
On this page
GreptimeDB offers a fast and cost-effective alternative to InfluxDB, boasting cloud-based elasticity and commodity storage. It can be considered a production-ready implementation of InfluxDB v3.
You may want to try us and wonder how to migrate your data from InfluxDB v2 to GreptimeDB. This article will give you an answer.
Prerequisites
Before starting, you need access to your InfluxDB engine path, which contains your data files. If you are running a server with InfluxDB's official Docker Image, the engine path would be /var/lib/influxdb2/engine/.
This tutorial guides you through migrating data from an InfluxDB server. Refer to the Appendix for instructions on how to set up your environment for an InfluxDB server.
Set up Greptime Service
Assuming you have an InfluxDB server up and running, the first step before migrating data to a GreptimeDB server is to set it up.
The fastest way to get a GreptimeDB cluster is to start a Hobby plan service on GreptimeCloud. Note that the Hobby plan is completely free with no credit card info needed.
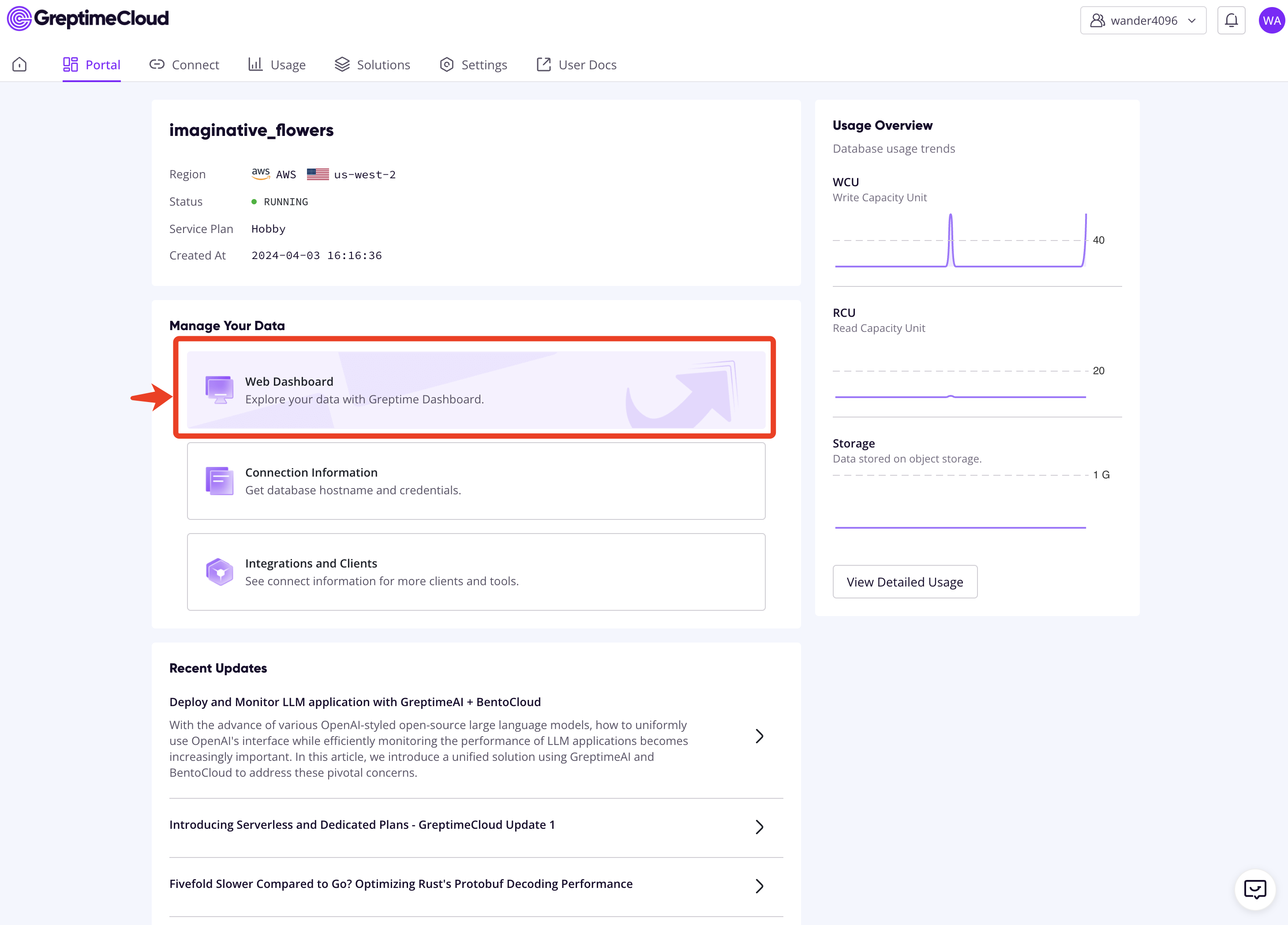
Follow the instructions to create a new GreptimeDB service, and click the "Connection Information" button to find the connection information. Then, export the necessary environment variables:
shell
export GREPTIME_DB="<dbname>"
export GREPTIME_HOST="<host>"
export GREPTIME_USERNAME="<username>"
export GREPTIME_PASSWORD="<password>"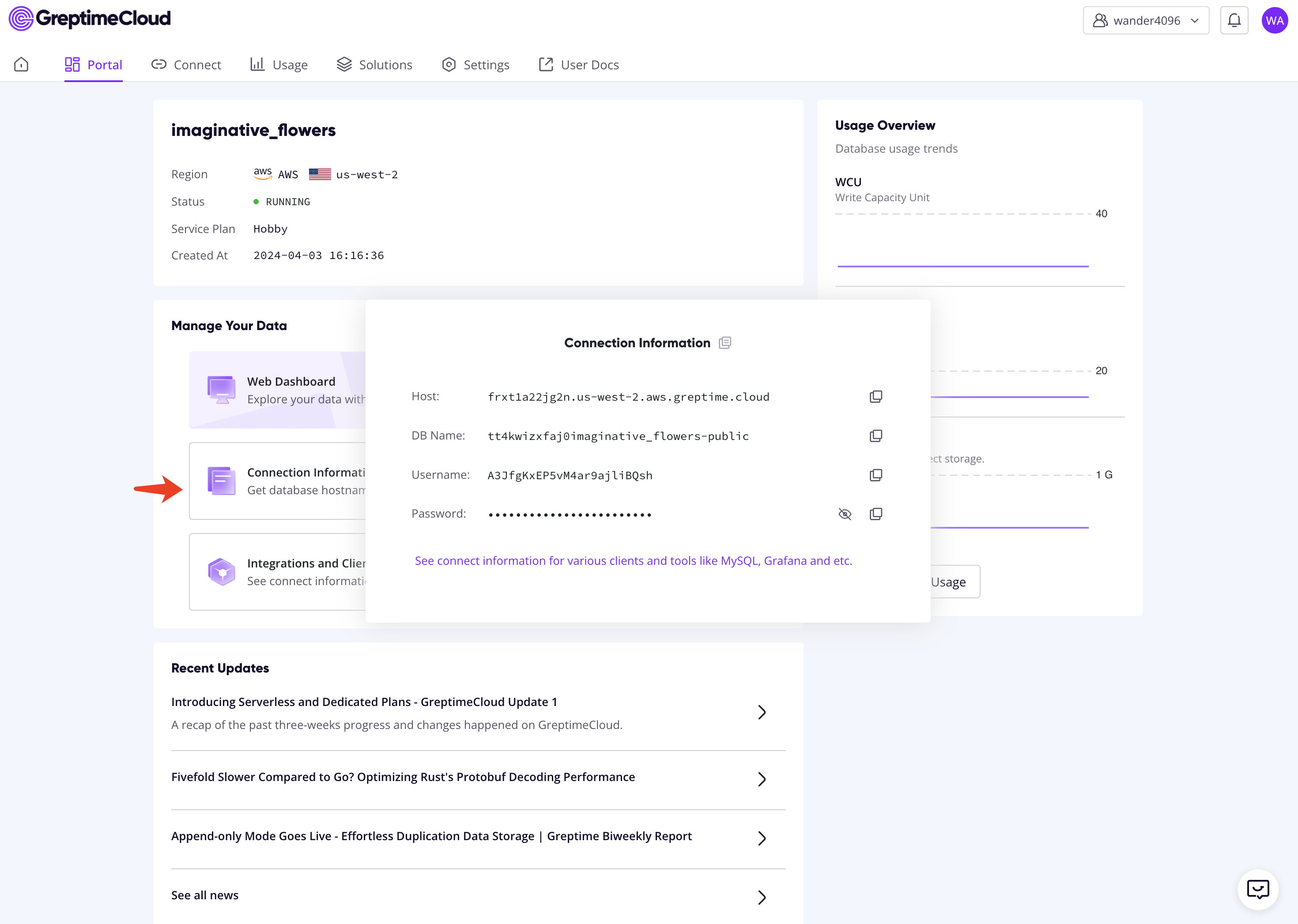
Export Data from InfluxDB v2 Server
Now, let's get the bucket ID to be migrated with InfluxDB CLI:
shell
influx bucket listIf you set up the server as in Appendix, you can run the following command:
shell
docker exec influxdb2 influx bucket listYou'll get outputs as the following:
text
ID Name Retention Shard group duration Organization ID Schema Type
22bdf03ca860e351 _monitoring 168h0m0s 24h0m0s 41fabbaf2d6c2841 implicit
b60a6fd784bae5cb _tasks 72h0m0s 24h0m0s 41fabbaf2d6c2841 implicit
9a79c1701e579c94 example-bucket infinite 168h0m0s 41fabbaf2d6c2841 implicitSupposed you'd like to migrate data from example-bucket, then the ID is 9a79c1701e579c94.
