On this page
With the prospering of cloud-native technologies, on-premises database operations face increasing new challenges. So what kind of database operation system do we need in the cloud-native era? Based on our in-depth research and experience, an ideal database operation system should have the following characteristics.
Autopilot
We hope that the operation of databases is as intelligent as possible, similar to the autonomous driving level of unmanned vehicles. If problems occur in database clusters, the control plane can intelligently self-repair to isolate and resolve the issue. Complete automatic operation requires comprehensive observational capabilities of the database plane to be able to make optimal automated operation processing decisions based on the collected data. Today, with enterprises emphasis on reducing overhead costs while increasing operational efficiency, smarter control planes bring higher labor-efficiency ratio. Thus, we can operate and maintain large-scale database clusters at as little cost as possible.
Ergonomics
No matter how powerful the database operation system is, an abstract but concise interface must be provided to end users. We have to make sure that users can easily operate the database operation system without having to master much pre-domain knowledge, and they can also expand the functions by adding new configuration options upon further exploring the system.
Unified Architecture
In the cloud-native era, future databases must be built on multiple clouds, so the database operation system must also be designed for multi-cloud operations. No matter what cloud the user uses, the control plane should manage the differences appropriately and generate a unified user model. Since the database operation system has certain architectural flexibility, the same set of codes can be used in combination with different configurations to deploy database clusters with consistent functions across a variety of infrastructures.
Considering the above characteristics a good database operation system must possess, the GreptimeDB team open sourced both greptimedb-operator and gtctl to help users better operate and maintain GreptimeDB clusters in the cloud environment.
Embrace Kubernetes
Kubernetes (K8s) is an automatic and flexible open-source orchestration solution for managing containerized workloads and its infrastructure. K8s has developed a large, rapidly growing ecosystem since Google open-sourced it in 2014[1], and from 2020 to 2021, the number of K8s engineers grew by 67% to 3.9 million[2]. To ensure a fast growth rate of a cloud-native database, harnessing the power of the K8s ecosystem by running the application smoothly on it is the first step. Only through this can users deploy GreptimeDB among different infrastructure providers seamlessly.
The Operator pattern of K8s enables developers to build applications by using extensions and APIs. Compared with simply packaging the entire database clusters into K8s native resources for deployment, the Operator model is more flexible and scalable. Operator encapsulates a large amount of operation related domain knowledge of the database, and presents itself as a CustomResourceDefinition (CRD) model that is easier to be understood by users. It also combines K8s' unique Reconcile loop at runtime to continuously maintain the database clusters in the declared desired state of the CRD model. We can treat the K8s Operator as an intelligent operation robot, which consistently executes the instructions by performing repetitive tasks on behalf of human operators; once various incidents occur, the robot will automatically handle them according to its encapsulated domain knowledge to achieve the desired state of the system.
GreptimeDB decided to embrace K8s since Day 1. Even when the database was still in the earliest stand-alone version, we began to develop the Operator of the GreptimeDB clusters in Mock mode, which later became today's greptimedb-operator. The GreptimeDB cluster has 3 different components (more will be designed in the future):
Frontend Frontend: provides Proxy services which are compatible with different protocols, such as MySQL, PostgreSQL, Prometheus, InfluxDB, etc., and users can use various standard clients to connect to GreptimeDB. Frontend can also generate different logical plans as per user requests based on metadata, and forward them to Datanode for processing.
Metasrv Metasrv: is the metadata center of GreptimeDB clusters, and its underlying storage is based on etcd. Metasrv is equivalent to the brain of GreptimeDB, storing clusters' metadata and scheduling requests based on different strategies.
Datanode Datanode: like its name suggests, they are the data nodes for GreptimeDB clusters, which receive requests from Frontend nodes and do the actual task of converting them into physical plans for processing. It stores data on remote S3 through its storage engine and maintains data cache based on memory and disk on the node to improve data read and write performance. Datanode is like the "muscle" of GreptimeDB clusters, providing computing and storage services.
