On this page

Halfway through 2024, our Greptime team is steadily progressing towards the production-ready v1.0 release as planned. Today, we're excited to announce that v0.8 is officially live, introducing the Flow Engine – a lightweight, time-series-oriented stream processing framework that provides continuous aggregation capabilities. We eagerly invite the entire community to engage with this release and share their invaluable feedback through Slack.
From v0.7 to v0.8, we made significant progress: a total of 88 commits were submitted, modifying 893 files, which included 40 feature enhancements, 20 bug fixes, 22 code refactorings, and a substantial amount of testing work. During this period, a total of 16 individual contributors submitted 44 code contributions.
Flow Engine
In GreptimeDB v0.8, we've introduced the Flow Engine, which brings continuous aggregation capabilities. This feature allows for real-time, stream-based aggregation computations and materializes results. It's incredibly handy for situations requiring on-the-fly calculations and querying of sums, averages, or other aggregate information.
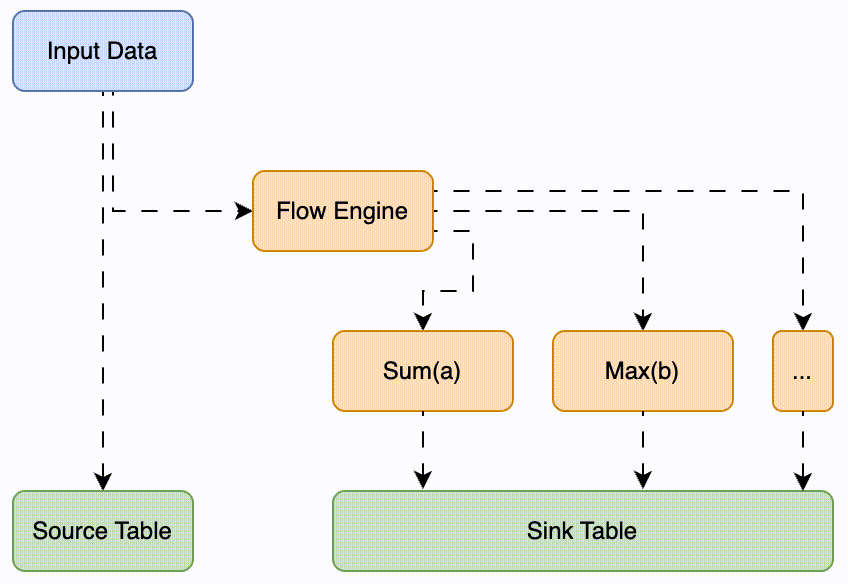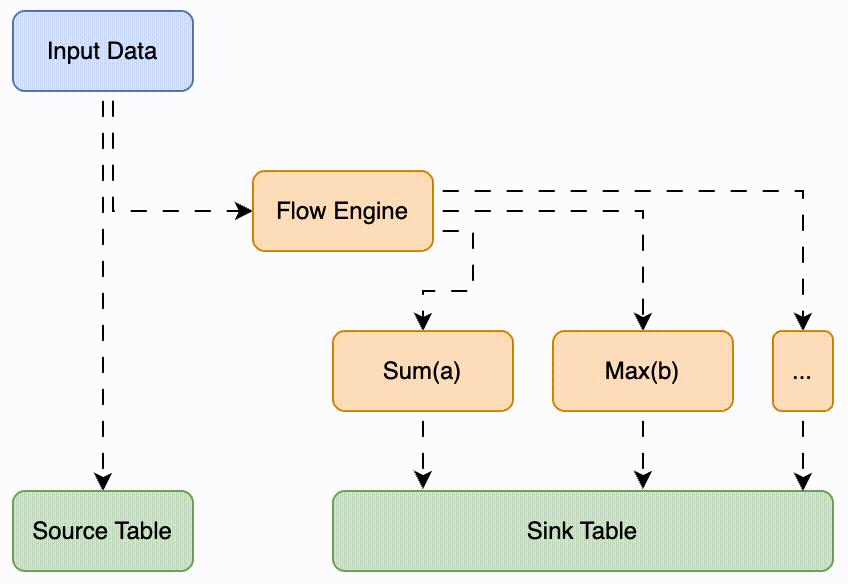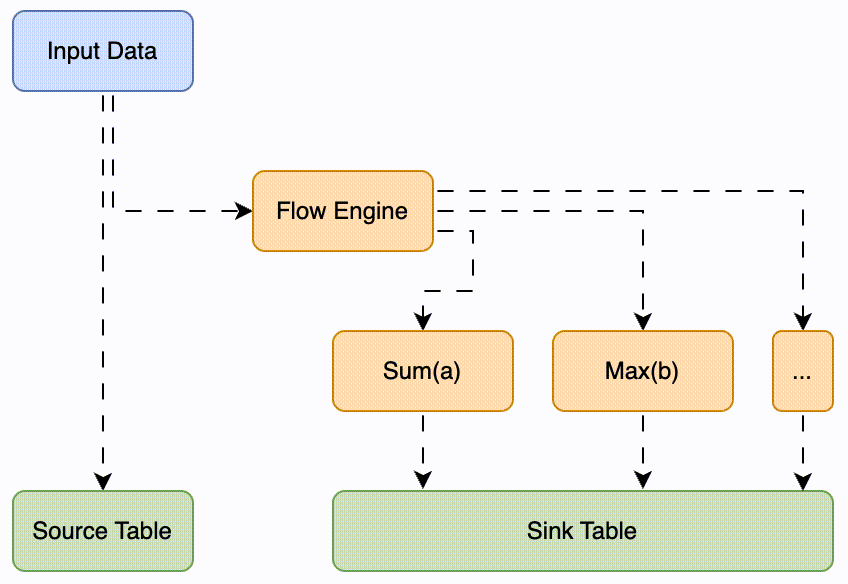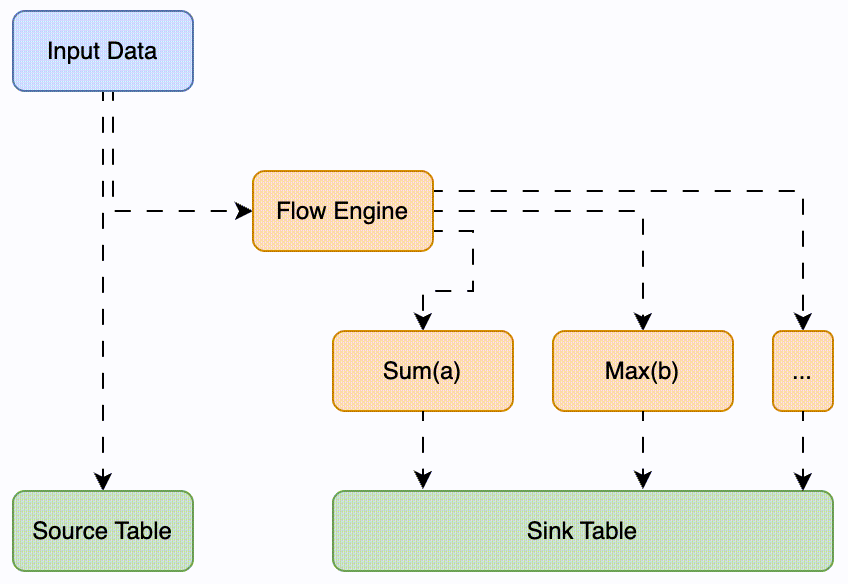
For example, if we have a table named my_source_table and we need to continuously calculate statistical counts in five-minute windows, we can declare the following flow task:
sql
CREATE FLOW IF NOT EXISTS my_flow
OUTPUT TO my_sink_table
COMMENT = "My first flow in GreptimeDB"
AS
SELECT count(item)
FROM my_source_table
GROUP BY tumble(time_index, INTERVAL '5 minutes', '2024-05-20 00:00:00');Currently, we've enabled support for fixed window computations along with several commonly used aggregation functions, and we're constantly working on further enhancements. Feel free to give them a spin and let us know your feedback!
