On this page
In this sharing, we discuss a paper by Dominik Durner, Viktor Leis, and Thomas Neumann from the Technical University of Munich (TUM), published in July 2023 in PVLDB (Volume 16 No.11): Exploiting Cloud Object Storage for High-Performance Analytics.
Paper link: https://www.vldb.org/pvldb/vol16/p2769-durner.pdf
Abstract
...Our experiments demonstrate that even without caching, Umbra with integrated AnyBlob can match the performance of state-of-the-art cloud data warehouses that utilize local SSDs for caching, while also enhancing resource elasticity...
When developing our open-source cloud-native time-series analytical database GreptimeDB, we found this paper exceptionally beneficial. It primarily focuses on performing high-performance data analytics on object storage, with several conclusions providing clear direction for our engineering practices.
Introduction to AWS S3
AWS S3's storage cost is $23 per TB per month, offering 99.999999999% (eleven nines) of availability. It's important to note that the final cost also depends on the number of API calls and cross-region data transfer fees.
The bandwidth for accessing S3 can reach up to 200 Gbps, depending on the instance's bandwidth. While the original text in the Introduce section mentions 100 Gbps, later sections state that on AWS C7 series models, the bandwidth can fully reach 200 Gbps.
The paper identifies the following challenges with AWS S3:
- Challenge 1: Underutilization of bandwidth
- Challenge 2: Additional network CPU overhead
- Challenge 3: Lack of multi-cloud support
Based on our experience, the importance of these challenges is in the order of 1 > 2 > 3
Characteristics of Cloud Storage (Object Storage)
Cloud storage (object storage) typically offers relatively low latency (ranging from several milliseconds to a few hundred milliseconds depending on the load size) and high throughput (capped by EC2 bandwidth, which can go as high as 200 Gbps on 7th generation EC2 models), making it suitable for large-scale data read and write operations.
In contrast, Amazon Elastic Block Store (EBS) usually provides lower latency (in the order of single-digit milliseconds). However, its throughput is lower than cloud storage, often by one or two orders of magnitude.
Latency
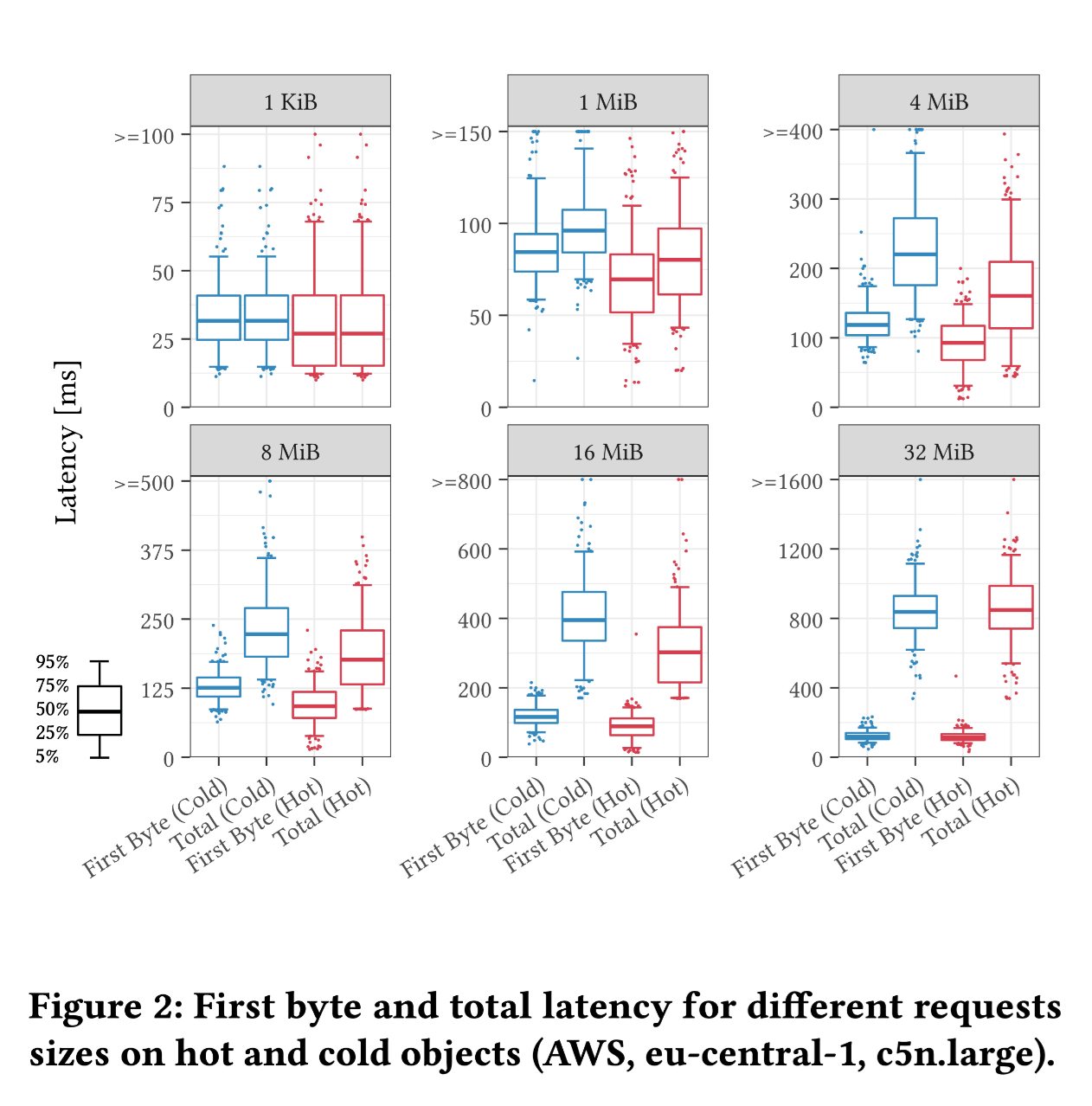
For small requests, first byte latency is a decisive factor.
