
On this page
We're thrilled to introduce greptimedb v0.2, a fantastic new version of our database, packed with improvements and features that we can't wait for you to try out!
Ever since the release of GreptimeDB v0.1, with the help of the community, GreptimeDB is steadily moving towards the set milestone according to plan. Below are some of the important feature updates:
- Optimize data import and export to help users get started quickly;
- Improve PromQL compatibility for lower cost Prometheus replacement;
- Write performance optimization to meet more complex usage scenarios;
- Refactor the user documentation for a more user-friendly experience;
- Dashboard with playground for quick start of the product;
- Many other optimizations related to database reliability and security.
Behind these deliveries are 233 merged PRs, 101 optimizations, and 42 fixes involving 687 file changes, 44,548 lines of code modification, 41 contributors, and over 2,600 followers.
Special thanks to the community and our team, now let's review the main content of v0.2.
GreptimeDB v0.2
Features
- Support
COPY TOandFROMstatementCOPY TOandCOPY FROMcommands are often used as data migration or backup tools. GreptimeDB not only supports exporting data to local disks or importing data from local disks, but also supports object storage such as S3.
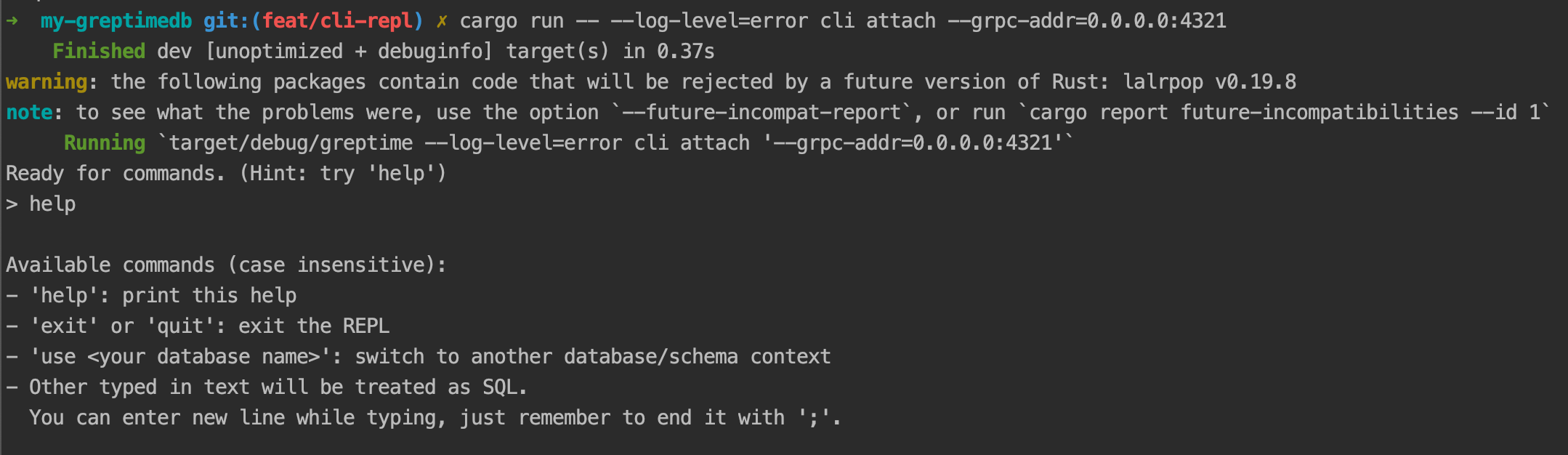
- A simple REPL for degugging
- Before removing SQL interface from Datanode, we need something as a substitute to mysql-cli. This REPL can serve the purpose. It's largely inspired by InfluxDB IOx . Simple, yet powerful, has history and hints, and can directly execute SQL via our grpc interface.