Log in to the server you deployed InfluxDB v2 and run the following command to export data in InfluxDB Line Protocol format:
shell
# The engine path is often "/var/lib/influxdb2/engine/".
export ENGINE_PATH="<engine-path>"
# Export all the data in example-bucket (ID=9a79c1701e579c94).
influxd inspect export-lp --bucket-id 9a79c1701e579c94 --engine-path $ENGINE_PATH --output-path influxdb_export.lpIf you set up the server as in Appendix, you can run:
shell
export ENGINE_PATH="/var/lib/influxdb2/engine/"
docker exec influxdb2 influxd inspect export-lp --bucket-id 9a79c1701e579c94 --engine-path $ENGINE_PATH --output-path influxdb_export.lpThe outputs look like the following:
text
{"level":"info","ts":1713227837.139161,"caller":"export_lp/export_lp.go:219","msg":"exporting TSM files","tsm_dir":"/var/lib/influxdb2/engine/data/9a79c1701e579c94","file_count":0}
{"level":"info","ts":1713227837.1399868,"caller":"export_lp/export_lp.go:315","msg":"exporting WAL files","wal_dir":"/var/lib/influxdb2/engine/wal/9a79c1701e579c94","file_count":1}
{"level":"info","ts":1713227837.1669333,"caller":"export_lp/export_lp.go:204","msg":"export complete"}TIP
You can specify more concrete data sets, like measurements and time range, to be exported. Please refer to the influxd inspect export-lp manual for details.
Import Data to GreptimeDB
Copy the influxdb_export.lp file to a working directory. If you set up the server as in Appendix, you can run:
shell
docker cp influxdb2:/influxdb_export.lp influxdb_export.lpBefore importing data to GreptimeDB, if the data file is too large, it's recommended to split the data file into multiple slices:
shell
split -l 1000 -d -a 10 influxdb_export.lp influxdb_export_slice.
# -l [line_count] Create split files line_count lines in length.
# -d Use a numeric suffix instead of a alphabetic suffix.
# -a [suffix_length] Use suffix_length letters to form the suffix of the file name.Now, import data to GreptimeDB via the HTTP API:
shell
for file in influxdb_export_slice.*; do
curl -i -H "Authorization: token $GREPTIME_USERNAME:$GREPTIME_PASSWORD" \
-X POST "https://${GREPTIME_HOST}/v1/influxdb/api/v2/write?db=$GREPTIME_DB" \
--data-binary @${file}
# avoid rate limit in the hobby plan
sleep 1
doneYou're done!
