
On this page
Advancements in networking technology and cheaper, stronger computing resources have fueled the IoT boom, resulting in devices that measure everything from the temperature in your home to the beats per minute of your heart. These devices are purpose-built to perform singular tasks exceptionally well and typically operate in more constrained environments compared to the powerful servers underpinning the cloud infrastructure powering our digital world.
Measuring data alone doesn’t provide value; it’s the actions we take based on that data that make it meaningful. For example, receiving a phone alert to breathe when your heart rate variability breaches a certain threshold, turning on your central cooling system when the room you're in gets too hot, or adjusting machinery settings on a factory floor to maintain optimal efficiency and prevent downtime when sensors detect changes in production line speed.
Key Point
These internet-connected devices often need a critical piece of infrastructure to store the state of your applications and provide a common source for processing these metrics: The Database.
For Simple Home Automation
e.g. Smart Lighting, Automated Plant Watering

Automating mundane tasks within your house has become one of the most common consumer applications of IoT connected devices. While many platforms have sprung up to help customers schedule their home’s lights, HVAC, security systems etc. Technical Hobbyists can buy a set of smart switches or sensors and connect them to a Raspberry Pi Enabled IoT Gateway to customize for their specific use case.
Key Point
In Simple Home Automation cases, a database is often needed by an IoT gateway to store the different device configurations on the network to run operations against - which amounts to a relatively low amount of data being read and written.
Considerations when choosing a database for this use case include:
- Lightweight and Resource-Efficient: The database should be lightweight to ensure it doesn’t consume too much of the limited resources (CPU, memory, storage) available on an IoT gateway.
- Durability and Reliability: The database must be reliable, ensuring data integrity even in the event of power failures or unexpected shutdowns.
- Low Maintenance: The database should require minimal maintenance and administration, ideal for a home environment where users may not have technical expertise.
- Low Performance Requirements: Given the small size of the network and limited sensor input, compromises can be made on performance. No need to manufacture a tornado to blow out a match here.
SQLite: The Embed Anywhere Database
One of the most widely used and respected general purpose, relational databases

➡️ Started in 2000
🌝 Open Source
SQLite shines as a beacon of simplicity with its zero-dependency C implementation. It doesn’t run its own database server but embeds directly in the running process of the application, reading and writing all of the application’s data into a single file. With full ACID compliance and transactional-support, SQLite packs all of the features needed for a database management system with zero configuration - it just works.
Key Point
SQLite’s footprint size of under 1MB and benchmarks of 600-700 TPS on Raspberry Pi hardware[1] makes this lightweight, battle-tested database able to handle almost all simple home automation use cases.
With over 20 years of development, SQLite has a plethora of resources and integrations available within the open source community. Check out the Home-Assistant framework which integrates SQLite with many popular IoT devices to serve most of these home automation needs. While SQLite excels at its intended purpose, the authors did not design it to handle many of the cutting-edge application demands of modern times.
Key Point
For high-performance IoT applications that require sub-second level granularity and the ability to capture events from multiple sensors simultaneously, SQLite may fall short.
These resource requirements typically move beyond simple home automation and branch into more advanced commercial applications like Smart Manufacturing, Remote Patient Monitoring, and Autonomous Driving systems. These system requirements of capturing several data streams every few milliseconds can quickly scale to the thousands or millions of transactions per second. So, what are some good database options for these high performance IoT applications?
For High Throughput, Industrial IoT Applications

To meet the highly resource intensive task of operating a car with minimal human intervention, the Huawei ADS 2.0 system leverages 27 sensors (one LiDAR, three mm wave radars, 12 ultrasonic radars and several cameras)[2]
Key Point
Capturing Industrial IoT (IIoT) data streams can be highly time sensitive and expensive, where excess latency in capturing large volumes of data can be the difference between smoothly navigating a 5,000 pound vehicle through traffic, or painstakingly navigating the world of expensive insurance claims.
