Elasticsearch Alternative for Logs and Observability: Why GreptimeDB

Introduction
The classic ELK stack — Elasticsearch, Logstash, Kibana — was built around full-text search. It is excellent at that. The trade-off shows up once logs are the primary workload: Lucene's inverted indexes inflate storage well beyond raw input, JVM heap pressure climbs with cardinality, and scaling means scaling the entire stack together because compute and storage are coupled to local disk.
GreptimeDB takes the observability-first path. Logs, metrics, traces, and wide events live in one engine, with columnar Apache Parquet on object storage as the primary format and full-text indexing layered only where it earns its keep. In a head-to-head Nginx log benchmark on identical hardware, GreptimeDB sustained 4.7× the structured write throughput of Elasticsearch (185K vs 39K rows/s), held storage to 1.3 GB versus 14.6 GB on the same 10 GB raw dataset, and ran on 408 MB of memory while Elasticsearch consumed nearly 10 GB.
This article walks through where GreptimeDB is a direct Elasticsearch alternative for log and observability workloads, and where Elasticsearch still has the edge. For OLAP-shaped observability workloads, see the standalone ClickHouse alternative article.
Why Elasticsearch Bloats on Logs
Elasticsearch's storage model is the root of most operational pain at scale. Three things compound:
- Inverted indexes are expensive. Every indexed field carries a posting list, term dictionary, and doc-value structure. On a 10 GB raw Nginx log dataset, Elasticsearch's persisted footprint reached 14.6 GB — about 102% of the source, versus GreptimeDB's 1.3 GB (13%).
- Replicas multiply. A 1× replica doubles every byte. Default ELK guidance for production is 1–2 replicas per shard, so the 14.6 GB above becomes 29–44 GB of provisioned disk.
- High-cardinality fields explode. Trace IDs, span IDs, and user tokens push the index to extremes. The GreptimeDB vs Elasticsearch comparison reports trace storage inflating up to 45× compared with columnar storage.
