On this page
Procedure is a new feature currently under development in GreptimeDB, aiming to improve the fault tolerance of system execution when performing multi-step operations. This article will briefly introduce the Procedure framework and why we need to develop this feature.
Why Procedure Needed
To facilitate the understanding of the problem Procedure intends to solve, let us imagine that we are presently celebrating Thanksgiving Day and preparing a large roasted turkey for one of the most significant feasts of the year. Preparing a traditional roast turkey can be a delightful experience, especially during festive occasions. However, this dish has a very complicated cooking process involving many preparing sections, each containing several steps. For instance, before seasoning the turkey with salt and pepper, it is essential to remove its giblets and neck, rinse the interior, and thoroughly dry it.

In an ideal world, all we need to do is follow the recipe book and a perfect roasted turkey comes out of the oven. However, in the real world, many unforeseen circumstances can easily disrupt the process, be it a sudden phone call, a needy child or pet, or a power outage. The next time we resume our cooking, it's easy to forget where we left off and what comes next. For a complex dish like roasted turkey, even small mistakes may ruin the whole dish. After all, no host wants their guests to discover any unsavory surprises, such as giblets, concealed within the turkey.
Similarly, our system may also encounter this issue. When users initiate an operation in the database, especially when executing a DDL (Data Definition Language), it often involves modifying multiple state data in the database.
- These modifications to the state data follow a specific order, similar to preparing a multi-step dish where each step is irreversible.
- The operation is considered successful only after all modifications are executed.
- If the operation is terminated halfway, some of the database data will be inconsistent.
Why does DDL involve modifying data in multiple states? That is because GreptimeDB was designed with the goal of a distributed system from day one. The data in a table can be divided into multiple units and distributed across different nodes. We use the following components to record the tables present in the system and the metadata of each table:
CatalogManagerrecords all the tables in the system.TableManifestrecords the metadata of the tables, including the table structure and other information like the number ofRegionin a table.RegionManifestrecords the metadata of theRegion, for example, the structure of theRegionand the data files contained, etc.
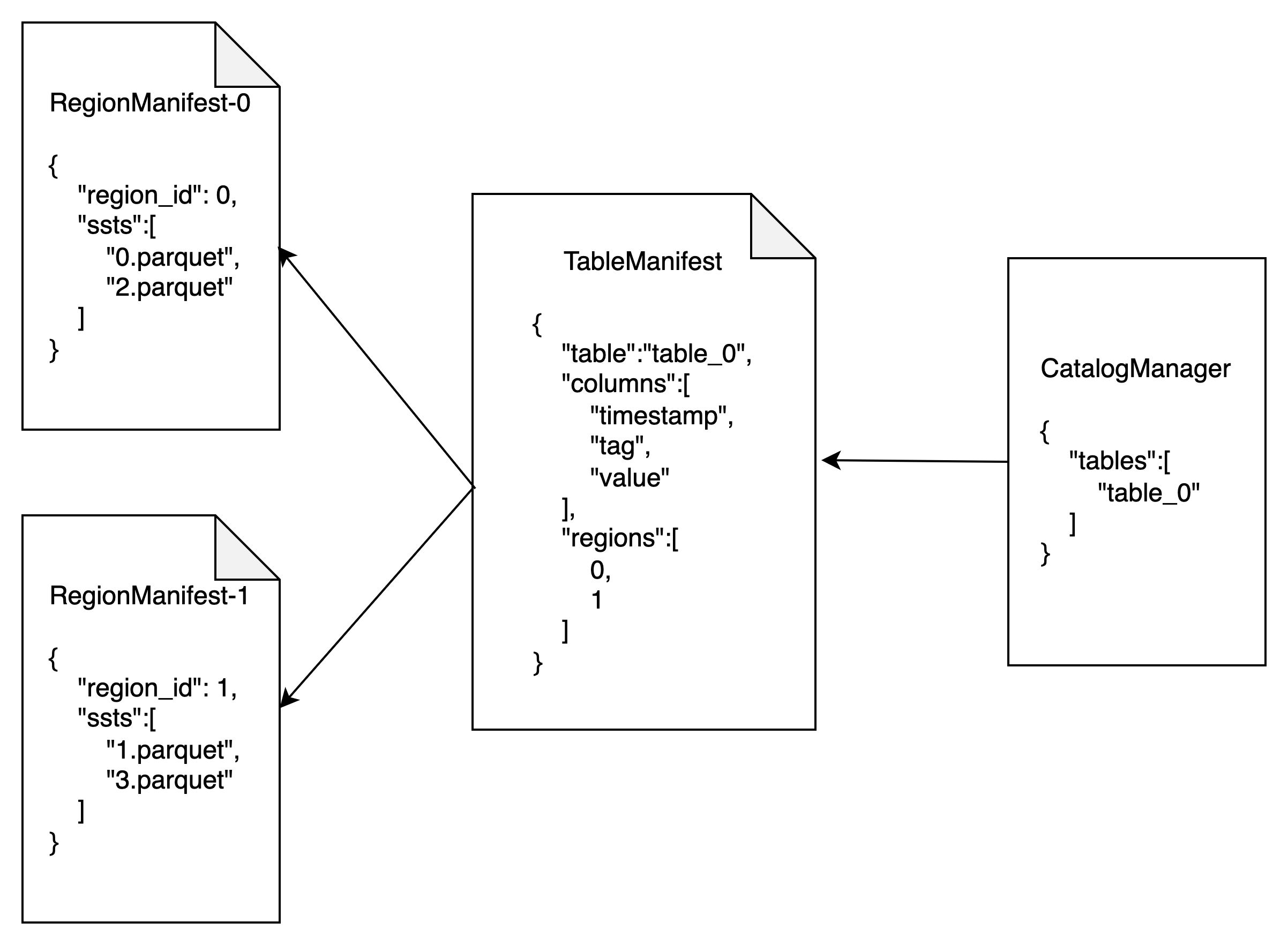
Let's take CREATE TABLE operation as an example: When creating a table, the database needs to perform the following actions in sequence:
- Create a
RegionManifestfor eachRegionand persist the metadata of theRegion. - Create a
TableManifestand write the metadata of the table. - Write the record of the table to
CatalogManager.