The difference in performance needed for the simple home automation projects relative to these IIoT projects becomes apparent when comparing the different chips these projects use to execute their work flows. For example, see the differences in the Google Nest Smart Home Hub compared to the Tesla FSD Hardware 3.0 used for autonomous driving:
The Tesla HW chip has 4x the ram, 6x the cpu parallelization, and more than 5x the power consumption[3][4]. It doesn’t take a PhD in electrical engineering to understand why the chip used to autonomously operate your car needs more performance than the chip used to turn on your lights and play music. So how does this fast paced environment dictate the databases needed to succeed?
The Time Series Database (TSDB)
One common feature among all of these high throughput scenarios led to an opinionated design decision in a certain class of databases. Platforms began orienting around collecting information along an axis of time, these databases are aptly called Time Series Databases.
Key Point
By enforcing records to include a timestamp component, TSDB systems can reliably index and partition along this dimension, increasing the efficiency and speed of storing and querying this data based on time scales.
Modern commercial needs of IoT applications as discussed above, combined with a blossoming Cloud Infrastructure industry have contributed to the popularization of these Time Series Databases, Highlighting a few of the big players in the industry below:
InfluxDB: The Market Leader
Most well known and established TSDB, but limited support and constantly shifting APIs have stoked developers’ frustrations

➡️ Started In 2012
⭐️ Stars on Github: 28.1k
🌗 Hybrid Open/Closed Source
Key Point
InfluxDB is by far the most well known and established player in the TSDB space[5].
They achieved dominance by being one of the first to provide the horse power necessary to ingest millions of records per second. Unfortunately, In flux is not just the name of the database, but also the state of its offerings, as companies have struggled to migrate to its newest 3.0 version in April of last year which revamped the APIs.
Though their brand new architecture boasts some massive improvements in storage costs and query performance, one fact exists that will heavily discourage many engineers from taking on InfluxDB for new IoT projects - the lack of a stand alone binary for version 3 that can be deployed to IoT devices.
Key Point
If you want to use the latest and greatest version of InfluxDB, you need to do so through their managed instances[6].
One can find various threads across the internet of team members pushing release dates for the open source edition again and again as many developers on timelines are forced with the decision of investing in an EOL product with 1.8, or looking to other databases in the space that can meet the same demands.
TimescaleDB: A Rising Star
Extending PostgreSQL to new heights by shipping continuous improvements in its roadmap, though its lack of distributed architecture support could potentially be restrictive in horizontal scaling

➡️ Founded 2015
⭐️ Stars on Github: 16.8k
🌝 OpenSource
TimescaleDB actually started out of frustration from the changing roadmap and lack of focus the company encountered while working with InfluxDB[7]. The spirt of focus and simplicity shines in TimescaleDB’s careful design decisions.
Key Point
TimescaleDB operates as a PostgreSQL Extension, leveraging the proven technology of PostgreSQL as its foundation.
Like all TSDBs, TimescaleDB requires timestamps on all record insertions, which it then uses to automatically organize and store the data into chunks of time intervals. TimescaleDB uses a clever, transparent technique of automatically compressing rows of data into a columnar format in order to drastically increase query performance and reduce storage costs[8]. TimescaleDB’s query performance is fast. Running the benchmark query on my M1 Mac returned rows from a 1 million row dataset in under 1 ms (around .3 ms to be exact)[9]. That’s what people in the know usually refer to as being ‘fast af boyyy.’
Key Point
While TimescaleDB instances clearly exemplify strong performance, I am curious how far TimescaleDB can scale for truly massive operations. At the end of 2023, In order to reduce complexity and optimize development capacity on their single node feature, TimescaleDB deprecated its Multi-Node, Distributed feature.
TimescaleDB claims they have scaled a single node deployment to 2 million inserts per second which they argue should be sufficient for an individual node[10]. Around the same time, TimescaleDB started offering tiered storage which keeps newer more frequently accessed data in a ‘hot’ performant storage, and less frequently accessed older data in a cold object storage. The team purports this automated categorization of data gives developers the best of both worlds by storing older data in cheaper object storage to reduce cost while prioritizing performance where you need it.
But what about cases where deployments need to scale nodes horizontally or where there is a natural controller-agent hierarchical relationship where the controller must consume all of the agents metrics to make decisions. Supporting such massive implementations common across areas like the management of city traffic infrastructure, fleet of vehicles, or energy grids would require a lot of custom development to roll up all the agents in a reliable and available manner. These scenarios naturally fit the hierarchical relationship of a cluster deployment, which is no longer supported by TimescaleDB.
