
On this page
GreptimeDB is a cloud-native, high-performance time-series database designed to provide users with flexible time-series data management solutions.
Unified Time-Series Data Handling
When managing data, we prioritize not just traditional Metrics but also the integration of timestamps and contextual information. GreptimeDB can manage and process various time-series data, including Events, Logs, and Traces. This unified approach enables seamless integration and analysis of diverse data, allowing comprehensive system monitoring and maximizing data value.
sql
SELECT
time,
host,
approx_percentile_cont(latency, 0.95) RANGE '15s' as p95_latency,
count(error) RANGE '15s' as num_errors,
FROM
metrics INNER JOIN logs on metrics.host = logs.host
WHERE
time > now() - INTERVAL '1 hour' AND
matches(path, '/api/v1/avatar')
ALIGN '5s' BY (host) FILL PREVStart with Familiar Protocols
GreptimeDB supports multiple protocols for writing and querying time-series data. Whether you prefer SQL, Prometheus, InfluxDB, or OpenTSDB, GreptimeDB ensures a smooth transition in data writing processes. It offers both SQL and PromQL (Prometheus Query Language) for querying data, providing powerful and flexible data retrieval capabilities that help you quickly manage time-series data without extra learning costs.
Ubiquitous Time-Series Data
One of GreptimeDB's strengths is its flexible deployment capabilities. It can operate in the cloud or at the edge, leveraging edge computing advantages. By processing data at the source, GreptimeDB can significantly reduce data transmission, saving up to 97% in bandwidth. This design eliminates lengthy data pipelines, directly enhancing system throughput.
Cloud-Native & Scalable
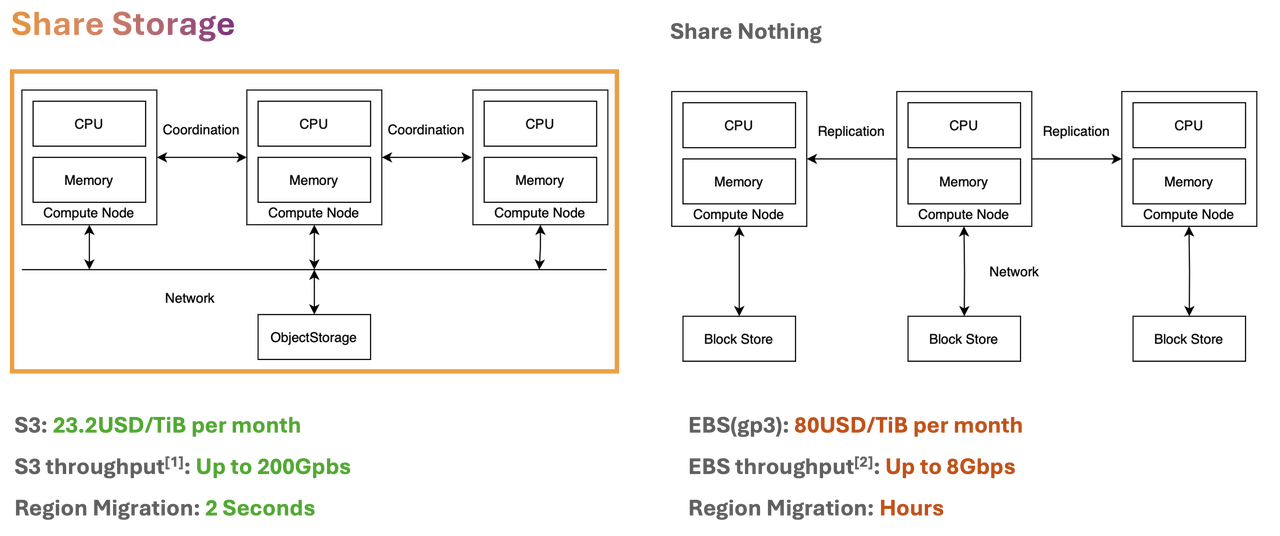
GreptimeDB's architecture fully utilizes cloud-native advantages, employing a shared storage model with S3 as a storage medium. Compared to EBS (gp3), S3 offers a cost reduction of 75% while providing up to 200 Gbps throughput on a single compute resource. This architecture lowers storage costs and performs exceptionally well in large-scale data processing. Additionally, it dramatically improves the efficiency of partition migrations, reducing migration time from hours to seconds or even milliseconds, ensuring zero downtime and business continuity.
Modular Design
Building a database system from scratch is complex, involving numerous critical components such as Catalogs, SQL parsers, data type systems, WAL, storage, optimizers, and query engines. Each component requires substantial resources and time to develop.