In the case of large requests, experiments ranging from 8 MiB to 32 MiB showed that latency increases linearly with file size, ultimately reaching the bandwidth limit of a single request.
Regarding hot data, we use the first and the twentieth requests to represent scenarios of cold and hot data requests, respectively. In hot data request scenarios, latency is typically lower.
In GreptimeDB, the average latency data in the data file reading scenarios are as follows:
- For operations involving reading Manifest Files averaging less than 1 KiB, the expected latency is around 30 ms (p50, Cold) / ~ 60 ms (p99, Cold).
- Reading an 8 MiB Parquet file would take ~ 240 ms (p50, Cold) / ~ 370 ms (p99, Cold).
Noisy neighbors
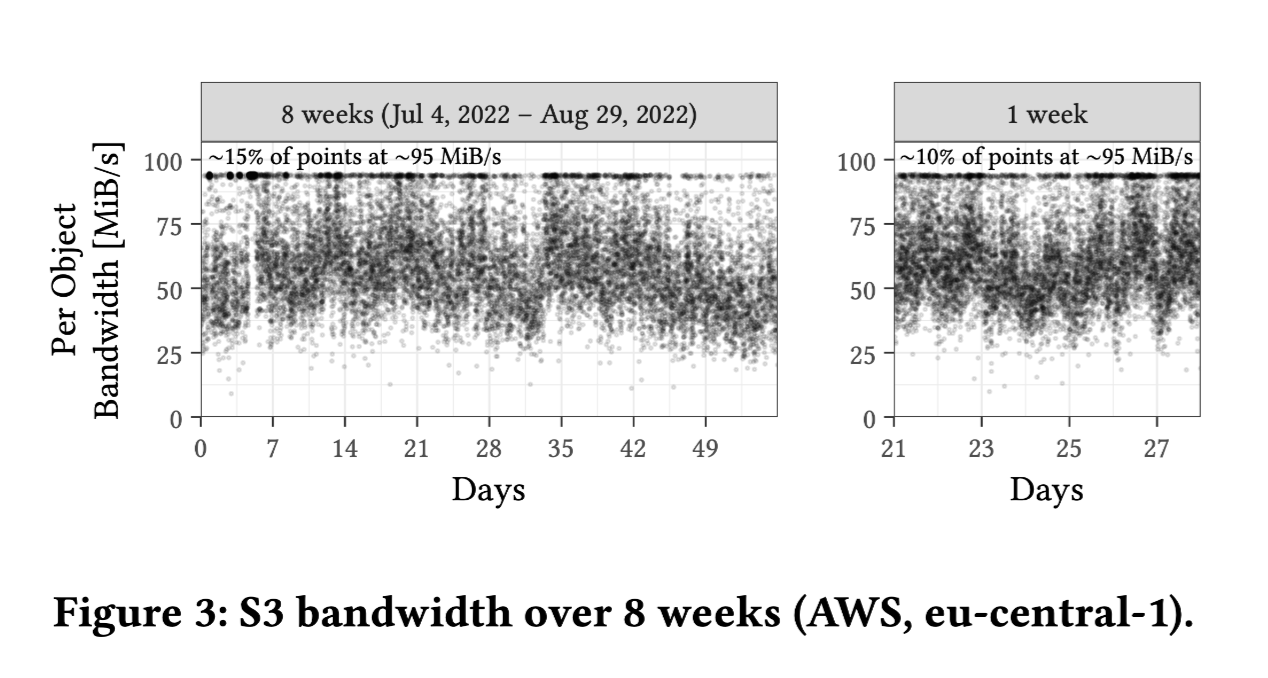
Experimental Method: Single request of 16 MiB Bandwidth Calculation Method: Total bytes / Duration
- There is significant variability in object bandwidth, ranging from approximately 25 to 95 MiB/s.
- A considerable number of data points (15%) are at the maximum value (~95 MiB/s).
- The median performance is stable at 55-60 MiB/s.
- Performance tends to be higher on weekends.