The runtime cost follows the same shape. At a steady 20K rows/s ingestion in the Nginx benchmark, Elasticsearch held 9.9 GB resident memory at 40% CPU. GreptimeDB held 408 MB at 13% CPU on the same load. Memory pressure pushes operators toward larger nodes (or more nodes), which scales cost linearly without changing the underlying inefficiency.
Benchmark Snapshot
Both databases tested on identical hardware against 1 billion Nginx access log records (~10 GB raw). Numbers from the GreptimeDB v0.12 log benchmark.
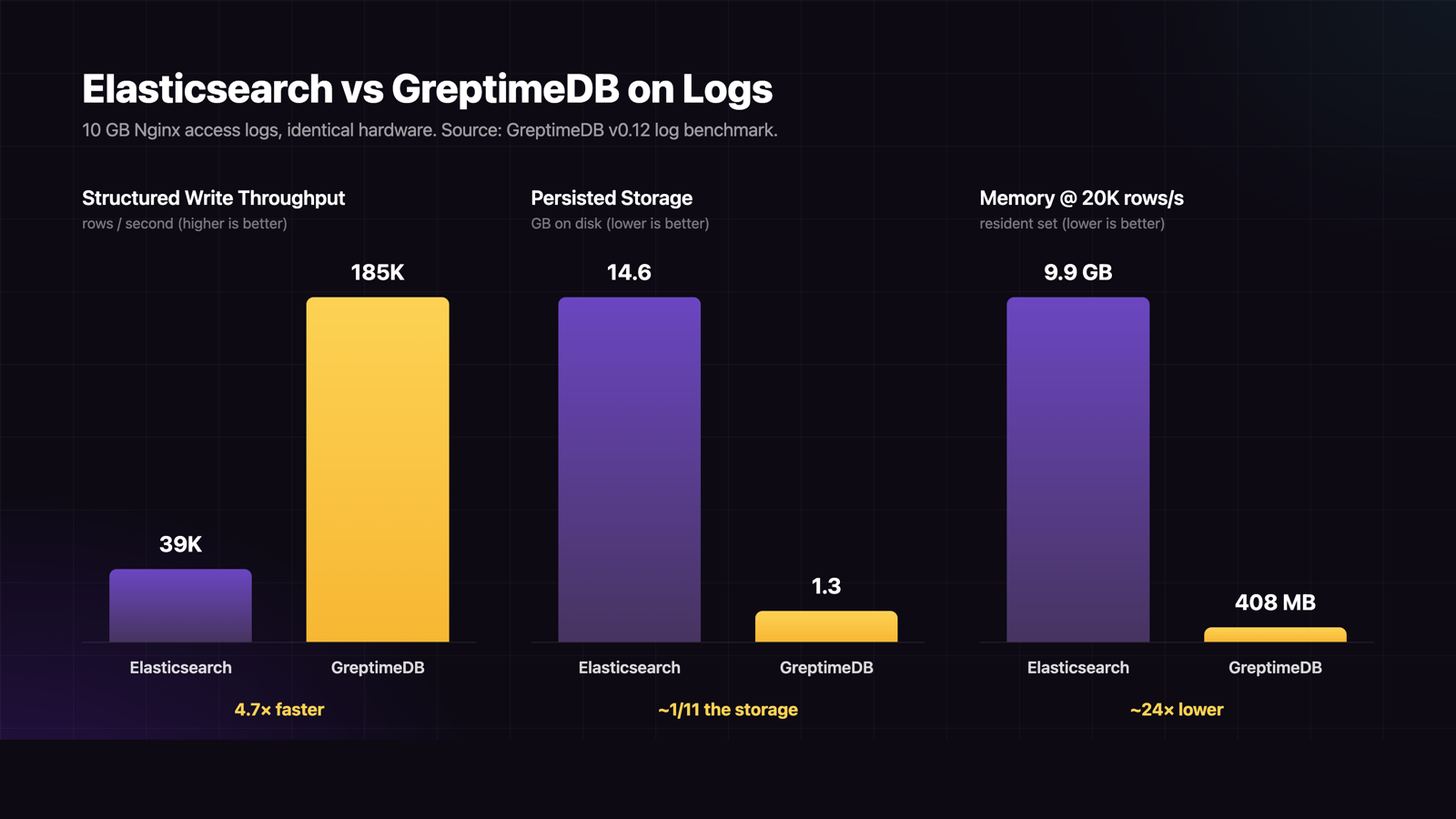
| Metric | Elasticsearch 8.15 | GreptimeDB v0.12 | Delta |
|---|---|---|---|
| Structured write TPS | 39,000 | 185,000 | 4.7× |
| Unstructured write TPS | 28,000 | 159,000 | 5.7× |
| Persisted size (10 GB raw) | 14.6 GB | 1.3 GB | ~1/11 the storage |
| Memory at 20K rows/s | 9.9 GB | 408 MB | ~24× lower |
| CPU at 20K rows/s | 40% | 13% | ~3× lower |
count query (structured) | 10 ms | 6 ms | 1.7× faster |
| Keyword search (structured) | 134 ms | 22.8 ms | 5.9× faster |
A separate etcd cluster monitoring benchmark on production logs (83 GB raw, 90-day retention) confirms the storage advantage holds outside Nginx-shaped workloads: GreptimeDB compressed the same dataset to 3.03 GB, less than half of Loki's 6.59 GB.
Object Storage as Primary, Not Cold Tier
Elasticsearch's hot data sits on local block storage. S3 is supported as a snapshot or cold tier, but the engine is designed around fast local disk for everyday queries. At observability scale — terabytes per day, weeks of retention — that ties storage cost to provisioned SSD pricing.
GreptimeDB writes Parquet directly to S3, GCS, Azure Blob, or MinIO as primary, with a multi-tier cache for hot reads. At current AWS list prices, S3 Standard at ~$0.023/GB/mo sits roughly 3–5× below provisioned SSD EBS (gp3 ~$0.08/GB/mo). The Nginx benchmark measured only 1–2% throughput loss on AWS S3 versus local disk, so the cost gap translates directly.