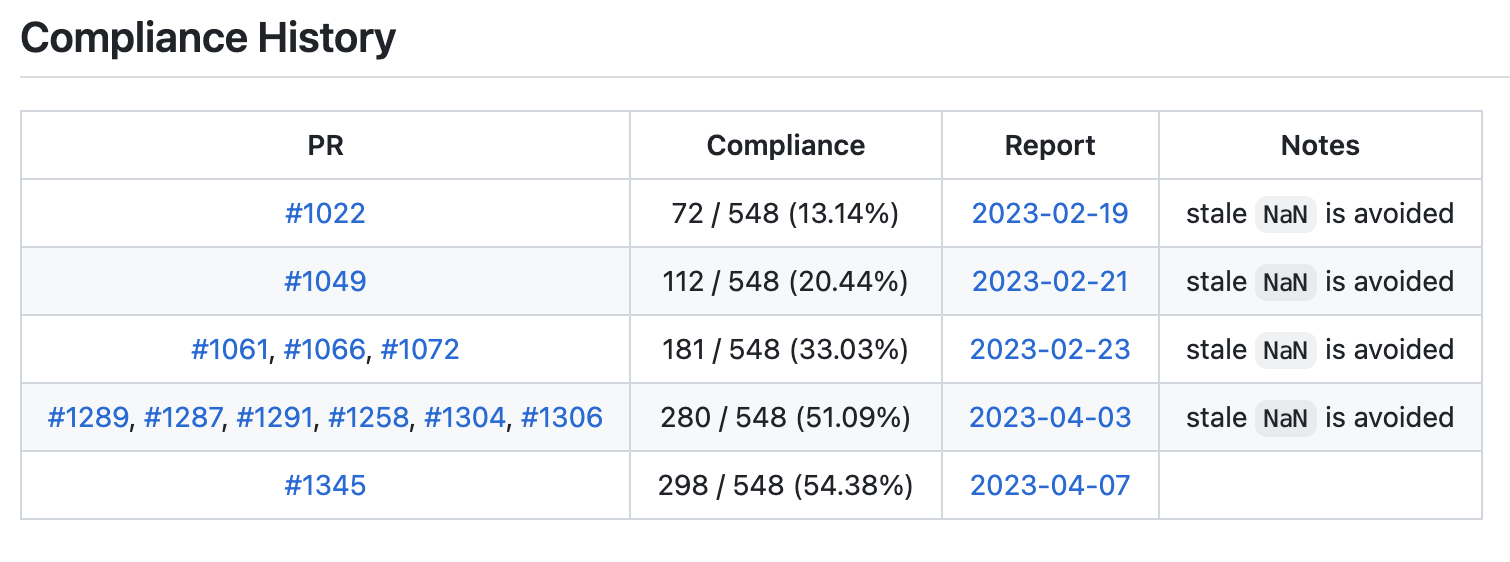
- Have passed over 50% of Prometheus’s compliance tests
- We have initially supported PromQL and passed over 50% of Prometheus’s compliance tests, which greatly improved PromQL compatibility. To further improve its compatibility, we have created this issue to gathered all the PromQL compatibility-related PRs and tasks for easier progress tracking.
We have enhanced Timestamp to support specifying precision when creating tables, following the fractional seconds syntax in MySQL. Fractional seconds option now accepts:
- 0: no factional seconds, time unit is
TimeUnit::Second - 3:
TimeUnit::Millisecond - 6:
TimeUnit::Microsecond - 9:
TimeUnit::Nanosecond
Now we can specify the time precision to microseconds like:
sql
mysql> create table demo (ts timestamp(6) time index, cnt int);Query OK, 0 rows affected (0.05 sec)Procedure on Create & Alter Table
- The Procedure framework is designed to help execute multi-step operations and ensure that they can be completed or rolled back. Our Procedure framework was inspired by two similar frameworks, HBase ProcedureV2 and Accumulo FATE.
- Currently, the procedures for
CREATE TABLEandALTER TABLEhave been completed. We plan to gradually switch to the procedure framework after the completion of procedure forDROP TABLE.