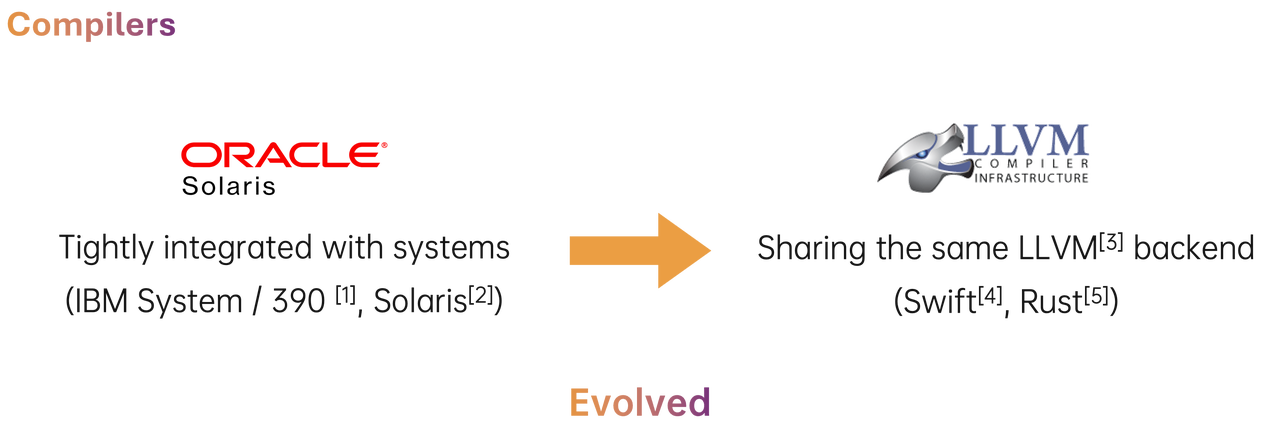
However, the trend in software engineering is moving towards modular design. The evolution of compilers, exemplified by LLVM, has enabled languages like Swift and Rust to share backends, accelerating technology iteration and sharing. Similarly, a modular component design in database systems can significantly speed up development and enhance flexibility.
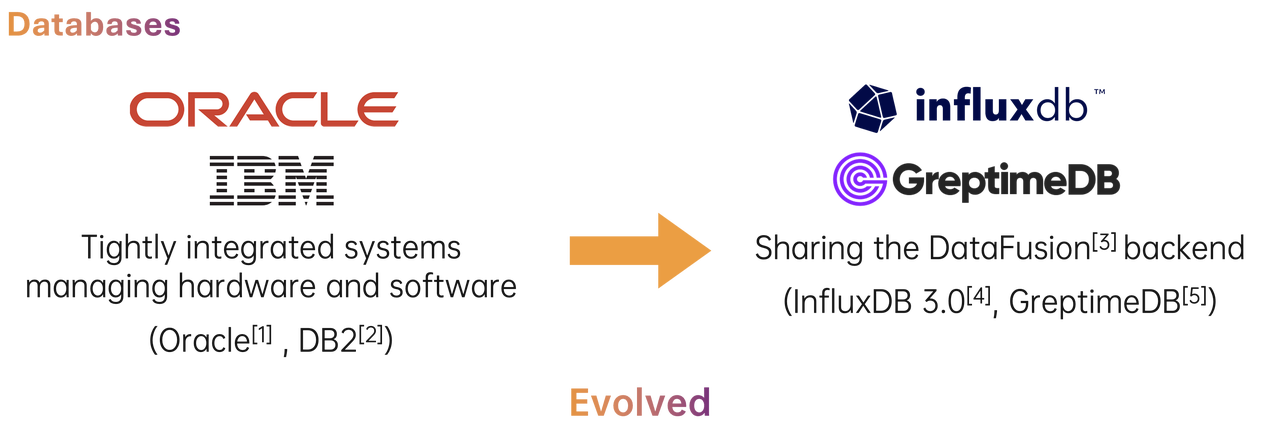
Building Time-Series Databases on Apache Open Source Projects
In constructing our time-series database system, we leverage several key Apache open-source projects:
- Apache Arrow: Provides an efficient in-memory columnar format for fast random access and in-memory data processing.
- Apache DataFusion: A fast, embeddable, and scalable query engine offering SQL and DataFrame APIs, utilizing Apache Arrow as its memory model for efficient data processing.
- Apache OpenDAL: Offers a unified data access layer that simplifies the integration and management of various data sources.
- Apache Parquet: A columnar storage format optimized for storing and reading large-scale datasets.
- Apache Kafka (optional): Serves as a Remote WAL, supporting region migration.
Extending SQL
In time-series data processing, querying and aggregating data over specific time ranges is often necessary. However, traditional SQL has limitations in natively supporting time-series queries. To address this, GreptimeDB introduces extended SQL syntax that combines the flexibility of SQL with enhanced native time-series support.
sql
SELECT
ts,
avg(temp) RANGE '1d' FILL LINEAR.
