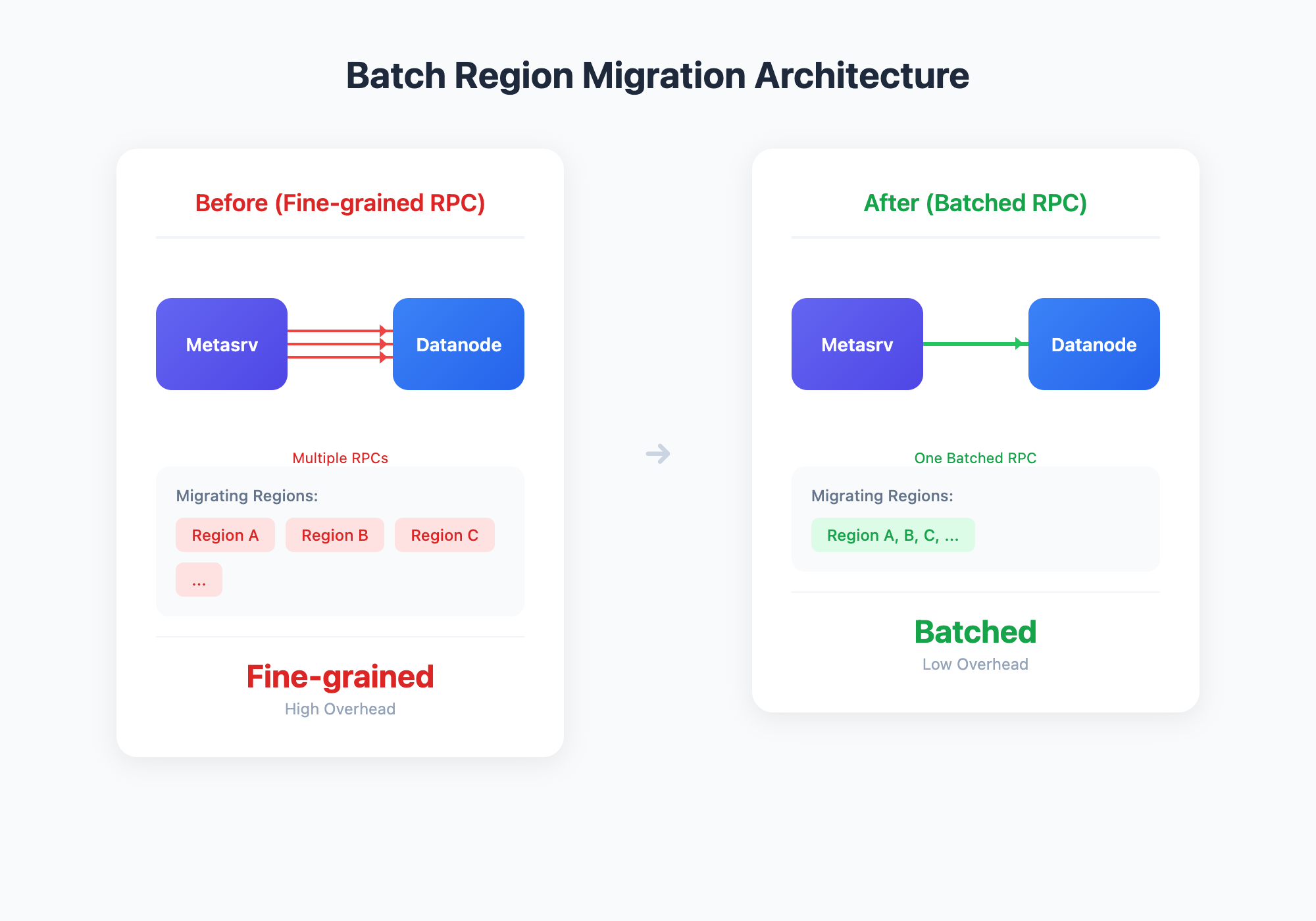
This batch approach provides significant benefits:
- Dramatically reduced RPC call volume, lowering network and scheduling overhead
- Faster scaling operations and failure recovery
- More stable migrations, eliminating Datanode instability from concurrent Region migrations
- Especially effective for large clusters with hundreds or thousands of Regions
ALTER DATABASE Enhancements
New ALTER DATABASE options for online compaction parameter adjustment:
sql
-- Modify compaction time window
ALTER DATABASE db SET 'compaction.twcs.time_window'='2h';
-- Modify maximum output file size for compaction
ALTER DATABASE db SET 'compaction.twcs.max_output_file_size'='500MB';
-- Modify the number of files that trigger compaction
ALTER DATABASE db SET 'compaction.twcs.trigger_file_num'='8';
-- Unset compaction options
ALTER DATABASE db UNSET 'compaction.twcs.time_window';MySQL/PostgreSQL Protocol Compatibility
beta2 significantly improves database protocol compatibility, with key improvements including:
- PostgreSQL timezone settings and extended query parsing
- Numeric type alias alignment with standards
- PreparedStatement batch insert compatibility
Thanks to all users who provided feedback—your input helps us continuously improve GreptimeDB.