A complete GreptimeDB cluster will contain a variety of nodes with different functions and resource requirements, and each node of a different role has multiple replicas, and the number of which changes elastically depending on request loads. Without a unified operation and scheduling system, it would be difficult to operate and maintain a large-scale GreptimeDB cluster. Therefore, greptimedb-operator abstracts a CRD of GreptimeDBCluster for end-users. After users install greptimedb-operator and etcd, they only need a simple YAML configuration file to build a complete GreptimeDB cluster on K8s effortlessly:
YAML
cat <<EOF | kubectl apply -f -
apiVersion: greptime.io/v1alpha1
kind: GreptimeDBCluster
metadata:
name: my-awesome-greptimedb
spec:
base:
main:
image: greptime/greptimedb:latest
frontend:
replicas: 1
meta:
replicas: 1
etcdEndpoints:
- "etcd.default:2379"
datanode:
replicas: 3
EOFFor different clusters, we just need to create different GreptimeDBCluster resources. Once created successfully, greptimedb-operator will monitor this event based on the K8s List-Watch mechanism, and then create a GreptimeDB cluster based on the Spec in the CRD. Once an exception occurs in the GreptimeDB cluster, greptimedb-operator will automatically resolve it, and maintain the cluster in the desired state declared by the GreptimeDBCluster resources.
The abstracted GreptimeDBCluster data models and greptimedb-operator ensure GreptimeDB to integrate well with the K8s ecosystem. We can further integrate other Operator's CRDs, such as Prometheus-operator's, in GreptimeDBCluster, so as to add new functions to greptimedb-operator more seamlessly.
In order to improve the efficiency of releasing and deployment, we also packaged Helm Charts based on greptimedb-operator. Users can add our Helm repository with common Helm commands, making it easier to install greptimedb-operator and GreptimeDB clusters.
We can see GreptimeDB pods are created after a complete GreptimeDB cluster is running successfully on K8s:
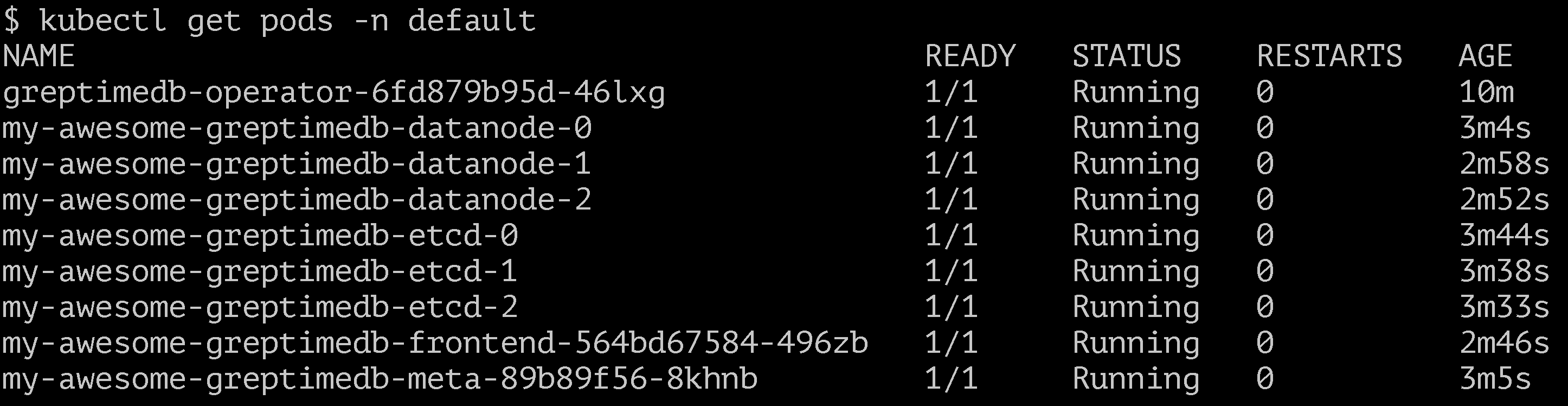
It's not hard to tell that GreptimeDB tends to be microservices under distributed cluster scenarios. Different microservies run on K8s and greptimedb-operator helps with automated operations.
