
On this page
Our team has performed a series of refactoring and improvements on the latest release GreptimeDB version 0.4, including a major upgrade to the underlying time-series data storage engine, Mito. In this version, we basically rewrote the entire storage engine, such as refactoring the engine's architecture, reimplementing some core components, adjusting data storage formats, and introducing optimized solutions tailored for time-series use cases. The overall performance of GreptimeDB v0.4 has been improved significantly with certain queries experiencing over a 10 times increase in performance compared to v0.3.
In this article, we will highlight the refactorizations and improvements to Mito in v0.4, hoping to help users gain a better understanding of GreptimeDB's newest storage engine.
Architectural Refactoring
The most significant refactor of our storage engine was the adjustment made to the engine's writing architecture. The following diagram illustrates the previous architecture in v0.3:
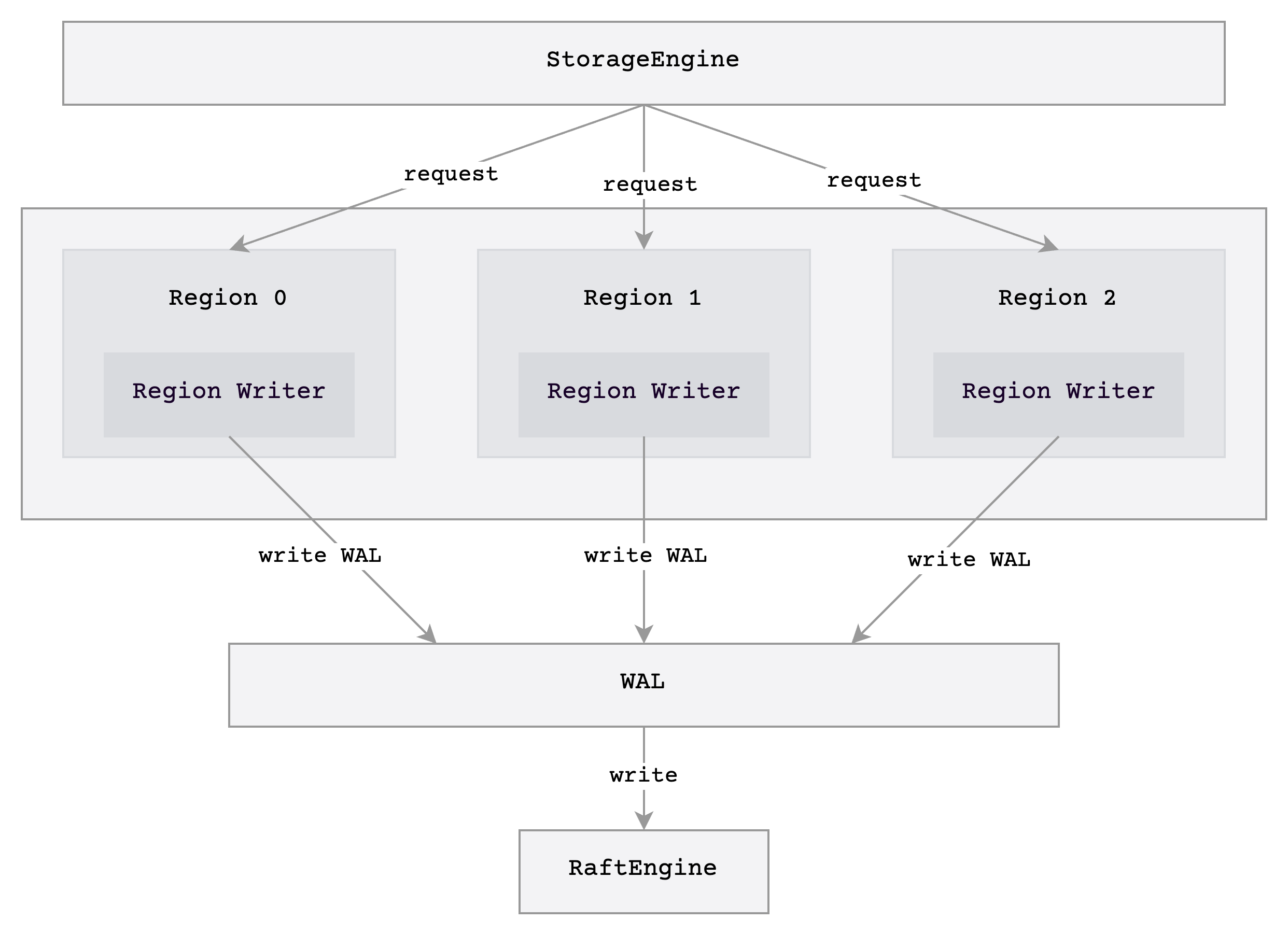
In the digram, region in the image can be considered as a data partition in GreptimeDB, which is similar to region in HBase[1]. Our storage engine uses LSM-Tree[2] to store data, and each operation requires data to be written sequentially to the Write-Ahead Log (WAL)[3] and the memtable[4] of each region. We omitted the part related to writing to the memtable in the diagram to keep the focus clear.