GreptimeDB: Delivering Unified Scalability
Developing an innovative high-performance architecture in a decoupled, yet unified capacity

➡️ Founded 2022
⭐️ Stars on Github: 4k
🌝 OpenSource
GreptimeDB brings a fresh perspective and design to the TSDB space. Despite being a relatively newer codebase, it has already garnered a significant following, evidenced by its 4k stars on GitHub - and for a good reason. GreptimeDB’s benchmarks rank among some of the highest performing TSDB’s.
Key Point
One of GreptimeDB's standout features is its impressive write performance, which surpasses even that of TimescaleDB by around 20% in my benchmarks.[9:1]
This capability positions it as a strong contender for high-throughput scenarios common in IoT environments. Particularly with its innovative architecture that integrates three distinct node types into a single model.
This three-node system, comprising MetaSrv, Frontend, and DataNode, potentially addresses some of the key shortcomings of TimescaleDB by decoupling the scaling of different infrastructure components[11]:
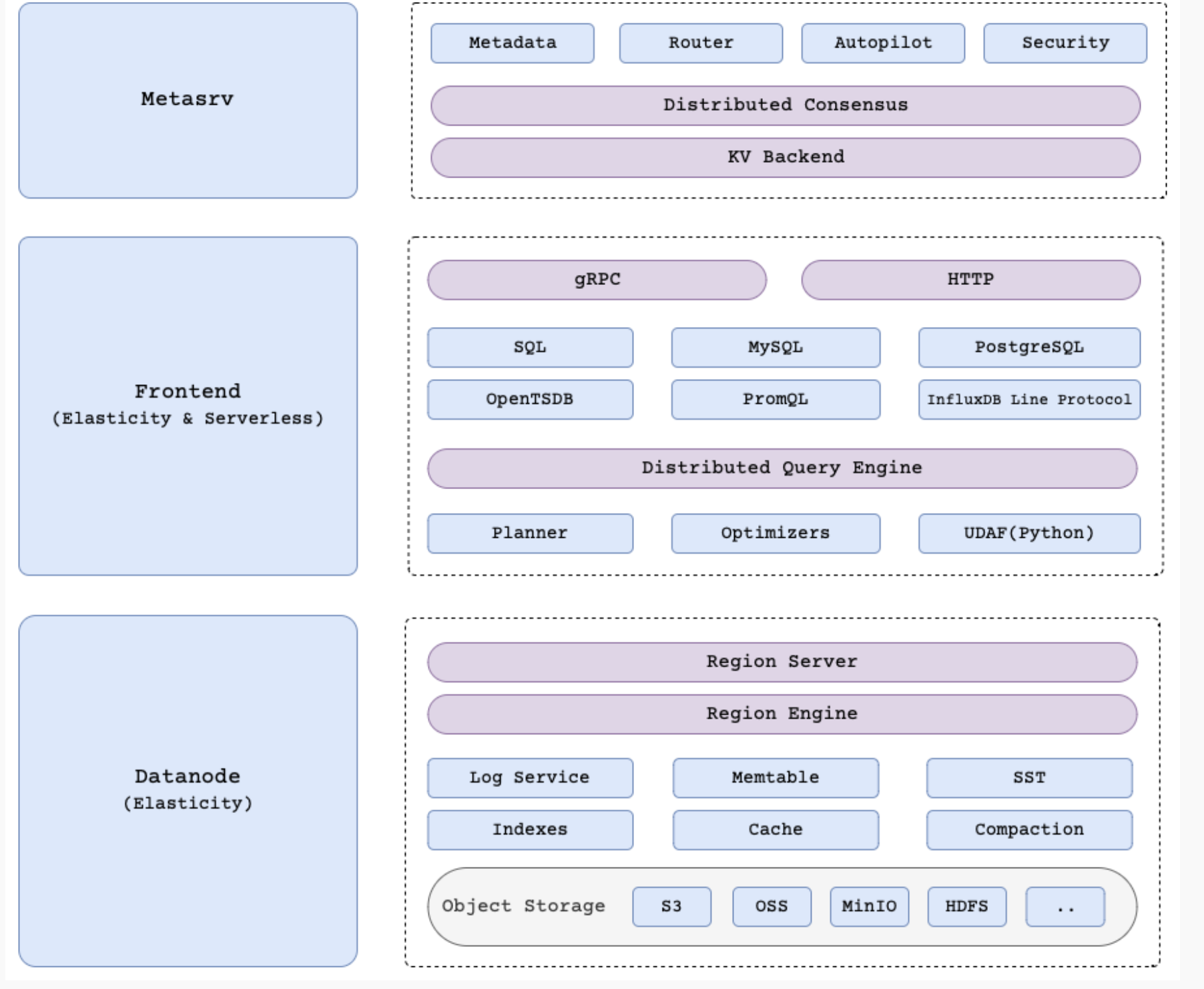
- MetaSrv (Metadata Service): This node manages metadata and coordinates the cluster. By isolating metadata operations, GreptimeDB ensures that metadata handling does not become a bottleneck, even as data volumes and query loads increase.
