
On this page
- Speaker: Ruihang Xia
- Editor: Dennis Zhuang
Introduction
Hello everyone, I'm Ruihang (GitHub ID: @waynexia), currently working as a software engineer at GreptimeDB and also a PMC member of Apache DataFusion. Today I'd like to share some fundamental optimization techniques I've learned from the DataFusion community.
Although the title contains the word "fundamental," don't worry - nothing rocket-science-y here. The content I'm sharing today is relatively simple, but very practical. These techniques apply not only to SQL engines, but to most Rust projects as well.
About DataFusion
Before diving into optimization details, let me briefly introduce Apache DataFusion. According to the official description, DataFusion is an extensible query engine written in Rust, built on Apache Arrow. You can think of it as similar to DuckDB - a library-style analytical query engine.
DataFusion is now widely used in various projects and scenarios, with approximately 3,000 repositories on GitHub using it. In terms of performance, DataFusion performs well in various benchmarks (such as ClickBench). Looking at project activity, the community has grown severalfold since the project started in 2016/2017.
However, it's worth noting that the optimization techniques I'm sharing today aren't directly related to those benchmark rankings. We're focusing on more "fundamental" things—optimization ideas that can be reused across various Rust projects.
Optimization #1: Strategic Use of HashMap
Sometimes, Using a HashMap Is the Optimization
Let's start with the most common HashMap. Often, using a HashMap is itself an optimization strategy.
I recently discovered an interesting piece of code in GreptimeDB (related PR: GreptimeDB#6487):
rust
fn set_indexes(&mut self, options: Vec<SetIndexOption>) -> Result<()> {
for option in options {
if let Some(column_metadata) = self
.column_metadatas
.iter_mut()
.find(|c| c.column_schema.name == *option.column_name())
{
Self::set_index(column_metadata, option)?;
}
}
Ok(())
}This code needs to process two arrays: options and columns. The original implementation is O(n²)—for each option, it iterates through the columns array. When the number of columns or options increases, performance degrades rapidly.
The optimization is straightforward: first collect the smaller array into a HashMap, then use O(1) lookups when traversing the other array. This reduces the time complexity from O(n²) to O(n):
rust
fn set_indexes(&mut self, options: Vec<SetIndexOption>) -> Result<()> {
let mut set_index_map: HashMap<_, Vec<_>> = HashMap::new();
for option in &options {
set_index_map
.entry(option.column_name())
.or_default()
.push(option);
}
for column_metadata in self.column_metadatas.iter_mut() {
if let Some(options) = set_index_map.remove(&column_metadata.column_schema.name) {
for option in options {
Self::set_index(column_metadata, option)?;
}
}
}
Ok(())
}Although this example is quite basic, it reminds us: in scenarios requiring frequent lookups, HashMap is often the first choice.
Aggregation and Join Scenarios
In SQL query engines, the most common scenarios for HashMap are aggregation and join operations.
Taking aggregation as an example, here's a code snippet from the KiteSQL project:
rust
let mut group_hash_accs: HashMap<Vec<DataValue>, Vec<Box<dyn Accumulator>>> =
HashMap::new();
...
let entry = match group_hash_accs.entry(group_keys) {
Entry::Occupied(entry) => entry.into_mut(),
Entry::Vacant(entry) => {
entry.insert(throw!(create_accumulators(&agg_calls)))
}
};
...
for (acc, value) in entry.iter_mut().zip_eq(values.iter()) {
throw!(acc.update_value(value));
}This implementation is very intuitive: for each key combination in GROUP BY, use a HashMap to store the corresponding aggregation state (key is the group by value, value is the accumulator to compute).
Advanced: Optimizing HashMap Implementation
Even when using HashMap, we can make further optimizations:
1. Replacing Hash Function Implementation
The simplest and most general approach is to replace the HashMap implementation. For example, using ahashmap, which provides an API completely identical to the standard library's HashMap and can be used as a drop-in replacement, but often with better performance.
2. Clever Trick: Reusing Hash Seeds
This is an interesting optimization (DataFusion#16165): DataFusion does aggregation in two phases—first doing local aggregation in small batches, then merging into the final result.
