
On this page
We're thrilled to announce the official release of GreptimeDB v0.15! This major update emphasizes system flexibility, performance optimization, and observability enhancements, bringing substantial improvements across data processing, Pipeline management, and operational capabilities.
Development Overview
From v0.14 to v0.15, the Greptime team and community contributors have achieved remarkable progress together👇
Development Statistics
- 253 commits successfully merged
- 927 files modified
- 35 individual contributors participated
- 6 first-time contributors joined the project
Improvement Distribution
- 50+ feature enhancements: Including process management system, Pipeline integrations, and other core capabilities
- 30+ bug fixes: Continuously improving system stability
- 10+ code refactoring efforts: Optimizing code architecture and maintainability
- 4 breaking changes: Laying foundation for future development
- 2 performance optimizations: Including SimpleBulkMemtable and batch operation improvements
- Extensive testing work: Ensuring feature reliability
👏 Special thanks to the 26 individual contributors for their dedication and the 6 new community members who joined us! We welcome more developers interested in observability database technology to join the Greptime community.
Core Feature Highlights
Pipeline Integration Enhancements
This update significantly strengthens Pipeline's data processing capabilities👇
New Protocol Integrations of Pipeline
- Prometheus Remote Write
- Loki Write Protocol
Both protocols utilize the x-greptime-pipeline-name parameter in HTTP headers to specify the Pipeline for transformations, providing users with more robust and flexible data processing capabilities, such as replacing Prometheus metric labels and structured log processing.
Introducing Vector Remap Language (VRL) Processor
The VRL processor provides powerful programming capabilities for advanced data transformation scenarios. Unlike simple processors, VRL enables users to write flexible scripts for manipulating context variables and implementing complex data processing logic.
Note:
VRLis a data transformation expression language introduced by Vector. For detailed information, please refer to the official documentation.VRLscript execution consumes more resources, so please evaluate usage based on your specific scenarios. For more details aboutVRL, you can refer to this article "How Vector Remap Enhances Log Data Parsing and Storage in Observability".
The VRL processor currently has one configuration option: source (source code). Here's an example:
yaml
processors:
- date:
field: time
formats:
- "%Y-%m-%d %H:%M:%S%.3f"
ignore_missing: true
- vrl:
source: |
.from_source = "channel_2"
cond, err = .id1 > .id2
if (cond) {
.from_source = "channel_1"
}
del(.id1)
del(.id2)
.This configuration uses | in YAML to initiate multi-line text, allowing you to write the entire script.
VRL Processor Key Points:
- Script termination: Must end with a standalone
.line, indicating the return of the entire context. - Type restrictions: Return values cannot contain
regextype variables (can be used during processing but must be deleted before return) - Type conversion: Data types processed through
VRLwill be converted to maximum capacity types (i64,u64, andTimestamp::nanoseconds)
Bulk Ingestion: High-Throughput Writing Solution
For high-throughput, latency-tolerant scenarios, we've introduced the Bulk Ingestion feature. This isn't a replacement for existing write protocols but rather an effective complement for specific use cases.
Scenario Comparison
| Write Method | API | Throughput | Latency | Memory Efficiency | CPU Usage | Use Case | Limitation |
|---|---|---|---|---|---|---|---|
| Regular Write | Write(tables) | High | Low | Medium | High | Simple applications with low latency requirements: such as IoT sensor data and scenarios where users expect immediate response | Lower throughput for large batch operations |
| Stream Write | StreamWriter() | Medium | Low | Medium | Medium | Continuous data streams with medium throughput, allowing multiple tables to share a single stream | More complex to use compared to regular writes |
| Bulk Write | BulkStreamWriter() | Highest | Slightly Higher | High | Medium | Maximum throughput for large batch operations: such as ETL pipelines, log ingestion, data migration, etc. | Higher latency, requires client-side data batching, one stream per table, multiple tables cannot share a single write stream |
Client Support
- Java Ingester: GitHub Repository
- Rust Ingester: GitHub Repository
Enhanced Operational Capabilities
Query Task Management
We've added query task view management functionality, enabling users to monitor and manage query tasks in the cluster in real-time. This includes viewing all running queries in the GreptimeDB cluster and the ability to terminate queries proactively.