Latency across different cloud providers
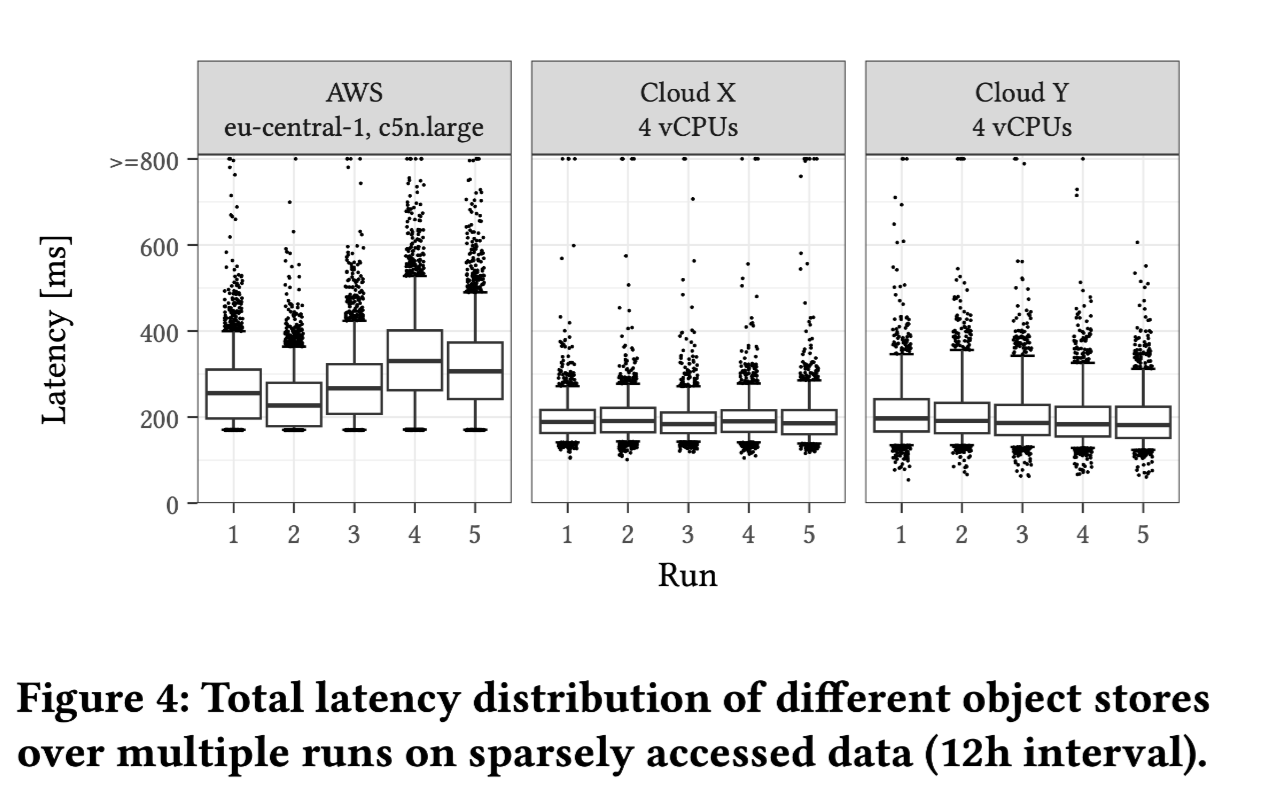
Experimental Method: The test involves individual files of 16 MiB, with each request spaced 12 hours apart to reduce the influence of caching.
- S3 exhibits the highest latency among the tested services.
- S3 has a "minimum latency," meaning all data points exceed this value.
- Compared to AWS, the presence of outliers in the low latency range for other providers suggests they do not conceal the effects of caching.
The above phenomenon might be related to the hardware and implementation of S3. Overall, older hardware or different caching strategies could lead to the observed outcomes in points 2 and 3.
Throughput
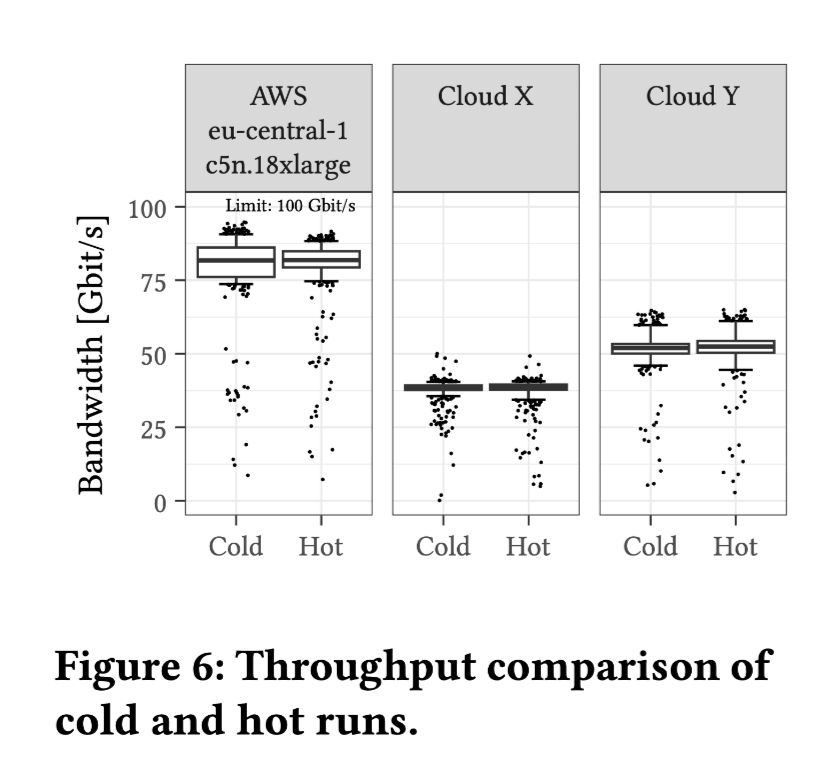
The outcomes from the above figure:
- A single file of 16 MiB, with 256 parallel requests to achieve maximum throughput (100 Gbps).
- The throughput bandwidth fluctuates with the region.