In the previous architecture, each region has a component called RegionWriter responsible for writing data separately. This component uses different locks to protect each internal state, meanwhile, to prevent queries from blocking writes, some states are maintained by atomic variables, which only require locking during updates. Although this approach is relatively simple to implement, it has the following issues:
- Difficult for batching;
- Hard to maintain due to various states protected by different locks;
- In the case of many
regions, write requests for WAL are dispersed.
In v0.4, below is the architectural diagram of Mito after refactorization:
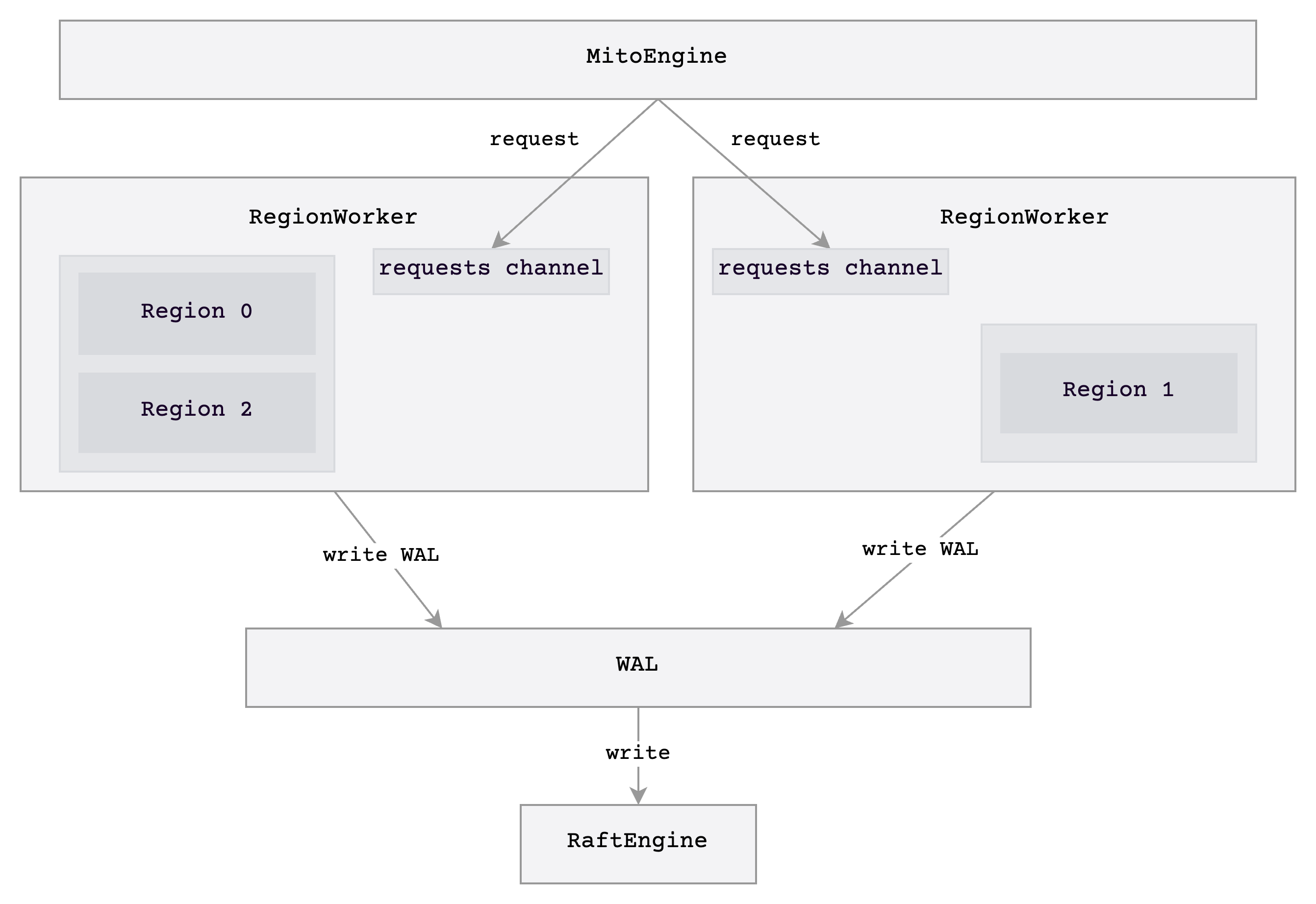
In the new architecture, the storage engine is pre-assigned with multiple write threads: RegionWorker is responsible for handling write requests, and each region is managed by certain fixed threads. Below are some highlighted features:
RegionWorkersupports batching, which greatly improves write throughput.- Write requests are only executed in
RegionWorker, no longer need to be concerned with changes due to high concurrency. Therefore, we can easily get rid of some locks, and simplify concurrency processes. - WAL write requests of different
regions are aggregated byRegionWorker.