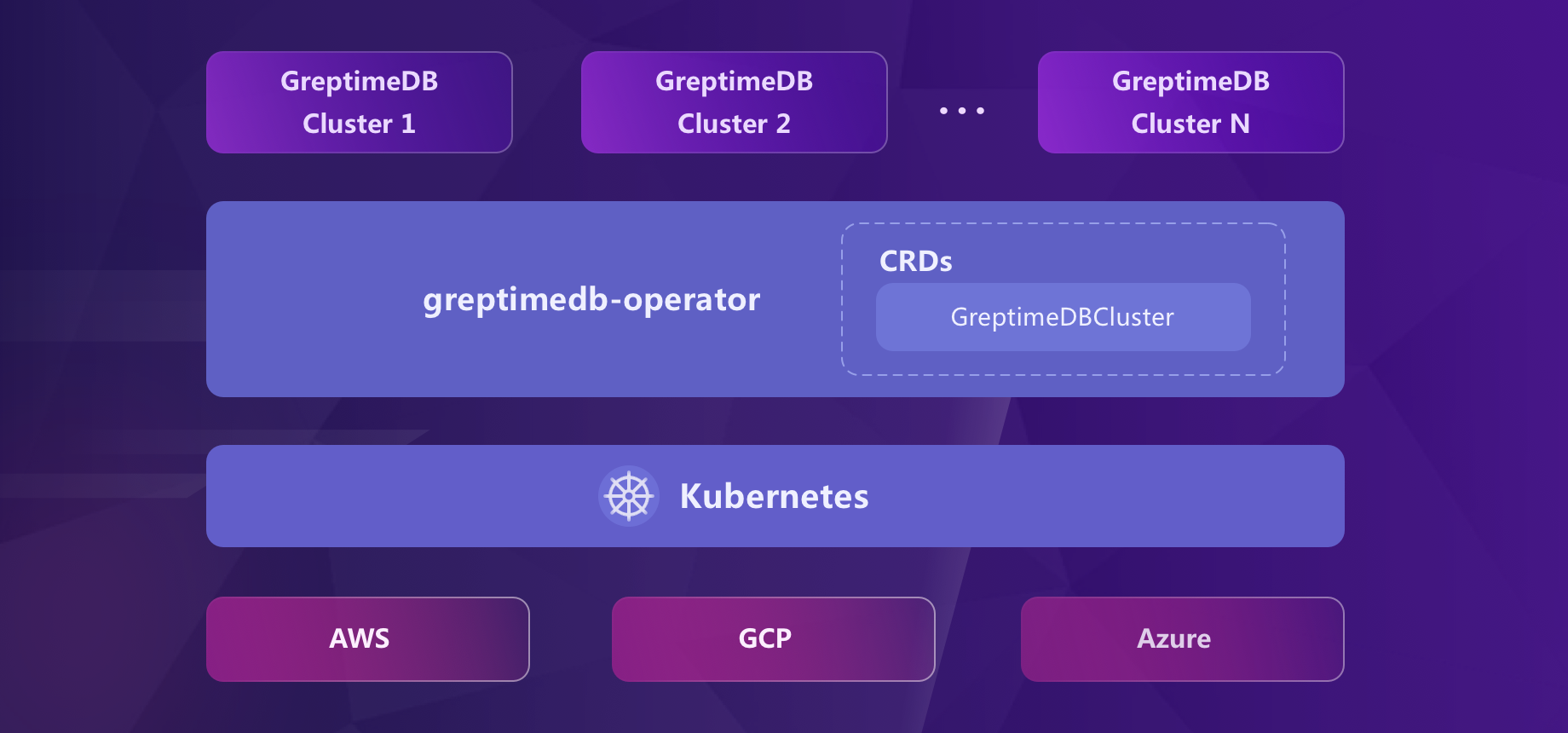
Overall architecture of GreptimeDB as shown below:
Better Command Line Tools
Although we already have the greptimedb-operator to deploy and maintain GreptimeDB clusters, it still has a steep learning curve for many developers. So we developed the gtctl project to make the management of GreptimeDB clusters easier. The gtctl project provides a command line tool gtctl to help users deploy a complete GreptimeDB cluster on a K8s-like environment.