You can browse the Web Dashboard on GreptimeCloud to check the ingested data:
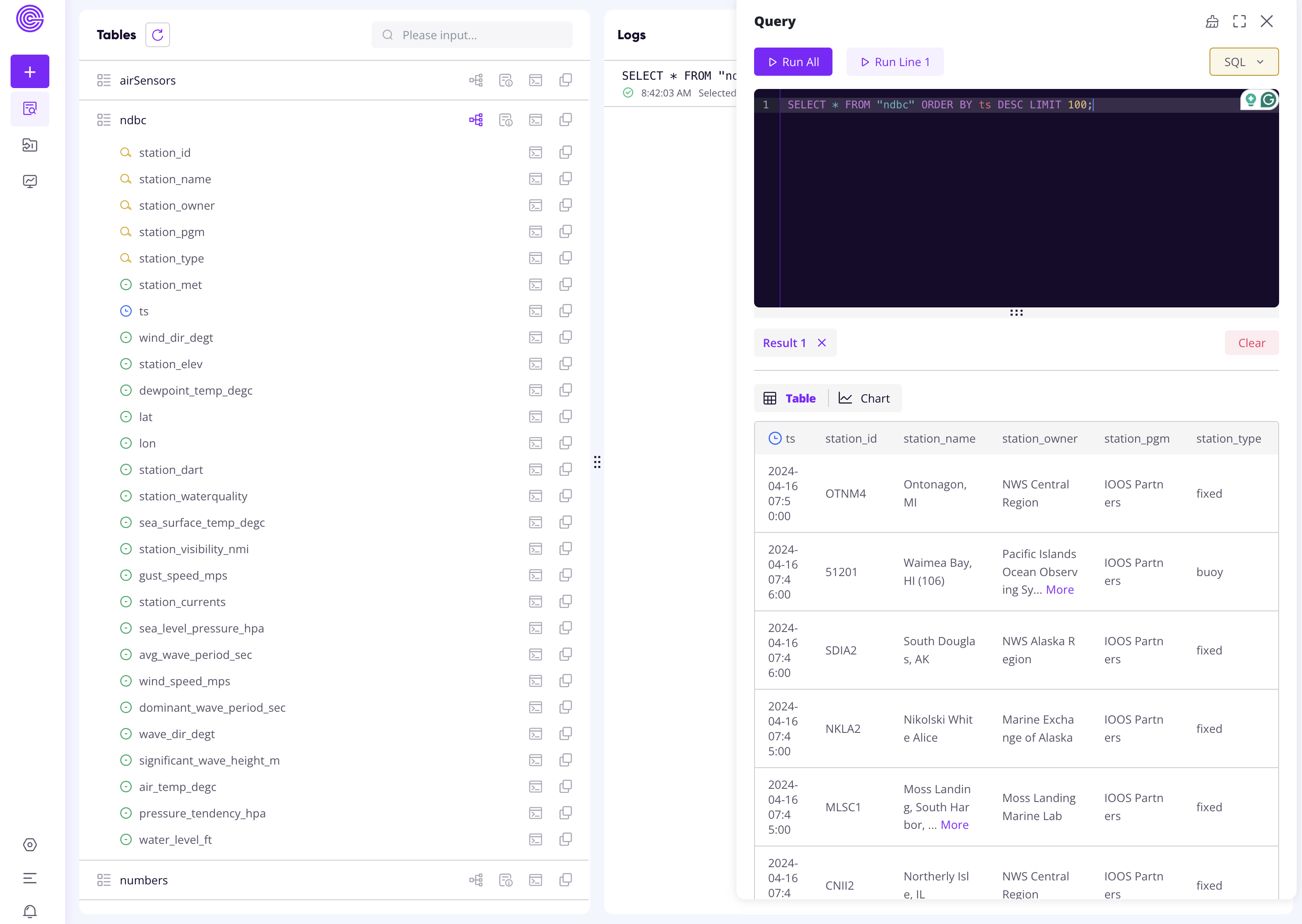
Appendix: Set up an InfluxDB v2 Server
This section shows how to start an InfluxDB server and prepare sample data.
First, change to a clean directory and run the following Docker command to start a new server in a container named influxdb2:
shell
docker run \
-p 8086:8086 \
-v "$PWD/data:/var/lib/influxdb2" \
-v "$PWD/config:/etc/influxdb2" \
--name influxdb2 \
influxdb:2Then, execute the setup command to initialize credentials:
shell
export USERNAME=tison
export PASSWORD=this_is_a_fake_passwd
export ORGANIZATION=my-org
export BUCKET=example-bucket
docker exec influxdb2 influx setup \
--username $USERNAME \
--password $PASSWORD \
--org $ORGANIZATION \
--bucket $BUCKET \
--token this_is_a_token \
--forceNow, create and run a task to ingest sample data:
shell
cat <<END > task.flux
import "influxdata/influxdb/sample"
option task = {
name: "Collect NOAA NDBC sample data",
every: 15m,
}
sample.data(set: "noaa")
|> to(bucket: "example-bucket")
END
docker cp task.flux influxdb2:/task.flux
docker exec influxdb2 influx task create --org my-org -f task.flux
# Find the task ID and set the environment variable.
docker exec influxdb2 influx task list
export TASK_TD=<task-id>
# Manually trigger a run. The task will be scheduled every 15 minutes.
docker exec influxdb2 curl -H "Authorization: token this_is_a_token" -X POST http://localhost:8086/api/v2/tasks/$TASK_TD/runs
# Check the run finished.
docker exec influxdb2 influx task run list --task-id=$TASK_TD
# Ensure sample data ingested.
docker exec influxdb2 influx query 'from(bucket:"example-bucket") |> range(start:-1d)'About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