This release also improves compatibility when using GreptimeDB as a StarRocks JDBC External Catalog:
sql
CREATE EXTERNAL CATALOG greptimedb_catalog
PROPERTIES (
"type" = "jdbc",
"user" = "your_username",
"password" = "your_password",
"jdbc_uri" = "jdbc:mysql://<greptimedb_host>:4002",
"driver_url" = "https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.28/mysql-connector-java-8.0.28.jar",
"driver_class" = "com.mysql.cj.jdbc.Driver"
);Other Improvements
- Dictionary type: New Dictionary encoding for storage optimization of low-cardinality string columns
- Compressed export:
COPY DATABASEexport to CSV/JSON with compression support - COPY DATABASE parallelization: Parallel table operations for faster large-scale data export
- Dynamic tracing: Enable/disable tracing at runtime without service restart
- Reloadable TLS config: Hot-reload support for TLS client configuration
If you encounter any issues while evaluating or testing GreptimeDB, please submit them to our GitHub Issues—we actively respond to all feedback.
Important Bug Fixes
- Write stall in certain scenarios: Fixed flush logic causing unrecoverable write stalls
- Metric Engine deadlock: Fixed potential deadlock during batch alter tables when changing schema
- Index cache: Fixed page clone issue before putting into index cache
Performance Optimizations
- TSID generation speedup: Using fxhash instead of mur3, 5–6x faster in common scenarios, ~2.5x faster with NULL tags
- Parallel File Source Region: Faster Region loading
- Eliminate unnecessary merge sort: Reduced query overhead
- Parallel Partition Sources building: Improved partitioned table build efficiency
- SHOW TABLES optimization: Significant performance improvement when many tables exist
Compatibility Notes
This release includes the following breaking changes:
Metric Engine TSID Generation Algorithm Change
We've replaced the TSID generation algorithm from mur3::Hasher128 to fxhash::FxHasher and added a fast-path for tags without NULL values.
Impact: At upgrade time t, data written before the upgrade uses the old TSID algorithm, while data written after uses the new algorithm. Queries spanning the upgrade moment may see slight discrepancies in time series matching near t. Queries not spanning t are unaffected.
For users who cannot accept this discrepancy, we recommend a full-compatible upgrade using "export data → upgrade → import data". See the Backup and Restore documentation for details.
MySQL/PostgreSQL Compatibility Improvements
Numeric type aliases have been aligned with standard MySQL/PostgreSQL. Some non-standard usages may require adjustment.
Removal of export_metrics Feature and Configuration
The export_metrics feature for actively pushing monitoring metrics has been completely removed. Please remove any [export_metrics] related configuration from your config files.
Conclusion
For the complete changelog, see the GitHub Release.
Thanks to all contributors and users for your support. We'll continue working toward the 1.0 GA release as planned.