Optimization of Memtable
The memtable in the previous storage engine was not optimized for time series use cases, but simply wrote data in BTree as rows. This approach requires large memory and the read/write performance isn't ideal. Among which, large memory has caused many problems:
- Flush is triggered because
memtableis quickly filled. - The limited volume of data results in excessively small flushed files, which diminishes the efficiency of subsequent query and compaction.
In v0.4 we re-implemented the memtable of the engine, with a focus on improving storage space utilization.
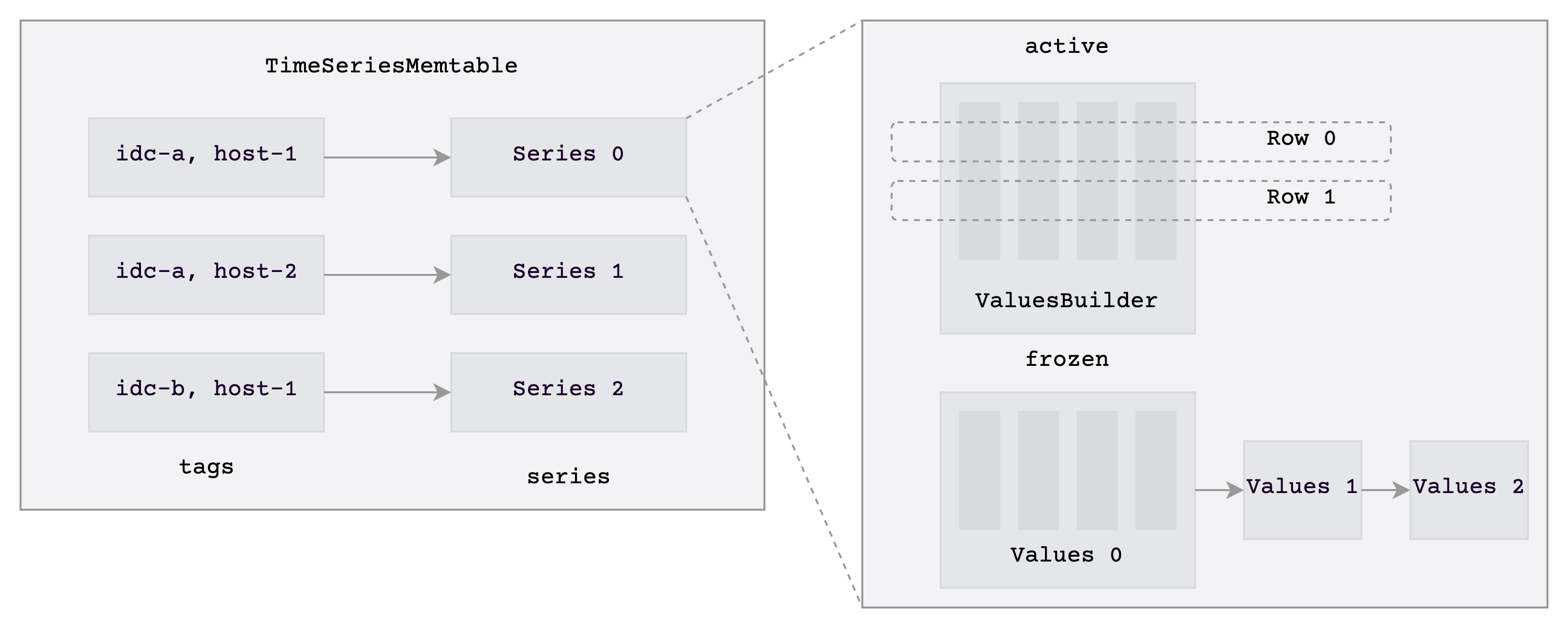
The new memtable has below features:
- For the same time series[5], we only store its tags/labels once.
- The data of one time series is saved in the structure of one
Series, at the same time providing a time-series-level lock. - We store data column-wise and divide it into two kinds of buffers:
activeandfrozenbuffers. - Data is written in the buffer of
activeand transformed to the immutable buffer offrozenwhen it is queried. When reading an immutable buffer, it is also not necessary to continuously hold the lock, reducing lock contention for read and write operations.