- The median bandwidth of AWS is 75 Gbps.
- The median bandwidth of Cloud X is 40 Gbps.
- The median bandwidth of Cloud Y is 50 Gbps.
- The difference between cold and hot data is minimal.
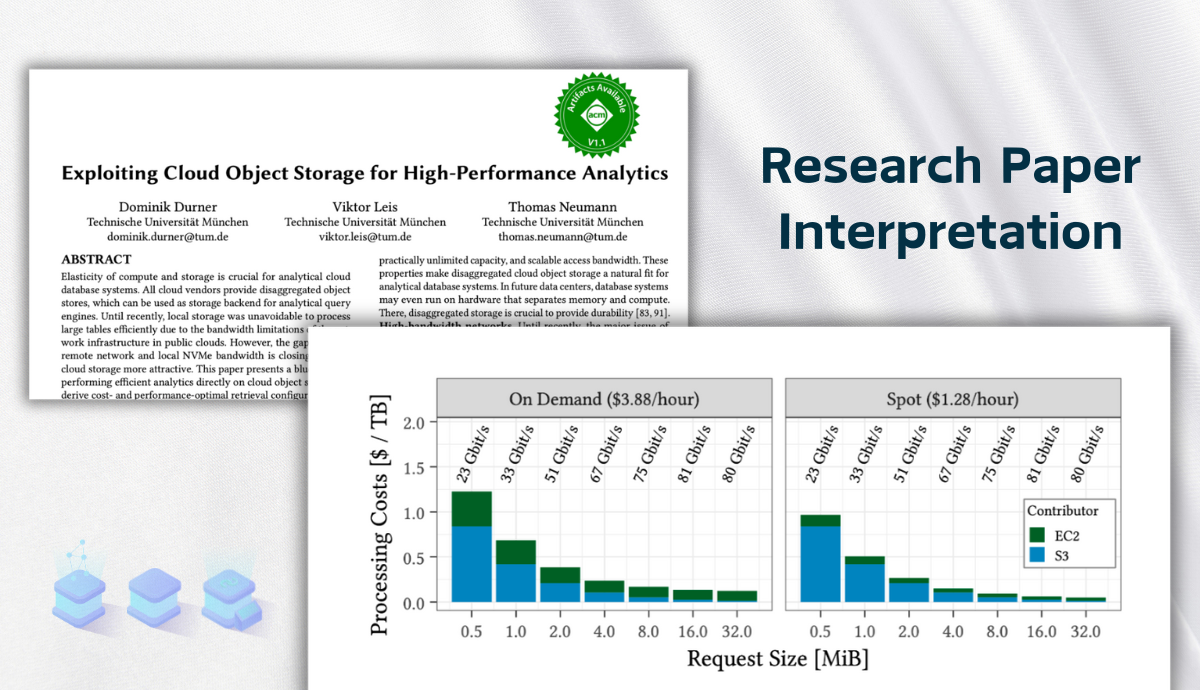
Optimal Request Size
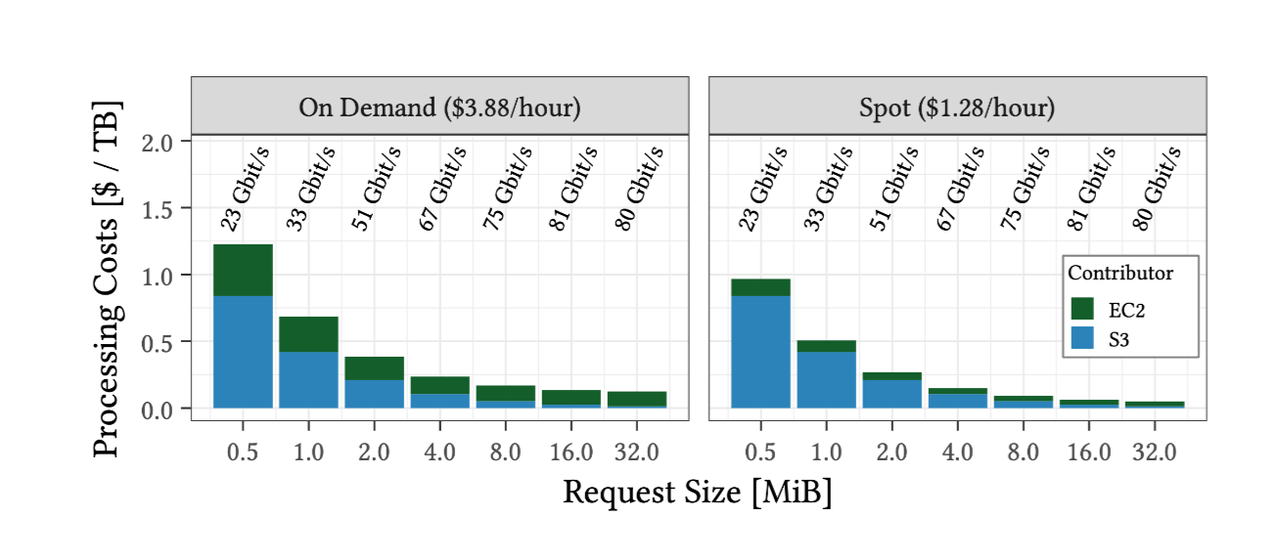
- From the above graph, we can see that the optimal request size usually lies between 8-16 MiB. Although the cost for 32 MiB is a bit lower, its download time is double that of 16 MiB under the same bandwidth, making it less cost-efficient.