- Frontend: This node handles client requests and query processing. By decoupling the frontend from data storage, GreptimeDB allows for independent scaling of query processing capabilities. This separation ensures that query performance remains high, even under heavy query loads.
- DataNode: This component is responsible for managing the storage and retrieval of data from the backing object storage. GreptimeDB can scale the storage required to store data, independently from the compute required to operationally manage it. This allows for the storage of massive data sets by small resource constrained devices.
Key Point
GreptimeDB’s architecture helps to overcome potential limitations faced by TimescaleDB, particularly in scenarios requiring horizontal scalability and hierarchical deployment structures.
The decoupled design ensures that each component can be scaled according to its specific needs, making it suitable for complex implementations such as city traffic infrastructure management, fleet vehicle monitoring, and energy grid management. In these use cases, the hierarchical relationship between controllers and agents can be effectively managed, providing reliable and scalable solutions without the need for extensive custom development. However, as a new entrant with a rapidly evolving platform, GreptimeDB may face challenges in providing robust developer support channels.
While GreptimeDB’s architecture decouples these different components to help mitigate bottlenecks, the purpose-built design solves for the most common scenarios that many IoT deployments face today, specifically unifying metrics and logs into one database.
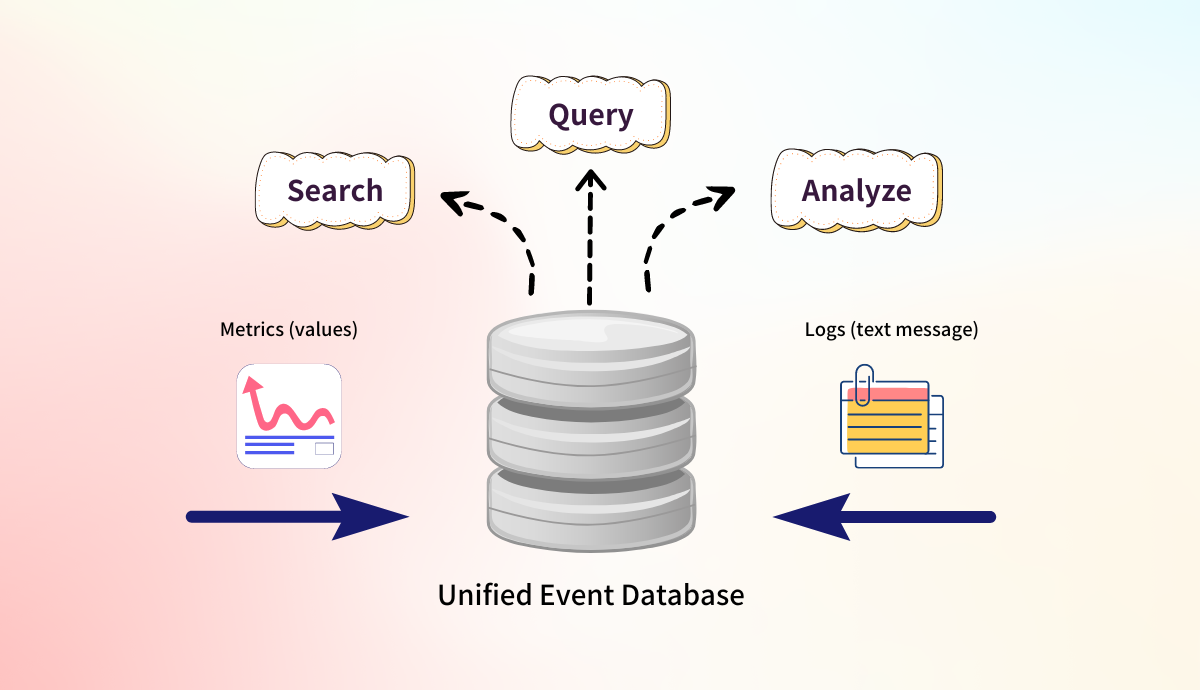