Continuous Aggregation Task Demonstration
Here's a brief demonstration of what a continuous aggregation task might look like. First, create a numbers_input table as the input table, and out_num_cnt as the output table using the following statement.
We are currently focusing on continuous optimization of user experience, with the expectation that in the next release, manual creation of sink tables will no longer be necessary, as GreptimeDB will be able to derive them directly from queries.
sql
CREATE TABLE numbers_input (
number INT,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(number),
TIME INDEX(ts)
);sql
CREATE TABLE out_num_cnt (
sum_number BIGINT,
start_window TIMESTAMP TIME INDEX,
end_window TIMESTAMP,
update_at TIMESTAMP,
);Then create a continuous aggregation task named test_numbers to sum the number column. The aggregation window is a fixed window of 1 second.
sql
CREATE FLOW test_numbers
SINK TO out_num_cnt
AS
SELECT sum(number) FROM numbers_input GROUP BY tumble(ts, '1 second', '2024-05-20 00:00:00');Now, you can insert records into numbers_input, and observe the results in out_num_cnt.
sql
INSERT INTO numbers_input
VALUES
(20,1625097600000),
(22,1625097600500);The following result will be generated in out_num_cnt:
sql
SELECT * FROM out_num_cnt;sql
sum_number | start_window | end_window | update_at
------------+----------------------------+----------------------------+----------------------------
42 | 2021-07-01 00:00:00.000000 | 2021-07-01 00:00:01.000000 | 2024-05-17 08:32:56.026000
(1 row)Other Updates
- Support for Column Type Modification
This feature allows users to effortlessly alter the data type of columns within a table without the hassle of rebuilding the table or manually migrating data. This enhances the flexibility and maintainability of the database.
For instance, the following statement changes the load_15 column of the monitor table to a STRING type:
ALTER TABLE monitor MODIFY COLUMN load_15 STRING;TIP
Note: The modified column cannot be a tag (primary key) or a time index, and it must be nullable to ensure safe data conversion (returns NULL on conversion failure).
- Introduction of Cluster Management Information Table (cluster_info) in
information_schema
We've introduced the cluster_info table in the information_schema, which allows querying for information about the cluster. This functionality aids administrators in monitoring and managing the health status of the database cluster, facilitating prompt issue detection and resolution.
Query results in Distributed Mode:
text
+---------+-----------+----------------+---------+------------+-------------------------+-------------+-------------+
| peer_id | peer_type | peer_addr | version | git_commit | start_time | uptime | active_time |
+---------+-----------+----------------+---------+------------+-------------------------+-------------+-------------+
| 1 | DATANODE | 127.0.0.1:4101 | 0.8.0 | 86ab3d9 | 2024-04-30T06:40:04.791 | 4s 478ms | 1s 467ms |
| 2 | DATANODE | 127.0.0.1:4102 | 0.8.0 | 86ab3d9 | 2024-04-30T06:40:06.098 | 3s 171ms | 162ms |
| 3 | DATANODE | 127.0.0.1:4103 | 0.8.0 | 86ab3d9 | 2024-04-30T06:40:07.425 | 1s 844ms | 1s 839ms |
| -1 | FRONTEND | 127.0.0.1:4001 | 0.8.0 | 86ab3d9 | 2024-04-30T06:40:08.815 | 454ms | 47ms |
| -1 | METASRV | 127.0.0.1:3002 | 0.8.0 | 86ab3d9 | 2024-04-30T06:39:03.290 | 1m 5s 677ms | |
+---------+-----------+----------------+---------+------------+-------------------------+-------------+-------------+- Support for Append-only Tables
Users can now create tables in Append-only mode by setting the append mode during table creation (create table ... engine=mito with('append_mode'='true');). Append-only tables only support insertion operations, but not deletion or updates, and the inserted data isn't deduplicated, making it ideal for storing duplicate data.