Combined with the ~1/11 compressed footprint above, the effective monthly storage bill for retained logs drops by an order of magnitude. The GreptimeDB OSS product page summarises this as up to 50× total cost reduction for observability workloads.
Query Performance: Where Each Wins
Pure full-text search remains Elasticsearch's home turf. For log queries — keyword search inside a time window, frequency aggregations, top-N error sources — the access pattern is timestamp-first, and GreptimeDB's columnar layout plus optional full-text index on the message column matches it directly.
In the etcd benchmark, GreptimeDB ran 40–80× faster than Loki on keyword search and per-minute aggregations, with cached repeated queries an additional order of magnitude faster. The same caching layer keeps tail-latency predictable on large time ranges where Loki and Elasticsearch tend to time out.
Where Elasticsearch still leads: ad-hoc full-document scoring, free-form search across many fields without a schema in mind, and any workload genuinely shaped like a search index rather than a time-series store.
Architecture: ELK Stack vs One Engine
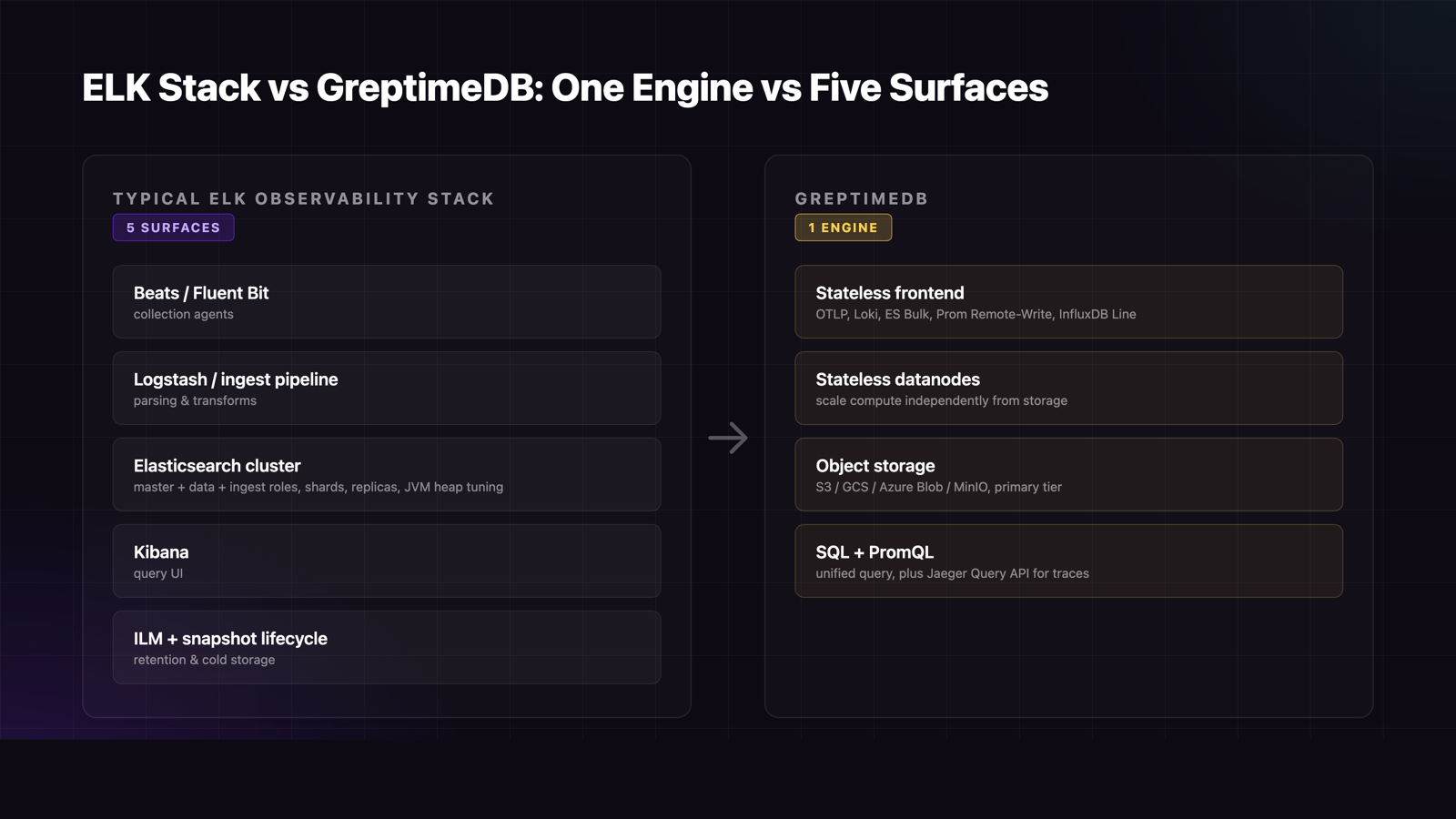
A typical ELK observability deployment has Beats or Fluent Bit for collection, Logstash or an ingest pipeline for transforms, Elasticsearch nodes (master + data + ingest roles, with shards and replicas), Kibana for query UI, and ILM policies plus snapshot lifecycle for retention. Five operational surfaces, each with its own scaling story, version cadence, and failure mode.
GreptimeDB ships as a stateless frontend, stateless datanodes, and native object storage. Compute and storage scale independently. Ingestion happens through OTLP, InfluxDB Line Protocol, Prometheus Remote Write, Loki Push API, or Elasticsearch Bulk API — pick whichever your existing collector speaks. No Logstash to maintain, no shard rebalancing, no JVM heap to tune.
Migration Path
Most ELK deployments can move incrementally:
- Redirect ingestion (~30 minutes). GreptimeDB exposes a native Elasticsearch Bulk API endpoint, so existing Filebeat, Fluent Bit, or Vector pipelines write through unchanged.
- Switch Grafana datasource (~1 hour). Same dashboards, same query UX.
- Backfill historical (1–3 days). Bulk replay or parallel writes during cutover.