GreptimeDB provides easily configurable hooks to ingest and structure system logs into a common event interface that metrics data also conforms to. Greptime accomplishes this unification by enforcing all event data to have a timestamp, payload, and context and relying on the implementing engine to transform ingested data to the event interface as described. With GreptimeDB’s clever abstraction design, everything is an Event. Whether it’s unstructured text from an application log, or discrete numerical values emitted from a systemd process, users can easily configure the ingestion of all the relevant events for their use case and seamlessly query and collate that data downstream
Key Point
Greptime’s unified database can support common IoT support cases right out of the box.
Final Thoughts
Choosing the right database for IoT applications depends on specific needs and constraints. Here's a concise overview:
- SQLite: Ideal for simple home automation with low resource needs. It's lightweight, reliable, and easy to maintain, but not suitable for high-performance or large-scale applications.
- InfluxDB: A market leader in TSDBs with strong ingestion and query performance. However, frequent API changes and lack of a standalone binary for its latest version can be problematic for IoT deployments.
- TimescaleDB: Built on PostgreSQL, it offers excellent query performance and compression. The recent removal of multi-node support limits its scalability, possibly making it less ideal for massive-scale IoT projects.
- GreptimeDB: A newcomer with a flexible, scalable architecture that decouples metadata management, query processing, and data storage. This design makes it well-suited for complex, high-throughput IoT applications, though it may lack mature support channels found in more established databases.