Encryption
So far, all experiments conducted are based on non-secure HTTP connections. In this section, the authors compare the throughput performance with AES encryption enabled and after switching to HTTPS.
- HTTPS requires twice the CPU resources compared to HTTP.
- AES encryption increases CPU resources by only 30%.
In AWS, traffic between all regions, and even within availability zones, is automatically encrypted by the network infrastructure. Within the same location, due to VPC isolation, no other user can intercept the traffic between EC2 instances and the S3 gateway. Therefore, using HTTPS in this context is redundant.
Slow Requests
In the experiments, the authors observed significant tail latency in some requests, with some even being lost without any notification. To address this, cloud providers recommend a request hedging strategy to re-requesting unresponsive requests.
The authors have gathered some empirical data on slow requests for 16 MiB files:
After 600 milliseconds, less than 5% of objects have not been successfully downloaded.
Less than 5% of objects have a first byte latency exceeding 200 milliseconds.
Based on these observations, one can consider re-downloading attempts for requests exceeding a certain latency threshold.
Cloud Storage Data Request Model
In their study, the authors observed that the bandwidth of a single request is similar to that when accessing data on an HDD (Hard Disk Drive). To fully utilize network bandwidth, a large number of concurrent requests are necessary. For analytical workloads, requests in the 8-16 MiB range are cost-effective. They devised a model to predict the number of requests needed to achieve a given throughput target.
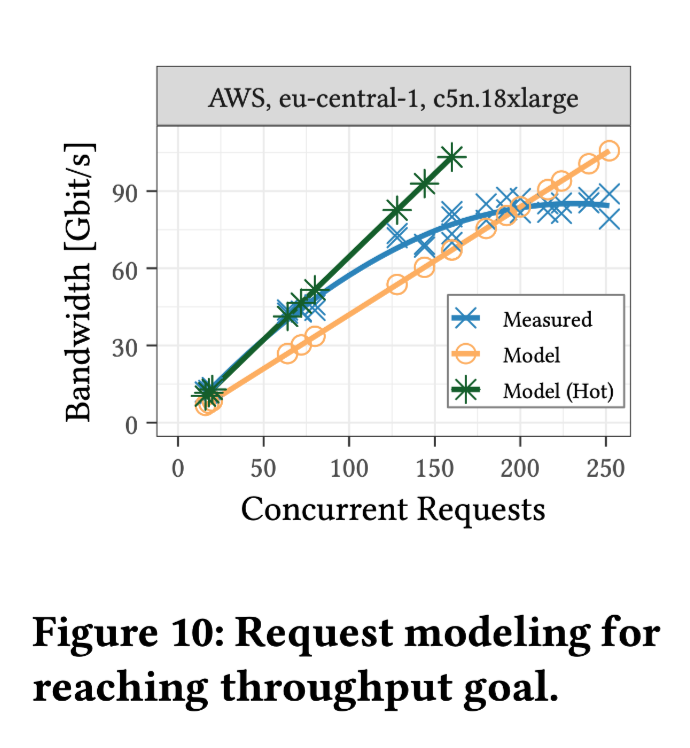
The experiment utilized computing instances with a total bandwidth of 100 Gbps. In the graph, "Model (Hot)" represents the 25th percentile (p25) latency observed in previous experiments.
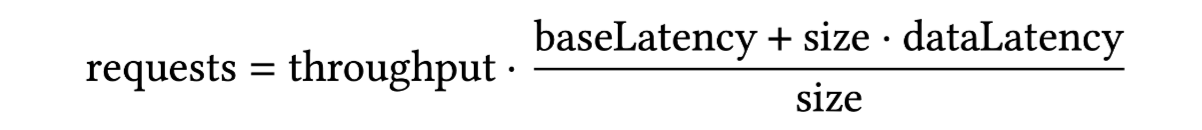
The median base latency is approximately 30 ms, as determined from the 1 KiB trial in Figure 2.
The median data latency is around 20 ms/MiB, with Cloud X and Cloud Y exhibiting lower rates (12–15 ms/MiB), calculated from the 16 MiB median minus the base latency in Figure 2.
To achieve 100 Gbps on S3, 200-250 concurrent requests are necessary.
With access latencies in tens of milliseconds and a bandwidth of about 50 MiB/s per object, it suggests that the object storage is likely HDD-based. This implies that reading at ∼80 Gbps from S3 is equivalent to accessing around 100 HDDs simultaneously.