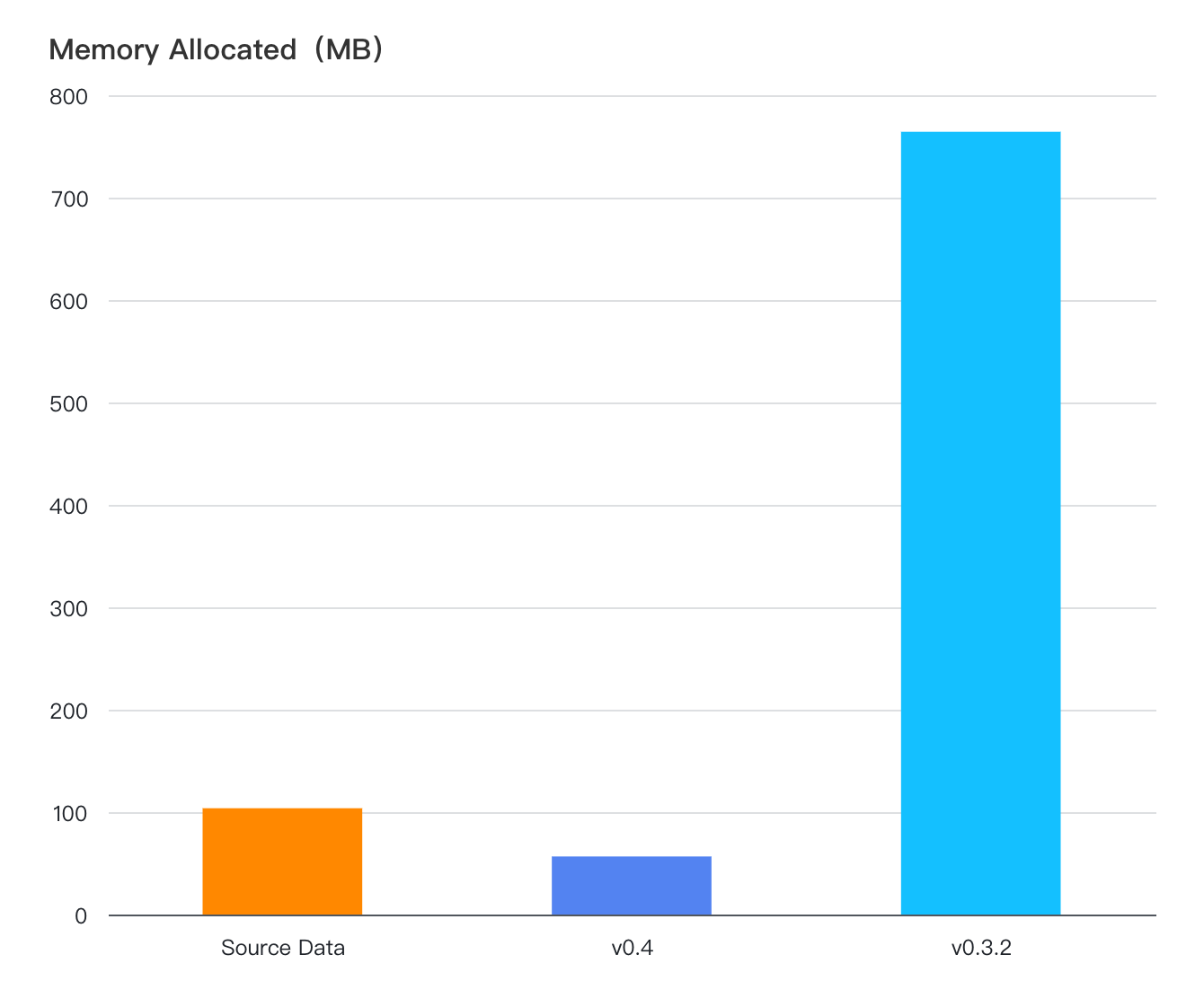
In our testings, after importing 4,000 time series totaling 500,000 rows of data into the memtable, the new memtable can save more than 10 times memory compared to the old memtable.
Storage Format Adjustment
We also made adjustments to the data storage format in v0.4 in response to the uniqueness of time series use cases. Each time a query is made, we need to retrieve all the columns of tags, and later to determine whether the data belongs to the same time series by comparing them. To improve query efficiency, we encode the tags column of each row to obtain a complete __primary_key and directly store the __primary_key as a separate column, as shown in the __primary_key column in the diagram below. We perform dictionary encoding on the __primary_key column to reduce storage.