- Support for
DROP DATABASEStatement
The DROP DATABASE statement enables swift deletion of all tables and resources under a database instance.
- Significant Optimization of Prometheus Remote Write Protocol Parsing Overhead
Read the optimization details here.
- New Table Partitioning Methods and Syntax
Considering the future need for frequent partition changes such as automatic partitioning or repartitioning, we're developing a new partitioning syntax. Refer to the official documentation here for usage details.
- Support for Distributed Query Performance Analysis with
EXPLAIN ANALYZE <QUERY>
Analyze and optimize query statements swiftly in distributed mode. For instance, analyze the step-by-step execution time of count(*):
shell
explain analyze SELECT count(*) FROM system_metrics;
+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| stage | node | plan |
+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 0 | 0 | MergeScanExec: peers=[4402341478400(1025, 0), ] metrics=[output_rows: 1, ready_time: 6352264, finish_time: 7509279,] |
| | | |
| 1 | 0 | AggregateExec: mode=Final, gby=[], aggr=[COUNT(greptime.public.system_metrics.ts)] metrics=[output_rows: 1, elapsed_compute: 108029, ] |
| | | CoalescePartitionsExec metrics=[output_rows: 32, elapsed_compute: 83055, ] |
| | | AggregateExec: mode=Partial, gby=[], aggr=[COUNT(greptime.public.system_metrics.ts)] metrics=[output_rows: 32, elapsed_compute: 334913, ] |
| | | RepartitionExec: partitioning=RoundRobinBatch(32), input_partitions=1 metrics=[repart_time: 1, fetch_time: 441565, send_time: 30325, ] |
| | | StreamScanAdapter { stream: "<SendableRecordBatchStream>" } metrics=[output_rows: 3, mem_used: 24, ] |
| | | |
| | | Total rows: 1 |
+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+Upgrade Guide
Given the significant changes in the new version, upgrading to v0.8 requires downtime. We recommend using our official upgrade tool for a smooth transition. Here's a general upgrade process:
- Create a fresh v0.8 cluster
- Stop traffic ingress to the old cluster (stop writing)
- Export table structure and data using the GreptimeDB CLI upgrade tool
- Import data into the new cluster using the GreptimeDB CLI upgrade tool
- Switch traffic ingress to the new cluster
For detailed upgrade instruction, please refer to: https://docs.greptime.com/user-guide/deployments-administration/upgrade
Future Outlook
Looking ahead, our next milestone is set for early July, when we'll unveil v0.9.
This release will introduce the Log Engine, a specialized storage engine tailored for log storage and query optimization. It will feature full-text indexing and may also integrate with the Flow Engine, facilitating tasks like log content parsing and extraction.
The ultimate goal of GreptimeDB is to evolve into a versatile time-series database that seamlessly integrates both metrics and logs. Stay tuned for more updates as we continue to innovate and refine our platform!
About Greptime
We help industries that generate large amounts of time-series data, such as Connected Vehicles (CV), IoT, and Observability, to efficiently uncover the hidden value of data in real-time.
Visit the latest version from any device to get started and get the most out of your data.
- GreptimeDB, written in Rust, is a distributed, open-source, time-series database designed for scalability, efficiency, and powerful analytics.
- GreptimeCloud is a fully-managed cloud database-as-a-service (DBaaS) solution built on GreptimeDB. It efficiently supports applications in fields such as observability, IoT, and finance. The built-in observability solution, GreptimeAI, helps users comprehensively monitor the cost, performance, traffic, and security of LLM applications.
- Vehicle-Cloud Integrated TSDB solution is tailored for business scenarios of automotive enterprises. It addresses the practical business pain points that arise when enterprise vehicle data grows exponentially.
If anything above draws your attention, don't hesitate to star us on GitHub or join GreptimeDB Community on Slack. Also, you can go to our contribution page to find some interesting issues to start with.