Potential process panics or restarts, machine crashes, or network turbulence can lead to failed requests when performing the above operations. When these situations occur, the table creation operation will be interrupted, causing the state of the database to be inconsistent. For example, the metadata has been written into TableManifest, but the table record may not be found in CatalogManager. Naturally, there are actually more complicated cases than creating tables, such as deleting table DROP TABLE.
Some distributed relational databases can solve the above problem through distributed transactions. However, GreptimeDB does not support transactions currently, and we do not want to introduce complex distributed transactions and schema change mechanisms like Google F1. Therefore, we introduce a Procedure framework similar to HBase ProcedureV2 to solve this problem.
Procedure framework
The role of the Procedure framework is to help execute multi-step operations in the system, ensuring that they are completed or can be rolled back. Our Procedure framework draws inspiration from two similar frameworks, HBase ProcedureV2 and Accumulo FATE.
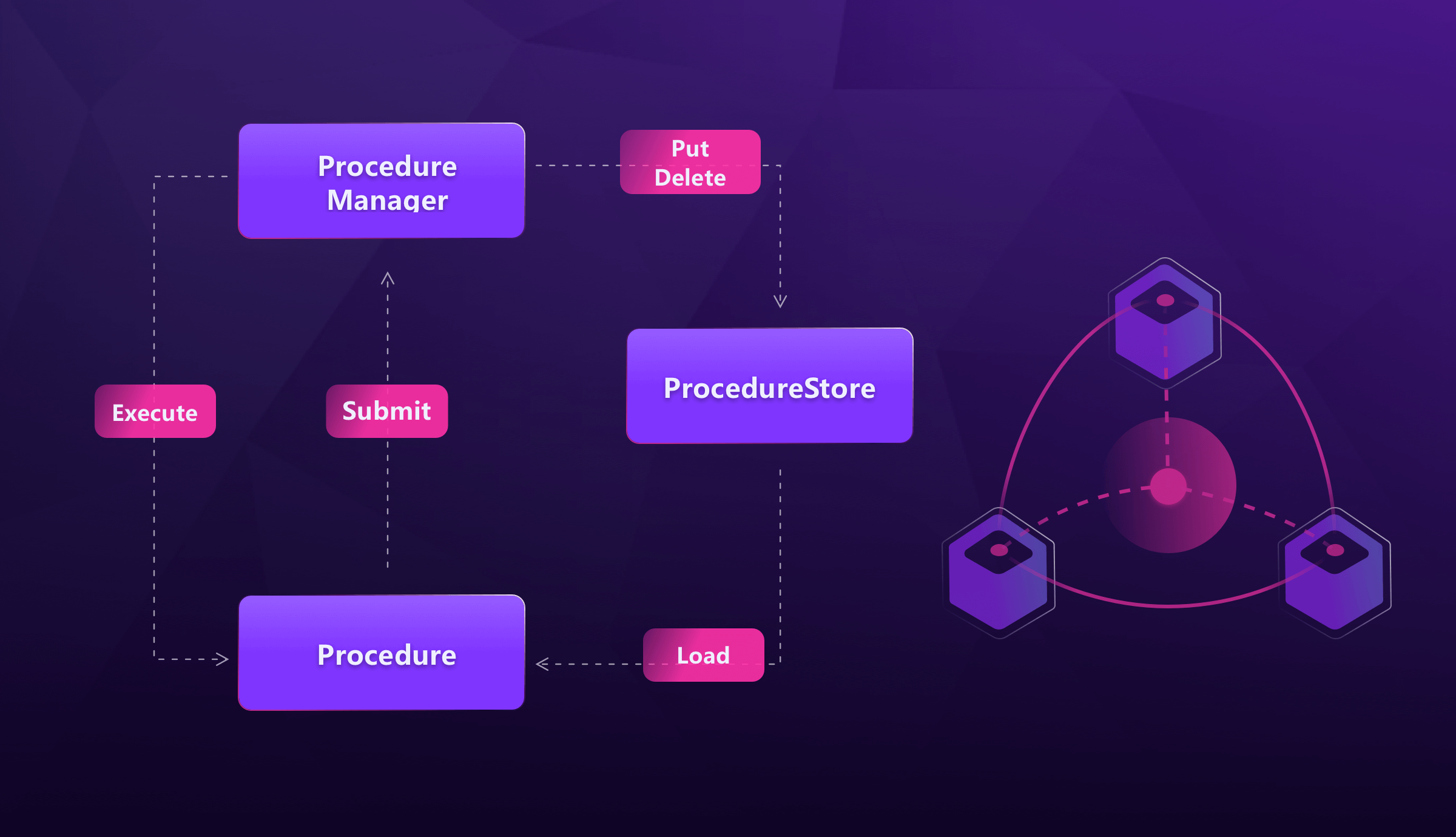
The procedure framework consists of the following primary components:
Procedure:a set of operations to executeProcedureStore: a storage layer for persisting the procedure stateProcedureManager: the runtime to runProcedures.