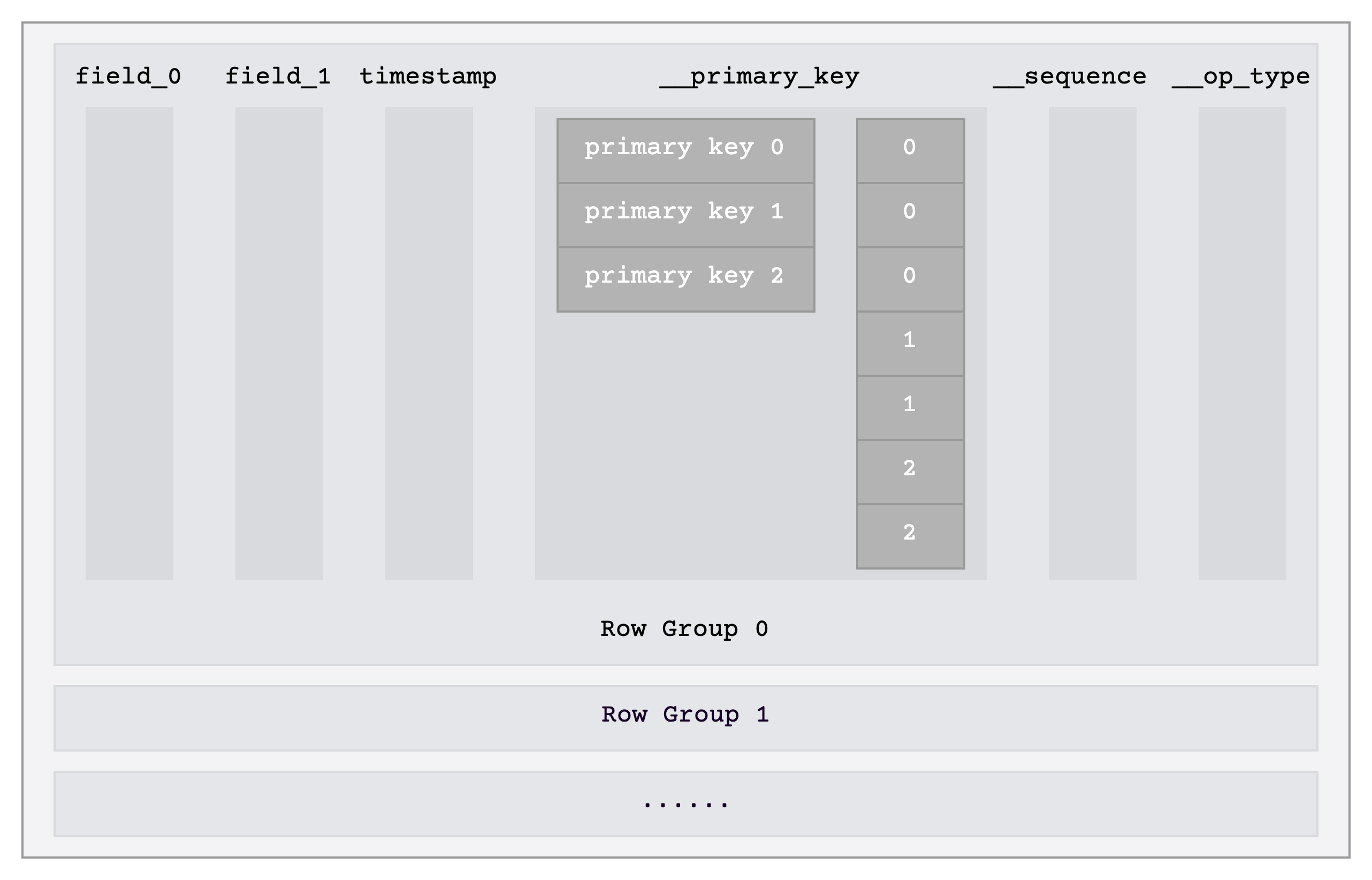
The advantages of this approach include:
- Each query only needs to read the
__primary_keycolumn to retrieve data from all tag columns, reducing the number of columns that need to be read. - In a time-series use case, directly dictionary encoding
__primary_keyproduces good compression results. __primary_keycan be compared directly.- File scanning speed is improved 2-4 times.
Benchmark