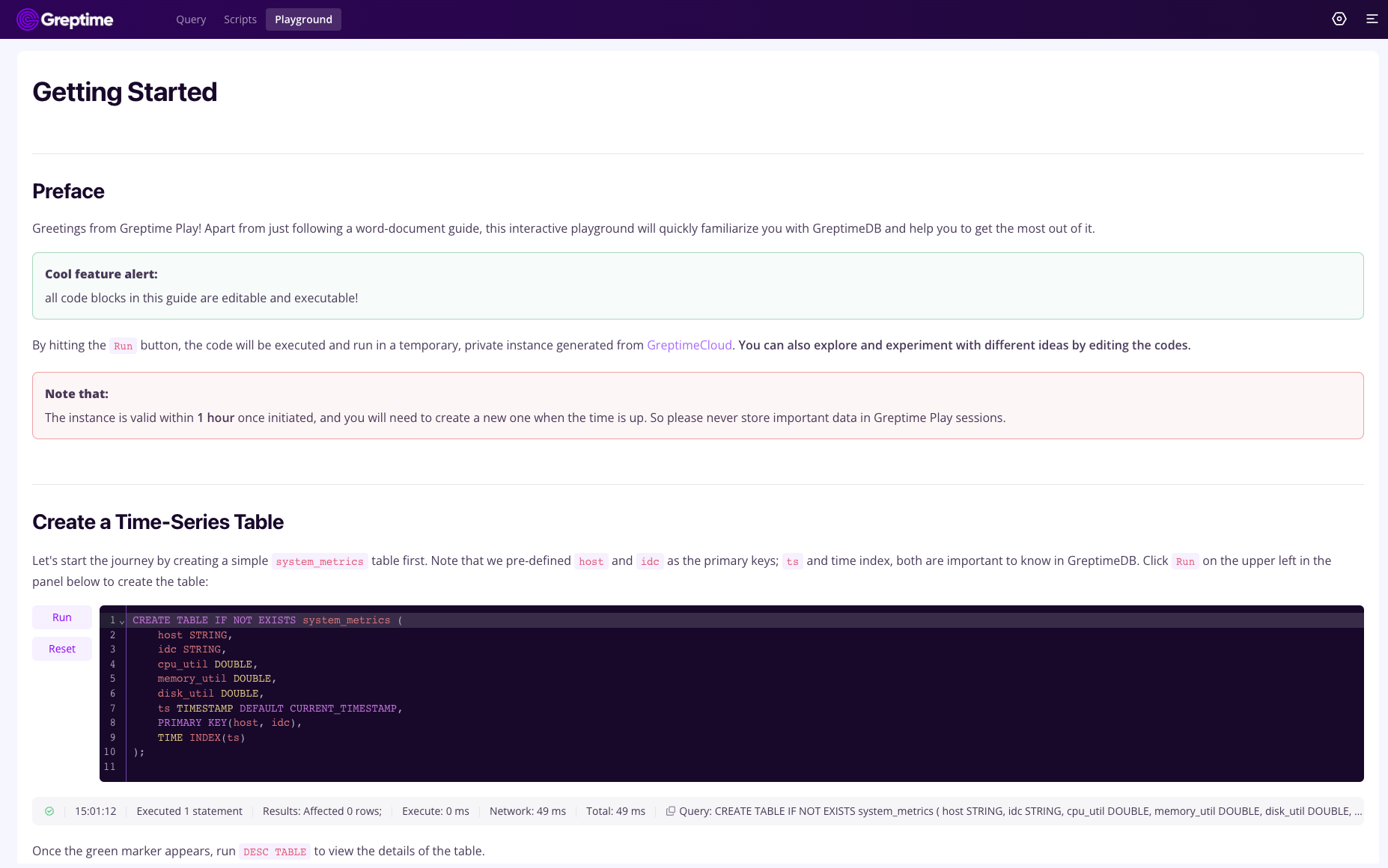
The new Playground module is now available, offering the ability to use interactive documents for interactive use of databases within the document.
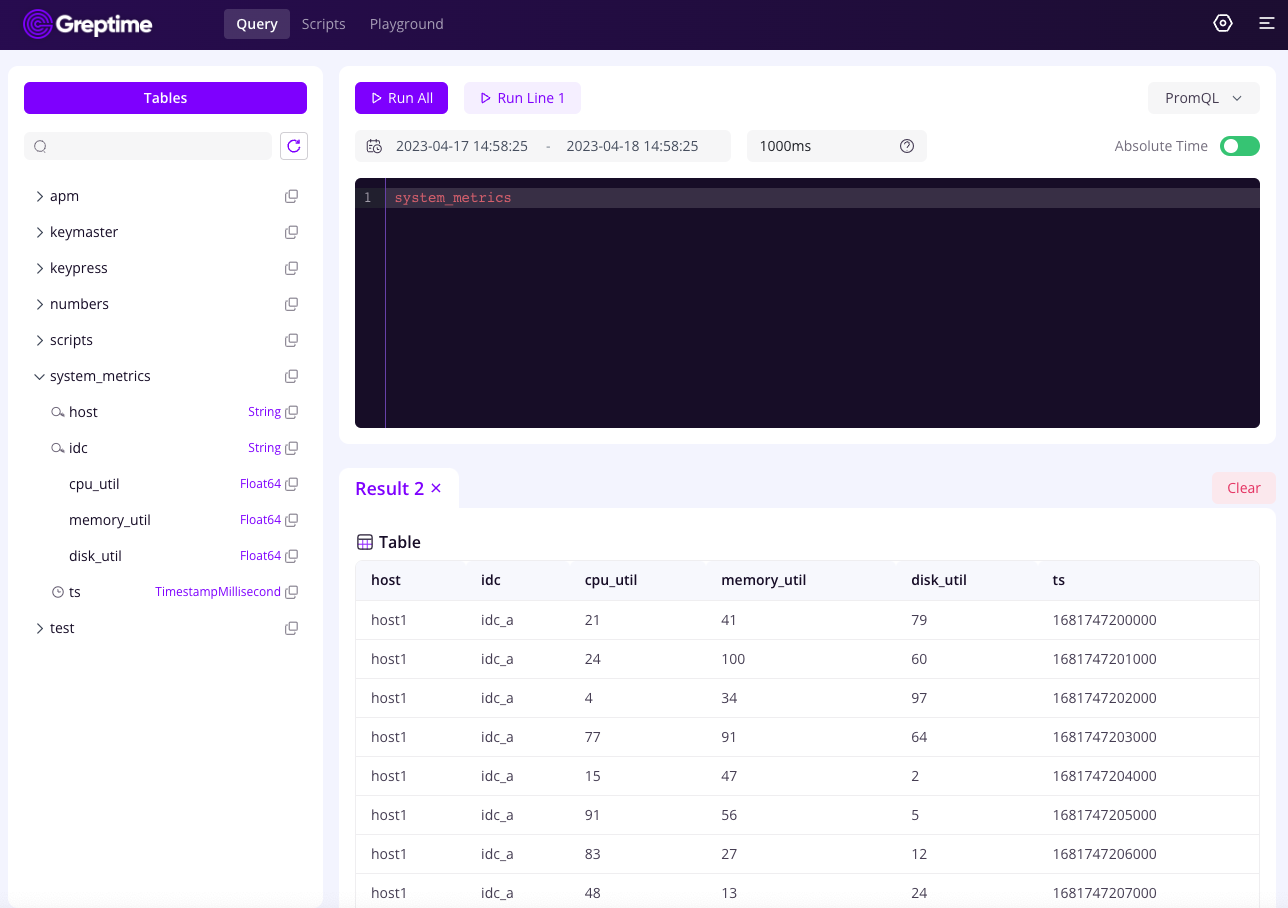
Initially support the PromQL query.
Others
DELETEstatement enhanced with where condition supported.- Supports Region manifest checkpoint to control the disk usage and speed up the startup.
- Supports running python script in distributed mode.
Protocol
- Adds a private gRPC protocol to improve write efficiency
- To further enhance write performance, we have incorporated a private gRPC protocol alongside ArrowFlight. This protocol supports Unary Call and Client Streaming Call to boost the efficiency of data writing. Meanwhile, ArrowFlight remains dedicated to improving query performance.
Clients:
- Adds streaming write API for Java SDK to better support high-throughput data writing.
- New Golang SDK added, feel free to try it out.
Refactor
We hoped to keep all protocol parsing-related work in the Frontend layer, including parsing into logical plans, so we refactor the protocol parsing layer.
For some reason, SQL Parser was also kept in the Datanode previously. This compromised design required a significant amount of maintenance effort. For example, we have to make modifications in both places every time a new feature is introduced. Therefore, we have decided to clean up this technical debt.
Write performance optimization
In GreptimeDB v0.2, we optimized the ability of batch writing for metrics collection scenarios. Compared to the SQL interface, the batch writing API can improve the write throughput by around 20 times and can achieve a write throughput of up to 380,000 points per second on a single core in real-life business scenarios. (benchmarked with AMD Ryzen™ 7 7735HS)
The plan for v0.3
- Query performance
- In version 0.2, we focused on optimizing the write performance. In version 0.3, we'll shift our emphasis to query performance. We will start with some key query scenarios and also include optimizations on data structures and indexes.
- Distributed capability
- Beginning with version 0.3, emphasis will be placed on the distributed capability. The main focus of our future work will be on three aspects: high availability, functionality, and user experience. We have a long-term iteration plan, with monthly iterations focusing on one topic. For more details, please see our GitHub Projects.
Acknowledgement
A big THANK YOU to all the contributors within our community. Your suggestions, bug fixes, and code contributions have consistently reinforced and propelled this project forward.




