Procedure
A Procedure represents a set of operations to be performed step-by-step.
- Each procedure has a unique ProcedureId to identify itself.
- Procedure is similar to a state machine, where every step executed leads to the next state until the end.
- It should have the capability to serialize its current state.
- Every step needs to be idempotent to make sure that each step can be retried.
A procedure may need to create some sub-procedures to process its subtasks. Similar to the process of preparing a roast turkey, the step of preparing the seasoning sauce may actually include several steps. So we can treat the sauce preparation process as a sub-procedure. Doing so allows us to execute more complex operations by combining multiple sub-procedures.
ProcedureStore
ProcedureStore records the execution progress of procedures, acting as object storage to store status data files in a specified format:
Bash
/procedures/{PROCEDURE_ID}_000001.step
/procedures/{PROCEDURE_ID}_000002.step
/procedures/{PROCEDURE_ID}_000003.commitEach step file records the state of a Procedure after it has been executed. Upon completion of the Procedure, the ProcedureManager records a commit file to indicate that the Procedure has been completed.
ProcedureManager
For each step executed in a Procedure, ProcedureManager persists and stores the Procedure's state in the ProcedureStore. ProcedureManager can be considered as the runtime of the Procedure, with other responsibilities like:
- Continuously retrying the Procedure in the event of recoverable errors, such as network issues
- Managing all current Procedures
- After restarting the process, recovering and re-executing unfinished Procedures from the ProcedureStore
- Coordinating Procedures' access to resources
Solving issues during the table-creating process
To coordinate the access of resources by Procedures, it is necessary to introduce a locking mechanism into the Procedure framework, ensuring that the resource can only be modified by one Procedure at a time. For example, if a Procedure needs to create a table, it must first successfully acquire the lock of that table before continuing to operate. Otherwise, it must wait for the previous Procedure holding the lock to release it. If multiple Procedures attempt to create the same table simultaneously, only one can succeed, avoiding potential conflicts.
With the Procedure framework in place, we can implement the table creation operations as a Procedure submitted to the ProcedureManager for execution. This Procedure can include the following steps: create a Region, create the table, and register the table to CatalogManager. In each step, we need to ensure idempotency. For example, if a Region has already been created, it is unnecessary to create it again.
The entire Procedure framework is like a powerful management system in the kitchen:
- A Procedure is like a dish order submitted to the kitchen, and the ProcedureId is the serial number of the dish.
- Each dish has an explicit checklist to track each step in the production process, and the ProcedureStore is used to record the progress.
- The ProcedureManager is like the assembly line of the entire kitchen, continuously preparing dishes and updating the records based on the orders.
The Procedure framework has completed the RFC, prototype validation, and the development of the standalone Procedure framework.
We have already implemented table creation Procedures based on the standalone Procedure framework and are currently developing Procedures for ALTER TABLE.
Future plans
We will continue to iterate and improve the Procedure framework, some of the plans including:
- Implementing Procedures for other DDL operations, such as
ALTER TABLEandDROP TABLE, etc. - Implementing a distributed Procedure framework. We plan to run the Procedure framework on the "brain" of the entire cluster, Metasrv, which will schedule the execution of Procedures in the distributed environment.
- Currently, the table creating process in GreptimeDB is different under standalone and distributed environments, making it difficult to implement. We will explore unifying the process for both modes through the Procedure framework.
- Supporting rollback operations for Procedures. Though HBase's ProcedureV2 framework supports rollback, the priority to support rollback Procedures is relatively low in GreptimeDB, it has yet to be implemented.
Conclusion
GreptimeDB introduces the Procedure framework to help track the progress of multi-step operations in the database and automatically retry failed operations to ensure their completion. Since Procedures are not transactions and cannot provide transaction isolation, the effects of a Procedure during its execution are visible to other Procedures. However, this is tolerable for us currently.
This article only provides a brief introduction to the Procedure framework. Interested readers can refer to the Procedure's Tracking Issue for further information and details.