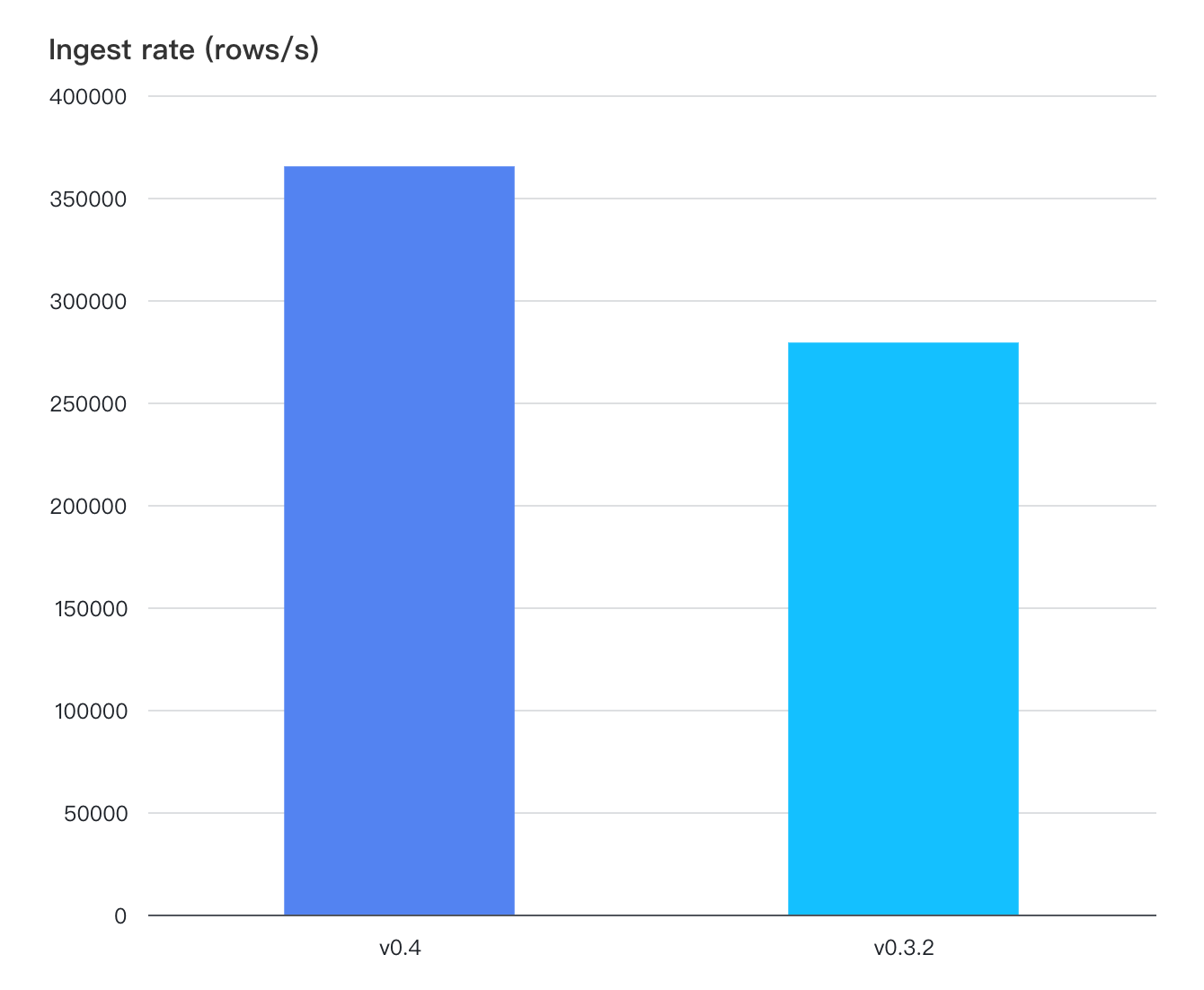
The read and write performance of v0.4 are both improved in TSBS[6] testing. In detail, the write performance of TSBS is improved by 30% with batching after RegionWorker is introduced.
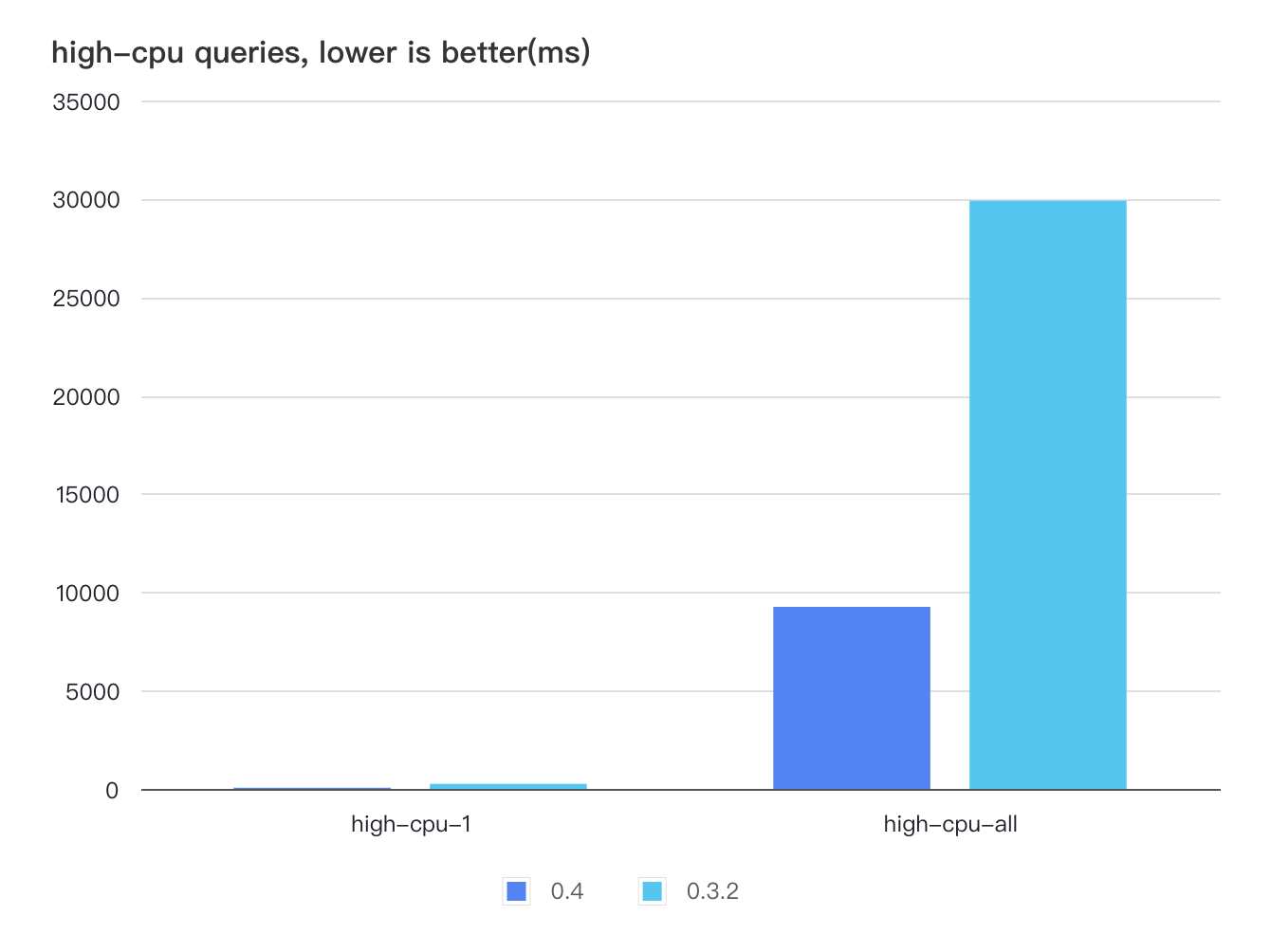
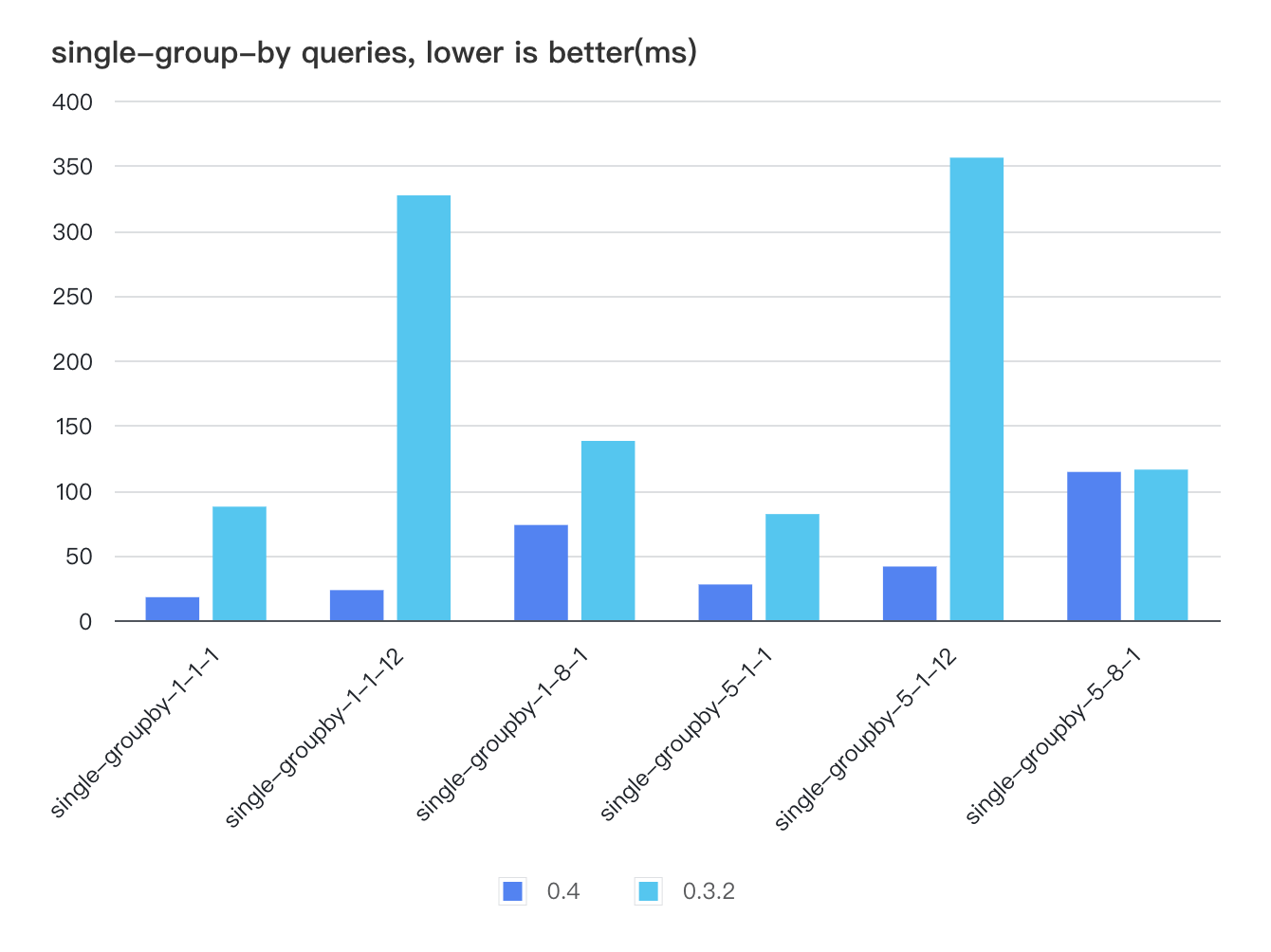
In terms of querying, we have optimized the storage format and data scanning paths, resulting in improved data scanning performance. For scenarios in TSBS that require scanning large amounts of data, the query speed of v0.4 is several times faster than v0.3. For instance, in high-cpu and double-group-by scenarios, the storage engine may need to scan all data within a certain time range and v0.4 is 3 to 10 times faster than v0.3.