Anyblob
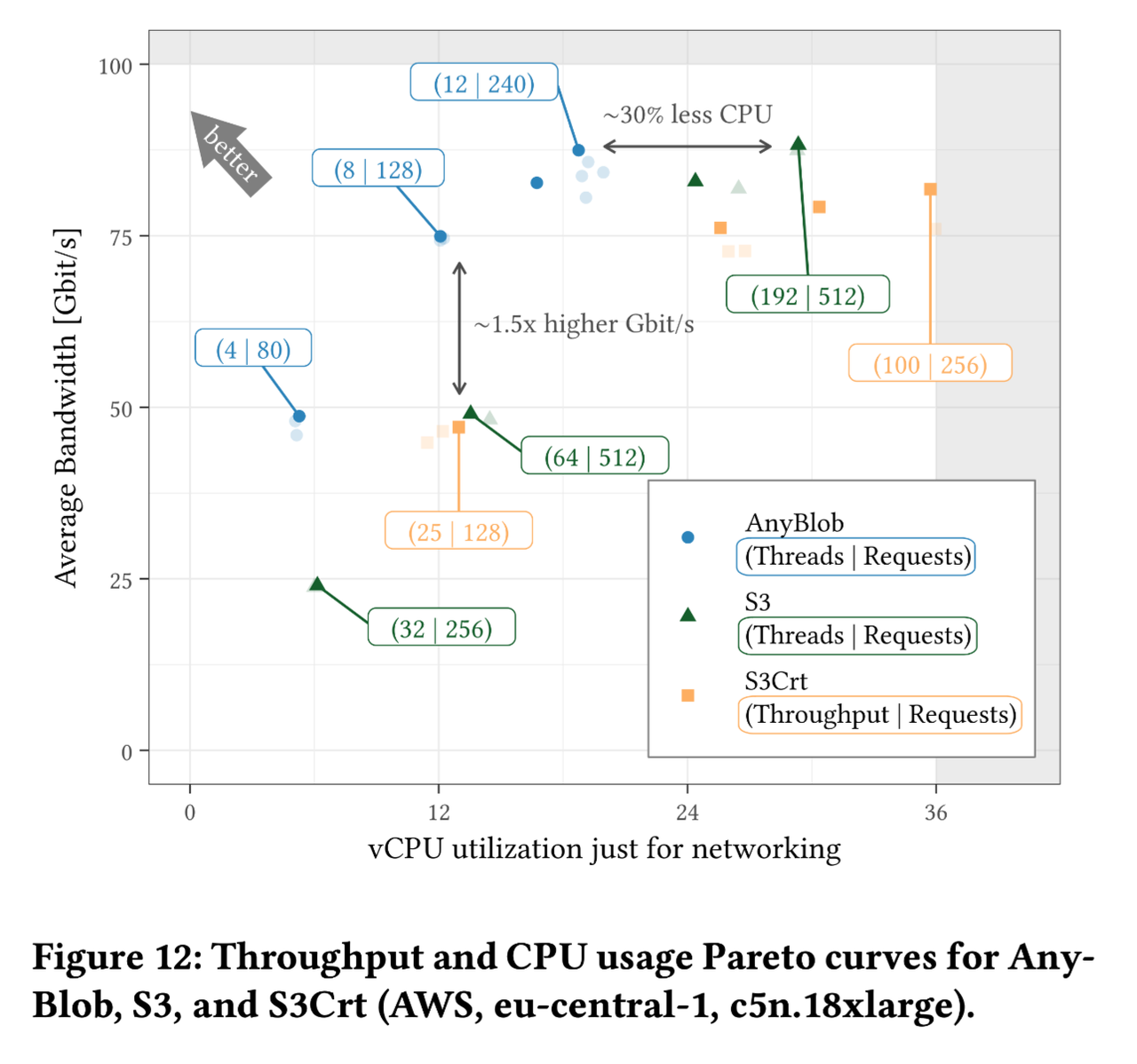
AnyBlob is a universal object storage library created by the authors, designed to support access to object storage services from various cloud providers.
Compared to existing C++ libraries for S3, AnyBlob utilizes the io_uring system call and removes the limitation of one-to-one thread mapping. The final results indicate that AnyBlob achieves higher performance with reduced CPU usage. However, it's worth considering that the primary reason for this improvement might be the subpar quality of the existing C++ S3 libraries.
Domain name resolution strategies
The AnyBlob does incorporate noteworthy features. The authors noted that resolving domain names for each request introduces significant latency overhead. To address this, they implemented strategies including:
Caching Multiple Endpoint IPs: Storing the IP addresses of multiple endpoints in a cache and scheduling requests to these IPs. Replace the endpoints with noticeably deteriorating performance based on statistical information.
Based on MTU (Maximum Transmission Unit): Different S3 endpoints have different MTUs. Some support jumbo frames up to 9001 bytes, which can significantly reduce CPU overhead.
MTU Discovery Strategy: This involves pinging the target endpoint's IP with a payload larger than 1500 bytes and the DNF (Do Not Fragment) flag set to determine if it supports larger MTUs.
Integration with Cloud Storage
In this section, the authors discuss how they integrated cloud storage. Overall, these ideas are converging in practice, and the specific implementation details depend on the engineering practices of different teams.

Adaptive Strategy If the processing speed of requested data is slow, then reduce the number of download threads (and tasks) and increase the number of request threads (and tasks).
Performance Evaluation
Data Download Performance
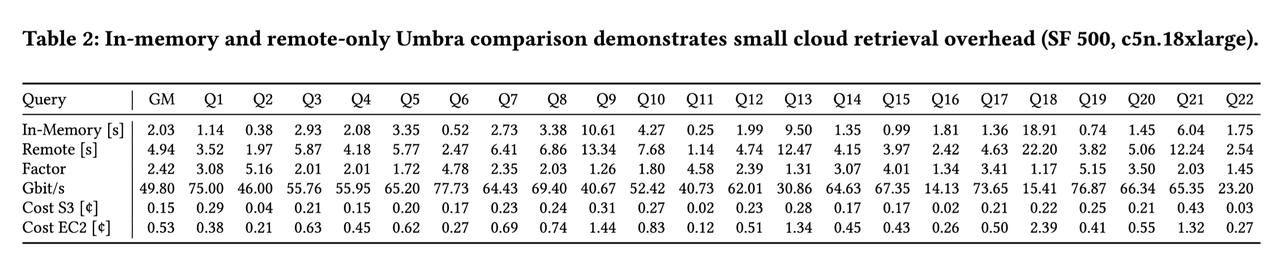
Experimental Parameters: TPC-H scale factor 500 ( ~500 GiB of data).