Query Task View Example:
sql
USE INFORMATION_SCHEMA;
DESC PROCESS_LIST;Output:
yaml
+-----------------+----------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+-----------------+----------------------+------+------+---------+---------------+
| id | String | | NO | | FIELD |
| catalog | String | | NO | | FIELD |
| schemas | String | | NO | | FIELD |
| query | String | | NO | | FIELD |
| client | String | | NO | | FIELD |
| frontend | String | | NO | | FIELD |
| start_timestamp | TimestampMillisecond | | NO | | FIELD |
| elapsed_time | DurationMillisecond | | NO | | FIELD |
+-----------------+----------------------+------+------+---------+---------------+Query Termination:
When the PROCESS_LIST table identifies running queries, users can terminate them using the KILL <PROCESS_ID> statement, where <PROCESS_ID> is the id field from the PROCESS_LIST table:
sql
mysql> SELECT * FROM process_list;
+-----------------------+----------+--------------------+----------------------------+------------------------+---------------------+----------------------------+-----------------+
| id | catalog | schemas | query | client | frontend | start_timestamp | elapsed_time |
+-----------------------+----------+--------------------+----------------------------+------------------------+---------------------+----------------------------+-----------------+
| 112.40.36.208/7 | greptime | public | SELECT * FROM some_very_large_table | mysql[127.0.0.1:34692] | 112.40.36.208:4001 | 2025-06-30 07:04:11.118000 | 00:00:12.002000 |
+-----------------------+----------+--------------------+----------------------------+------------------------+---------------------+----------------------------+-----------------+
KILL '112.40.36.208/7';
Query OK, 1 row affected (0.00 sec)Dashboard Feature Extensions
New Dashboard Features👇
📊 Traces View Support: Enhanced observability experience
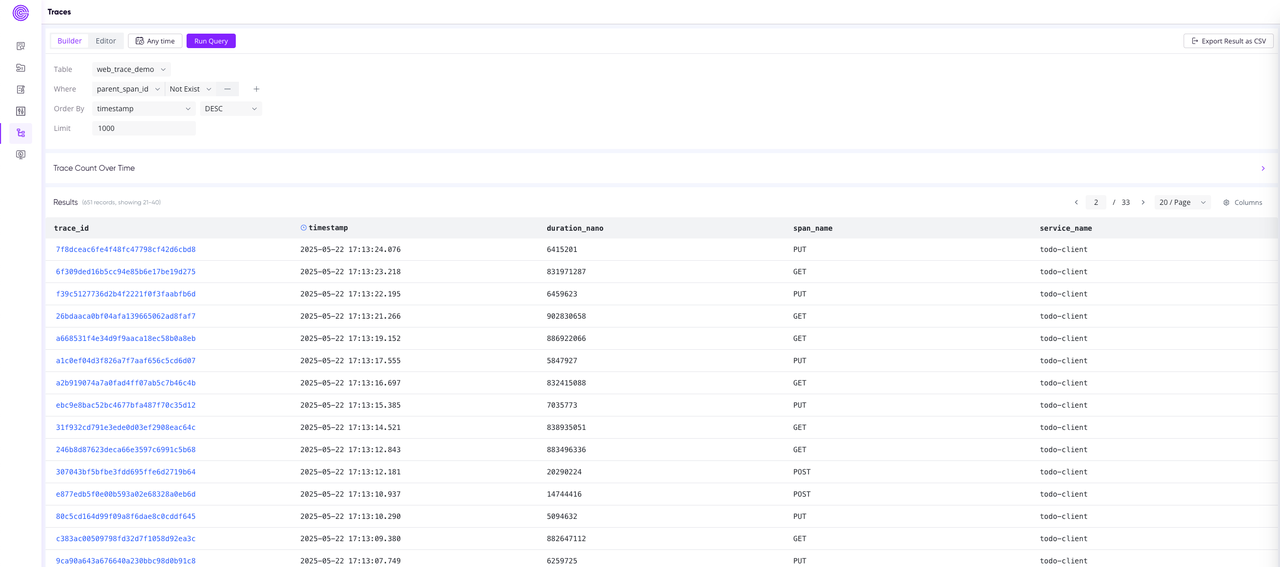
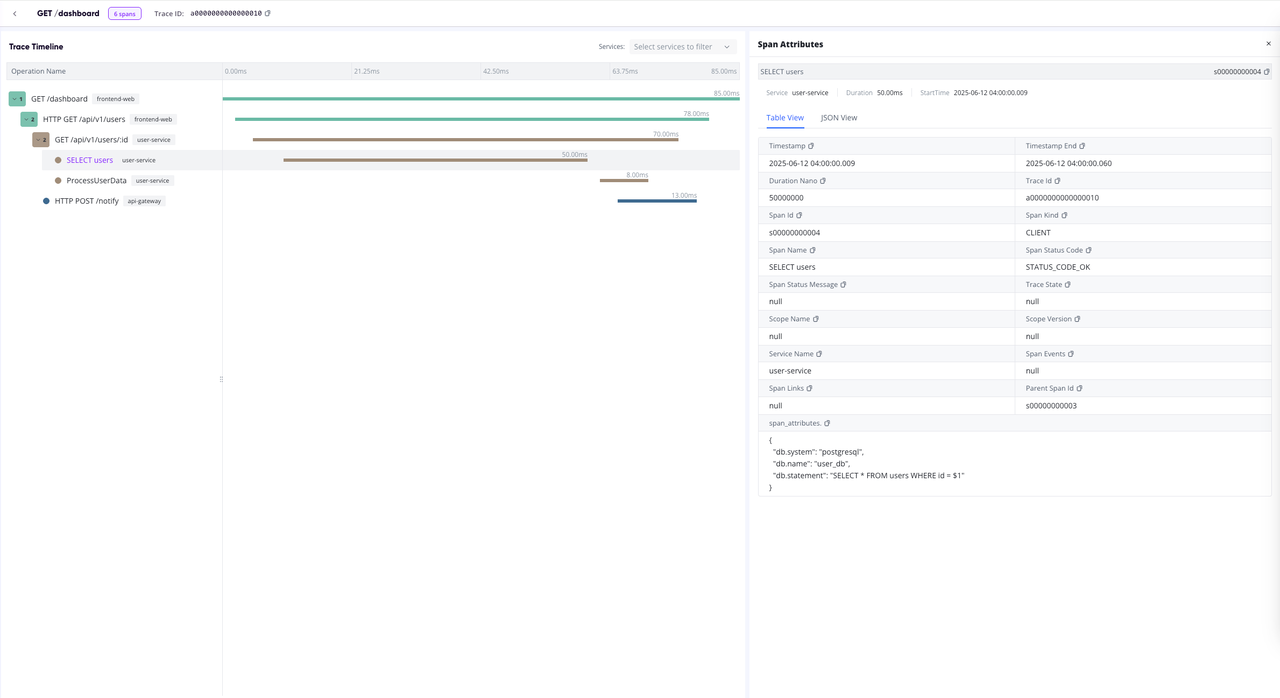
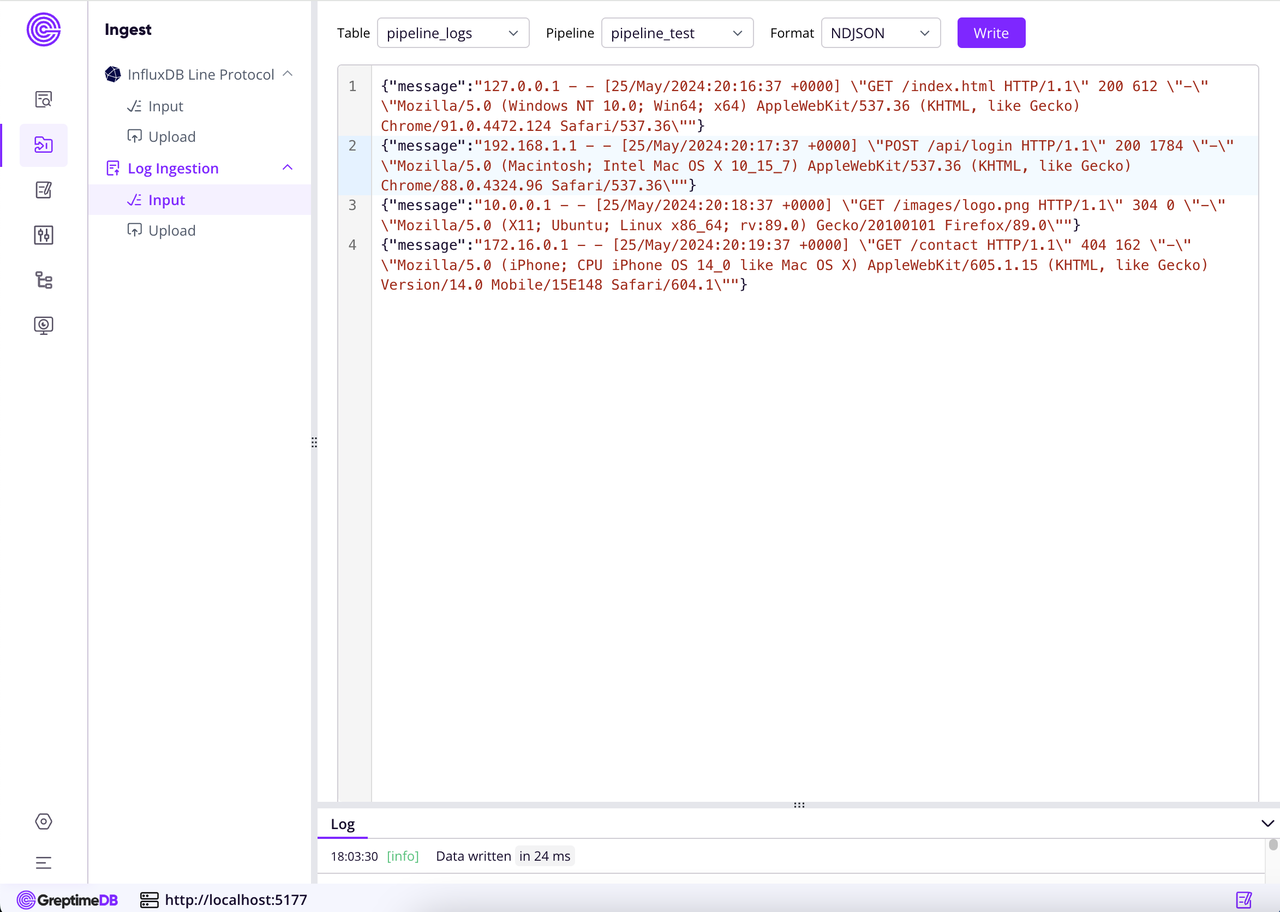
📝 Added log ingestion capability in data ingestion panel: Supports log writing through Pipeline, simplifying the log data ingestion and processing workflow.
Upgrade Guide
Compatibility:
- v0.15 is fully compatible with v0.14 (data and configuration)
- Direct upgrade recommended for v0.14 users
Upgrade Instructions:
- For detailed upgrade steps, please refer to the Upgrade Guide
- For upgrades from lower versions, please consult the corresponding version upgrade documentation
Future Roadmap
Following the v0.15 release, we will focus on:
- Feature refinement: Optimizing user experience
- Performance optimization: Improving system efficiency
- Reliability and stability enhancements: Building enterprise-grade product standards
These efforts will establish a solid foundation for the GreptimeDB v1.0 release.
Acknowledgments
Once again, we extend our heartfelt gratitude to the Greptime team and all community contributors for their dedication! We look forward to welcoming more developers to join the GreptimeDB community and collectively advance observability database technology.
Learn More:
- 📚 Documentation: Official Docs
- 💬 Repo & Community: GitHub
- 🌟 Get Started: Experience GreptimeDB v0.15 today!