FROM
temperature
WHERE
city="beijing" and ts < 1682985600000
ALIGN '1d';In GreptimeDB, we introduce the ALIGN keyword in SELECT statements to set the step size for time-series queries, aligning time with the calendar. The RANGE keyword specifies the aggregation period, while FILL LINEAR fills in missing data points with average values. These extensions make time-series queries more flexible and efficient.
Supporting PromQL
To be fully compatible with the Prometheus ecosystem, GreptimeDB has implemented comprehensive support for PromQL, currently one of the most compatible third-party independent implementations, reaching up to 82%. We integrated PromQL as a new dialect into the DataFusion execution engine, enabling GreptimeDB to better meet the demands of users within the Prometheus ecosystem.
Easy Multi-Cloud Support
GreptimeDB utilizes Apache OpenDAL as its data access layer, providing a unified API to connect to most existing storage services (supporting a wide range of object storage services such as AWS S3, Google Cloud Storage, Alibaba Cloud OSS). Through open-source collaboration, we have worked with the community to optimize OpenDAL’s read-write performance, ensuring that it can fully utilize the bandwidth of object storage services and enhance data processing efficiency.

Thriving with Open Source
We are committed to growing with the open-source community. GreptimeDB’s core developer Ruihang Xia has become a PMC member of the Apache DataFusion project, actively participating in and promoting community development. Additionally, we have contributed the datafusion-orc library to the datafusion-contrib organization and plan to donate the project to Apache soon, as the Rust implementation repository of ORC (datafusion-orc#120). These efforts contribute not only to the advancement of GreptimeDB but also to the flourishing of the open-source ecosystem.
Implement Once, Benefit All
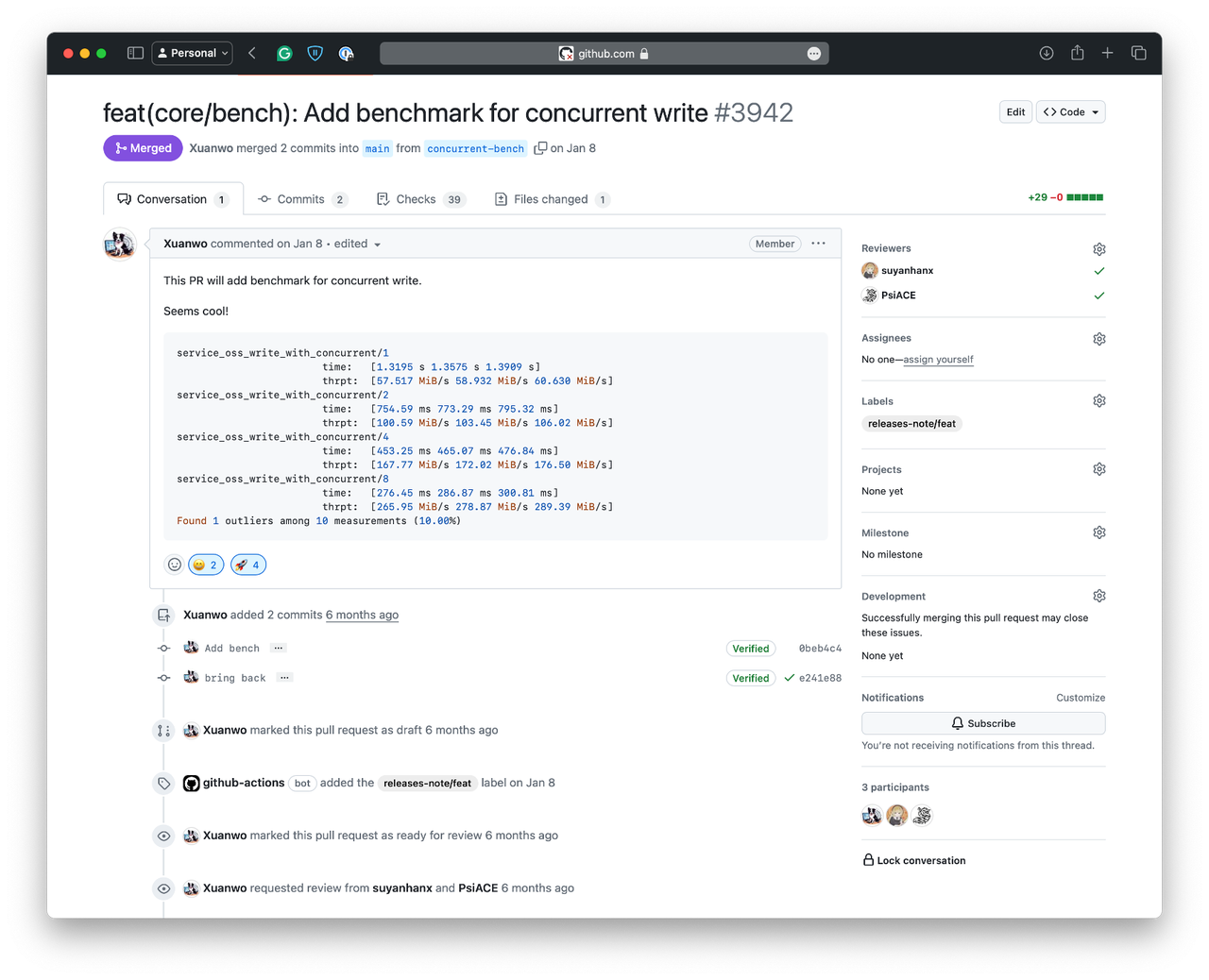
One of the great things about the open-source community is that improvements made upstream benefit all downstream projects. Inspired by academic research, we contributed a concurrent upload feature to OpenDAL, achieving linear growth in write performance. This not only boosts GreptimeDB’s performance but also benefits other projects relying on OpenDAL, truly reflecting the “Implement once, benefit all” philosophy.