The authors categorized the queries into two types: retrieval-heavy and computation-heavy.
Retrieval-heavy examples: Queries 1, 6, and 19. These are characterized by a constant multiple difference in performance between In-Memory and Remote storage.
Computation-heavy examples: Queries 9 and 18. These are marked by a very small performance difference between In-Memory and Remote storage.
Comparison of Different Storage Types
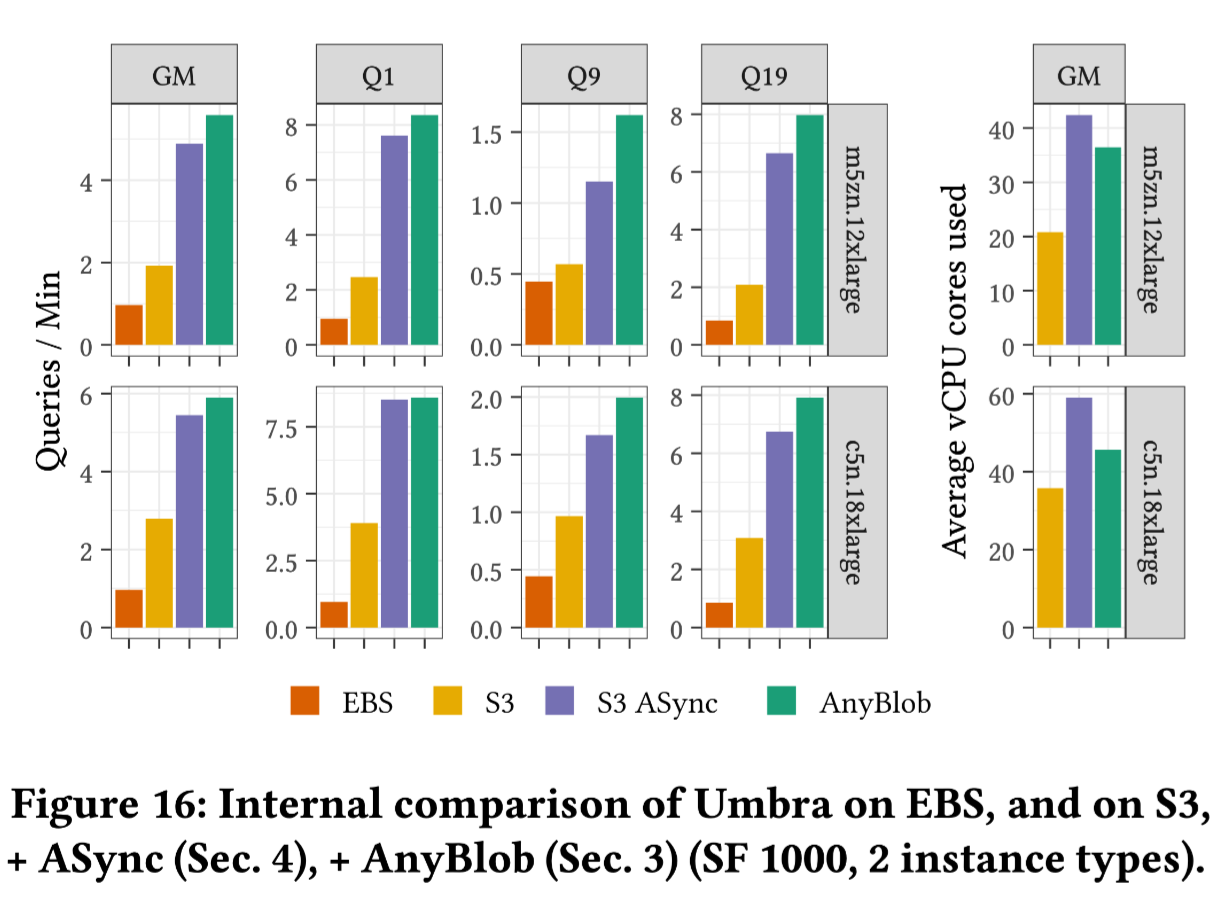
- EBS (Elastic Block Store) exhibits the poorest performance, likely due to the utilization of lower-tier options like gp2/gp3, which offer around 1 GiB of bandwidth.