Key Point
Each database offers unique advantages, and the best choice depends on aligning these capabilities with your specific IoT project requirements.
Robust SQLite benchmarks by University of Wisconsin Researchers: https://www.vldb.org/pvldb/vol15/p3535-gaffney.pdf ↩︎
Paul Tan, Trusted Automotive News Source based out of Malaysia: https://paultan.org/2023/12/28/huawei-aito-m9-launched-in-china ↩︎
Wiki Chip Analysis on FSD: https://en.wikichip.org/wiki/tesla_(car_company)/fsd_chip ↩︎
Tear Down of Google Nest Hub Hardware: https://electronics360.globalspec.com/article/17053/teardown-google-nest-hub-2nd-gen
 ↩︎
↩︎DB Engines Interest rankings based on social media mentions, Google Trends, and job postings: https://db-engines.com/en/ranking/time+series+dbms ↩︎
InfluxDB Pushes back on Fall 2024 launch of Community Edition: https://community.influxdata.com/t/influxdb-3-0-release-timeline/31845/9 ↩︎
TimescaleDB blog on InfluxDB’s failures: https://www.timescale.com/blog/what-influxdb-got-wrong/ ↩︎
TimescaleDB Architecture and design: https://github.com/timescale/docs.timescale.com-content/blob/master/introduction/architecture.md ↩︎
Repositories used to execute TimescaleDB and GreptimeDB Benchmarks. All benchmarks were run on 2021 Apple M1 Pro 10x 2.06 GHz - 3.22 GHz; 32GB Ram Timescale (v 2.15.2) and GreptimeDB (v0.9). Results as below:
(Bench Source https://github.com/timescale/tsbs and https://github.com/GreptimeTeam/tsbs):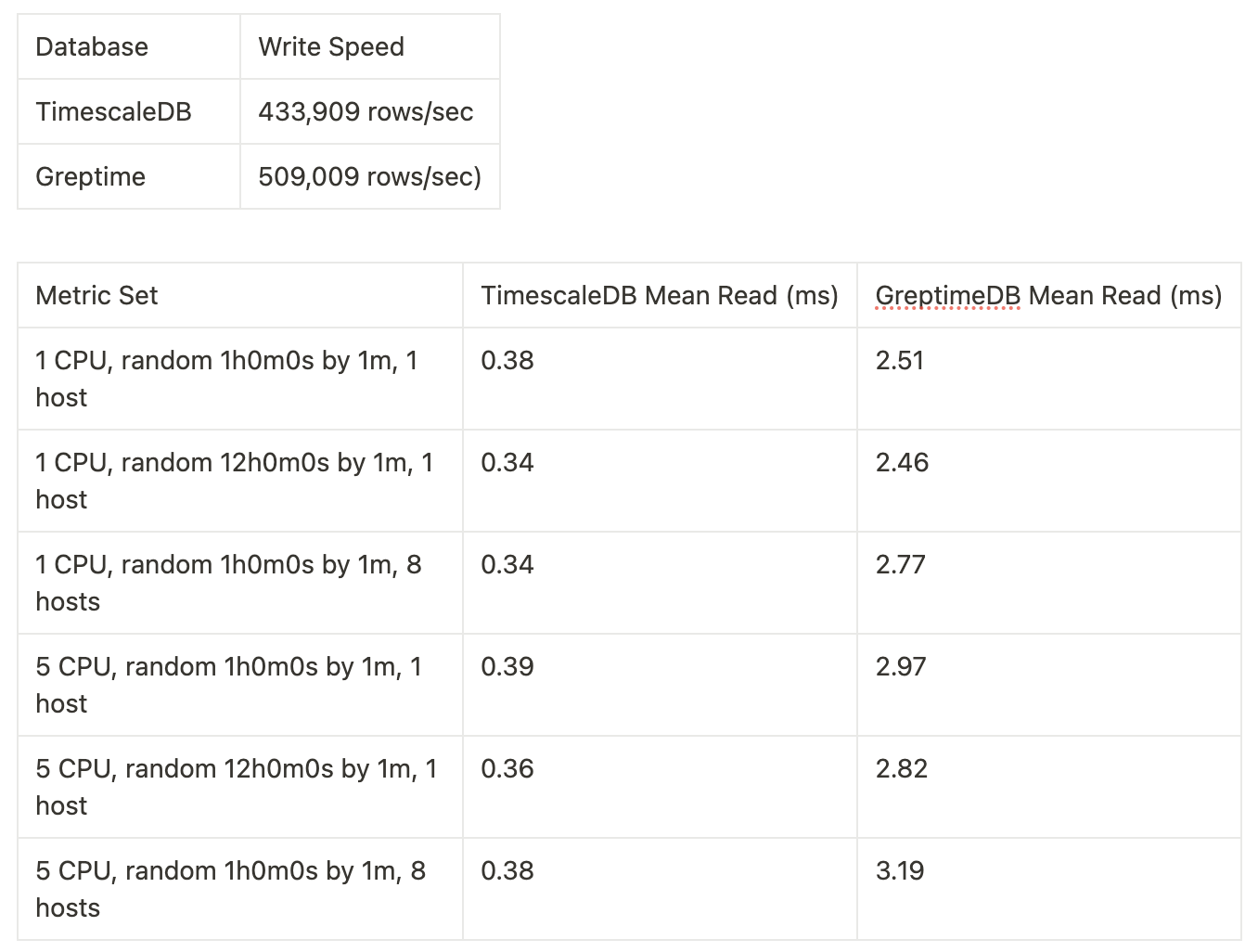 ↩︎ ↩︎
↩︎ ↩︎Timescale announces the deprecation of multi node support as of 2.13: https://github.com/timescale/timescaledb/blob/main/docs/MultiNodeDeprecation.md ↩︎
GreptimeDB discussion on scaling multi node support: https://docs.greptime.com/contributor-guide/overview ↩︎