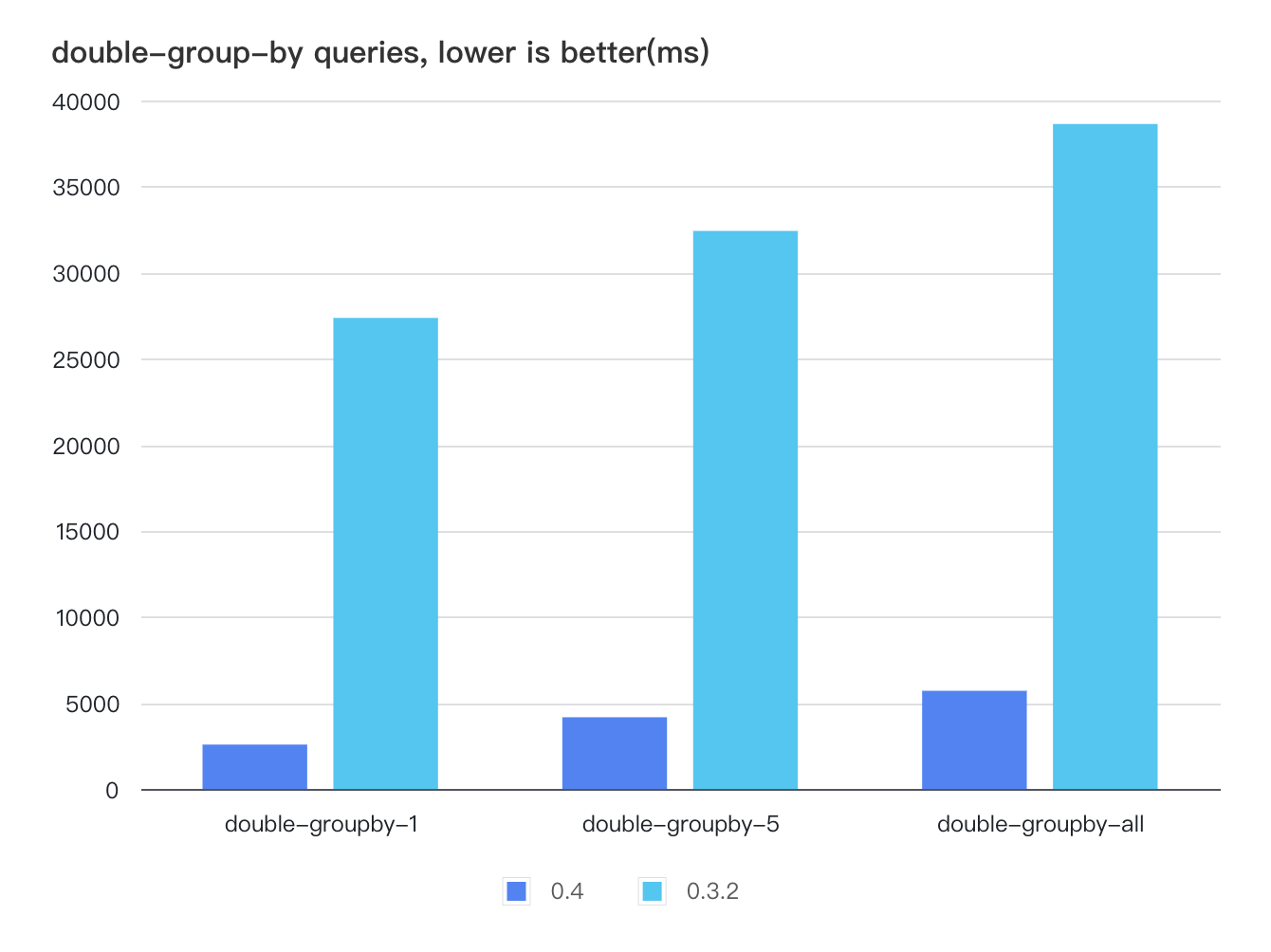
single-groupby-1-1-12, a scenario in single-group-by Querying, requires Querying data for a continuous of 12 hours, and v0.4 is 14 times faster than v0.3.
Summary
In GreptimeDB 0.4, we refactored and improved the time-series storage engine Mito, achieving significant performance enhancements. This article only provides a brief overview of some of these optimizations. Currently, our work on optimizing Mito engine is not yet complete, and there is still plenty of room for improvements. Please keep following our code repository for the latest updates.
Reference
[1]. HBase Overview: https://hbase.apache.org/book.html#arch.overview
[2]. LSM-Tree: https://en.wikipedia.org/wiki/Log-structured_merge-tree
[3]. WAL: https://en.wikipedia.org/wiki/Write-ahead_logging
[4]. memtable: https://github.com/facebook/rocksdb/wiki/MemTable
[5]. Time Series: http://opentsdb.net/docs/build/html/user_guide/query/timeseries.html
[6]. TSBS: https://github.com/greptimeTeam/tsbs