The following command creates a GreptimeDB cluster on K8s named my-awesome-greptimedb.
gtctl cluster create my-awesome-greptimedb
We design gtctl as an extensible All-in-One modern command line tool in the hope that every user can quickly initiate a productive GreptimeDB cluster using gtctl even with little pre-domain knowledge. Furthermore, users can adopt familiar clients or SDK tools to connect with the GreptimeDB clusters directly and use gtctl to do any operations for them, including developing and adjusting.
Future plans
The greptimedb-operator and gtctl projects are still in the early stage, with lots of plans and developments still being iterated.
The maturity of the greptimedb-operator project depends on our continuous accumulation and summary of GreptimeDB operation system. Only with more real-world operation cases of GreptimeDB clusters can we continuously integrate these experiences into our greptimedb-operator project. Therefore, the future development of the greptimedb-operator will mainly focus on improving functional maturation and overall quality, constantly enriching the capabilities of the greptimedb-operator based on the latest features of GreptimeDB.
Like the greptimedb-operator project, we also plan to incorporate the following characteristics in our future versions to improve the overall quality of gtctl.
- Support GreptimeDB cluster management under more environments
We hope that the GreptimeDB cluster can not only run in standard K8s environments but also in the non-K8s Bare Metal environments.
- Support more developer-friendly functions
Besides standard users utilizing gtctl to manage GreptimeDB clusters, we hope that database developers can also use gtctl to debug better as well as making it easier to develop GreptimeDB. To this end, we will add corresponding functions to assist in the debugging and development of GreptimeDB.
- Full plug-in system
We hope that gtctl can further expand its functions with a flexible plug-in system, supporting more differentiated scenarios with customized plug-ins. The gtctl plug-ins can also grow into a sub-ecosystem of GreptimeDB along with the future increase of GreptimeDB application scenarios.
- Integration into the GreptimeDB ecosystem
In the near future, we plan to launch the GreptimeCloud version to enable users to use GreptimeDB as a DBaaS. Users can not only control GreptimeCloud through our Web UI plane but also use the command line to interface gtctl with GreptimeCloud API to manage GreptimeDB on the cloud.
Database operation in the cloud era has long been a systematic and comprehensive challenge which is hard to address with a single technique. We are lucky as the open-source community provides valued opportunities for GreptimeDB to be implemented in various settings, enabling us to practise and improve our work constantly.
As elegant solutions only emerge through the hard work of real-world deployment, we call for all developers' consideration to try greptimedb-operator and gtctl projects. Your participation in our community building will lead to a more powerful GreptimeDB.
[1] https://landscape.cncf.io/ [2] https://www.cncf.io/wp-content/uploads/2021/12/Q1-2021-State-of-Cloud-Native-development-FINAL.pdf
About Greptime
Greptime is founded in April 2022 with two main offerings: GreptimeDB and GreptimeCloud. Greptime DB is an open-source, cloud-native time series database with powerful analytical features; GreptimeCloud is a SaaS solution built on GreptimeDB. We are passionate about helping users find real-time values from their time series data with our tools.
If you have any insights or suggestions, please contact [email protected] or join our Slack channel for more information and discussion.