May Open Source Be With You
In today’s open-source community, projects are interconnected and contribute to each other, forming a symbiotic relationship where one enhances the other. Several open-source projects contributed by different communities, which have been widely adopted across various ecosystems, embodying the collaborative spirit and shared values of the open-source world. e.g.,:
- GreptimeDB contributed the
datafusion-orcandpgwireprojects.datafusion-orchas been adopted by both GreptimeDB and Databend, whilepgwireis used by GreptimeDB and CeresDB/HoraeDB. - Databend spearheaded the
OpenDALandopensrv-mysqlprojects.OpenDALhas gained wide adoption across several communities, including Vector, ParadeDB, QuestDB, RisingWave, and GreptimeDB, whileopensrv-mysqlis also used by GreptimeDB. - RisingWave contributed the
arrow-udfproject, which is utilized by RisingWave and has also been adopted by Databend. - CeresDB/HoraeDB led the
sqlnessproject, which is also used by GreptimeDB. - InfluxDB open-sourced the
DataFusionproject, which has been widely adopted by multiple communities, including GreptimeDB and CeresDB/HoraeDB.
Conclusion
In this fast-evolving technological era, building and managing a time-series database is not just a technical challenge but a collaborative journey with global developers. Through its flexible architecture, strong protocol support, and deep engagement with the open-source community, GreptimeDB showcases the endless possibilities of modern database systems. Whether in the cloud or at the edge, for data storage or query optimization, we remain committed to modularity and open source, pushing technology forward alongside developers worldwide.
Reference
[1] S3 throughput : Dominik Durner, Viktor Leis, and Thomas Neumann. 2023. Exploiting Cloud Object Storage for High-Performance Analytics. Proc. VLDB Endow. 16, 11 (July 2023), 2769–2782. https://doi.org/10.14778/3611479.3611486
[2] EBS throughput: https://docs.aws.amazon.com/ebs/latest/userguide/ebs-volume-types.html
[3] IBM System / 390: https://en.wikipedia.org/wiki/IBM_System/390
[4] Solaris: https://en.wikipedia.org/wiki/Oracle_Solaris
[5] LLVM: https://llvm.org
[6] Swift: https://www.swift.org
[7] Rust: https://www.rust-lang.org
[8] Oracle: https://www.oracle.com/database/
[9] DB2: https://www.ibm.com/db2
[10] InfluxDB: https://www.influxdata.com
[11] GreptimeDB: https://greptime.com
[12] sunng87/pwrire: https://github.com/sunng87/pgwire
[13] datafuselabs/opensrv: https://github.com/datafuselabs/opensrv
[14] risingwavelabs/arrow-udf: https://github.com/risingwavelabs/arrow-udf
[15] ceresdb/sqlness: https://github.com/CeresDB/sqlness
[16] apache/arrow: https://arrow.apache.org/
[17] apache/datafusion: https://datafusion.apache.org/
[18] apache/opendal: https://opendal.apache.org/
[19] apache/parquet: https://parquet.apache.org/
[20] apache/kafka: https://kafka.apache.org/
[21] datafusion-contrib/datafusion-orc: https://github.com/datafusion-contrib/datafusion-orc
[22] GreptimeDB/promql-parser: https://github.com/GreptimeTeam/promql-parser
[23] datafusion-contrib/datafusion-orc#120: https://github.com/datafusion-contrib/datafusion-orc/issues/120
[24] apache/opendal#3942: https://github.com/apache/opendal/pull/3942
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