Scalability
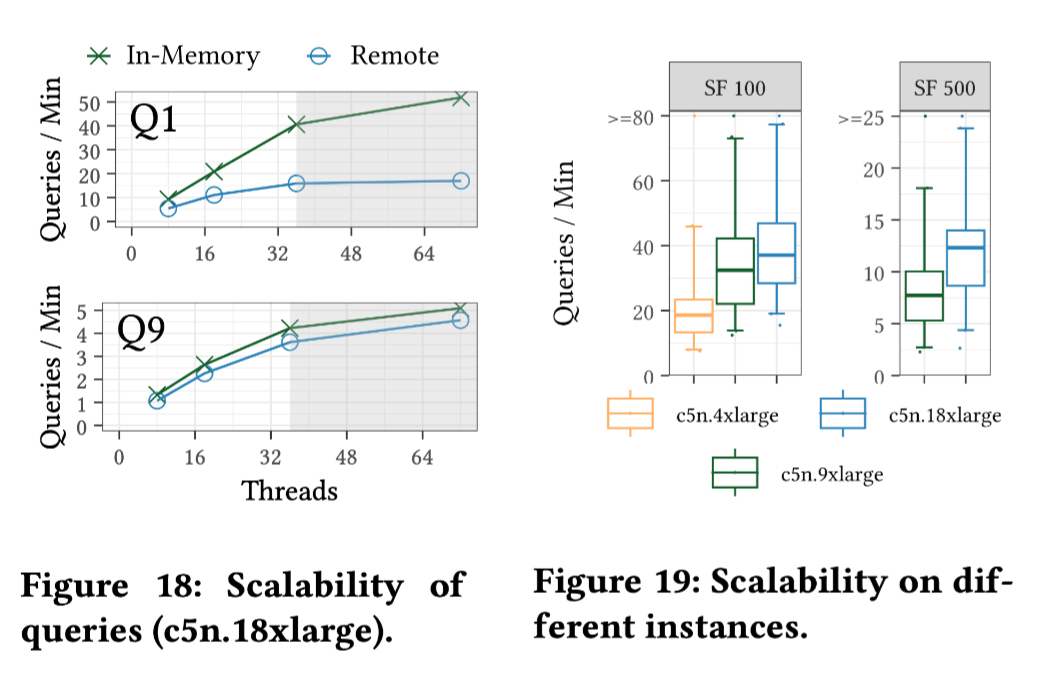
Retrieval-Heavy (Q1): The bottleneck in this type of query lies in the network bandwidth.
Computation-Heavy (Q9): The performance improves with an increase in the number of cores. The throughput of the Remote (the Umbra) is nearly the same as that of the in-memory version.
End-To-End Study with Compression & AES
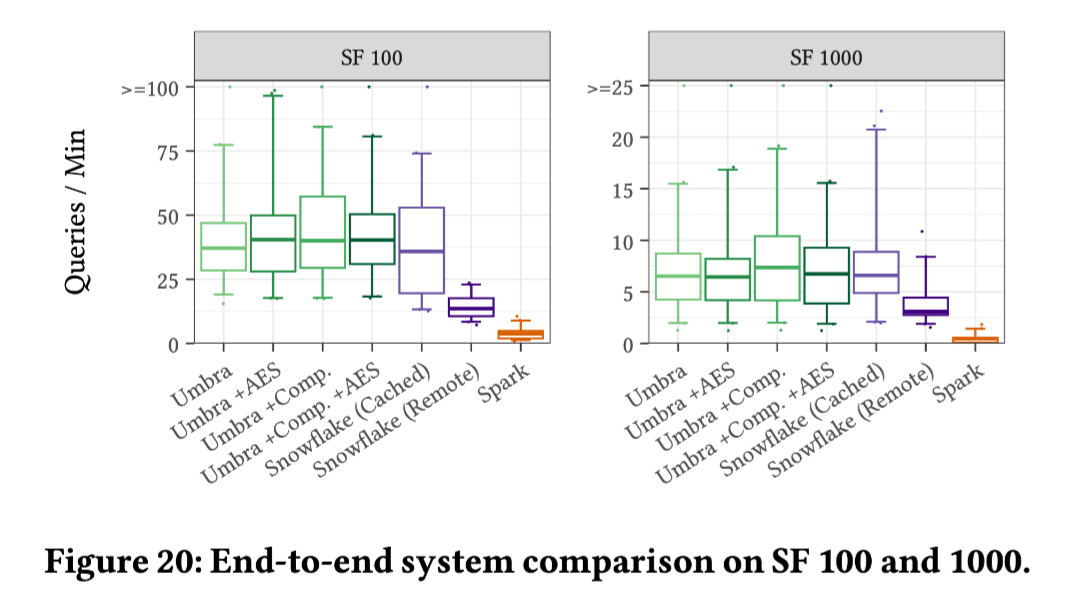
Experimental Parameters: Scale Factor (SF) of 100 (~ 100 GiB) and 1,000 (~ 1 TiB of data).
The Snowflake used in the experiment is a large-size configuration, while Umbra utilized EC2 c5d.18xlarge instances, with caching disabled.
Overall, this comparison might be insufficiently strict. For example, it lacks detailed information about the Snowflake setup:
For the Large-size Snowflake, there might be issues with overselling and throttling.
The Snowflake group may have purchased a standard, lower-tier version, which could also impact the results.
However, this also highlights another aspect: the core technique of benchmark marketing might involve some statistical wizardry, like hiding the query that didn't hit the cache behind the p99. In other words, the effort required for benchmarking optimization when running a single query 10 times versus 100 times might not be on the same scale.
Summary
Overall, this article provides substantial data support and insights in several areas:
- Characteristics of object storage
- Optimal file size for data requests
- The impact of enabling HTTPS
- Cloud storage data request model
- Scheduling queries and download tasks based on statistical information
- Empirical data on handling slow requests
- Utilization of MTU jumbo frames
In the upcoming GreptimeDB 0.7.0 release, we have implemented extensive optimizations in querying, including enhancements for queries on object storage. In some scenarios, query response times are now approaching the levels of local storage. Star us on GitHub and stay tuned with GreptimeDB, we eagerly await your try and welcome any form of feedback and discussion.