- Decommission the ELK cluster (~2 weeks). Once parity is confirmed.
For traces, the Jaeger Query API is exposed natively, so existing Jaeger-on-Elasticsearch deployments keep their UI.
When Elasticsearch Still Wins
This is an alternative-for-logs-and-observability comparison, not an "Elasticsearch is bad" argument. Elasticsearch remains the right pick for:
- Document search workloads: full-text scoring, relevance ranking, free-form query DSL across rich JSON.
- Application search: site search, product catalogue, e-commerce, anything genuinely shaped like a search index.
- Existing ELK skill sets where the team is deeply invested and the workload mix leans search rather than observability.
The case for GreptimeDB as an Elasticsearch alternative gets strongest when storage cost, ingestion volume, or operational simplicity are the binding constraints — which is the situation most large log pipelines find themselves in after a year or two of growth.
Conclusion
For log and observability workloads, GreptimeDB is a direct Elasticsearch alternative: roughly an order of magnitude smaller storage, 4–6× higher write throughput, a fraction of the memory, and one engine instead of a multi-component stack. Object-storage-first economics change the cost curve for long-retention data, and migration is a one-week incremental cutover thanks to the native Bulk API endpoint.
See the full GreptimeDB vs. Elasticsearch comparison for the feature-by-feature breakdown, or deploy GreptimeDB on Kubernetes to run your own logs through it.
About Greptime
GreptimeDB is an open-source, cloud-native database purpose-built for real-time observability. Built in Rust and optimized for cloud-native environments, it provides unified storage and processing for metrics, logs, and traces — delivering sub-second insights from edge to cloud at any scale.
GreptimeDB OSS – The open-sourced database for small to medium-scale observability and IoT use cases, ideal for personal projects or dev/test environments.
GreptimeDB Enterprise – A robust observability database with enhanced security, high availability, and enterprise-grade support.
We're open to contributors — get started with issues labeled good first issue and connect with our community.
Stay in the loop
Join our community
Get the latest updates and discuss with other users.