The optimization is to have both HashMaps use the same random seed:
rust
/// Hard-coded seed for aggregations to ensure hash values differ
/// from `RepartitionExec`, avoiding collisions.
const AGGREGATION_HASH_SEED: ahash::RandomState =
ahash::RandomState::with_seeds('A' as u64, 'G' as u64, 'G' as u64, 'R' as u64);
...
/// Make different hash maps use the same random seed.
random_state: crate::aggregates::AGGREGATION_HASH_SEEDWith just this simple change, most ClickBench end-to-end benchmarks improved by ~10%.
The reason is: if the same hash function and seed are reused, the bucket distribution computed in the local HashMap can be directly preserved during the merge phase, reducing rehashing overhead.
3. Deep Customization: Building on HashTable
DataFusion has partially replaced the standard HashMap in its aggregator with a manual implementation based on lower-level hash table APIs, called ArrowBytesMap. It only supports binary and string keys.
Why do this? Because DataFusion has an obvious usage pattern: after each HashMap computation, all keys need to be extracted and combined into a bytes array for the next computation step. Using HashMap directly requires an additional conversion step, which is quite costly.
Based on the lower-level hash table API (where users are responsible for computing hashes, maintaining hash values, and maintaining indices, while the underlying layer only provides core algorithms like collision handling and slot finding), we gain more control:
- Batch operations: For example, this insertion code in DataFusion's
ArrowBytesMapfirst batch-computes hash values, then finds appropriate positions for insertion. - Reduced intermediate allocations: Directly maintaining vector-like or array builder structures internally, input values are appended directly and referenced through slices later, avoiding unnecessary memory allocations.
- Convenient APIs: Providing batch input/output and direct collection into Arrow Arrays.
Of course, I'm not encouraging everyone to implement their own HashMap in all scenarios. But when your code has obvious usage patterns and that part is indeed a performance bottleneck, using lower-level hash table APIs and deeply integrating business logic with data structures can often bring significant improvements.
Optimization #2: Code Specialization
Projects may be general-purpose, but code doesn't have to be. Specializing optimizations for different scenarios often yields substantial performance gains.
Case Study 1: String Processing Specialization
What type of strings are you processing? Pure ASCII or containing Chinese? A mix of ASCII and Chinese?
As you know, UTF-8 is variable-width, so indexing by position is O(n) (you have to scan from the start). But ASCII is different—each character is fixed at 1 byte, so the Nth character is at a fixed offset.
Based on this assumption, we can do many optimizations. Here are three examples from DataFusion:
- Faster reverse() string function for ASCII-only case #14195 - 30%~84% performance improvement
- Faster strpos() string function for ASCII-only case #12401 - 50% performance improvement
- Specialize ASCII case for substr() #12444 - 2~5x performance improvement for ASCII-only scenarios
Each optimization shows significant improvement. Put bluntly: performance often comes from extra branches and specialization. The more you're willing to write, the faster it can get.
Case Study 2: Timezone Specialization
What timezone does your data use? Do you need to consider quirky historical time-zone rules?
I only recently learned that historically, some places had timezone offsets that weren't whole hours, weren't whole minutes, or even weren't whole seconds. It makes sense when you think about it: before UTC or modern timekeeping was adopted, different places used local time, and the longitude difference from London would cause all sorts of "strange" offsets.
If your code doesn't need to handle these ancient timezones, or even only needs to handle UTC, many operations can be greatly simplified.
For example, the date_trunc function optimization (truncating a timestamp to minute, hour, second precision, etc.) (DataFusion#16859):
Original implementation: For each input timestamp, it faithfully converts and normalizes according to rigorous rules respecting all historical time-zone edge cases, then truncates. This is slow and cannot be vectorized because the underlying chrono library APIs process one at a time.
Optimization approach: First check input conditions:
- Is the timezone UTC (or no timezone)?
- Is the truncation unit "year/month" (these two units are tricky because their lengths vary)?
If truncating to "hour/minute/second" units, within the computer-supported time range, the conversion relationships for these units are constant. For example, one minute is always 60 seconds, regardless of timezone or timestamp.
rust
// fast path for fine granularity
// For modern timezones, it's correct to truncate "minute" in this way.
// Both datafusion and arrow are ignoring historical timezone's non-minute granularity
// bias (e.g., Asia/Kathmandu before 1919 is UTC+05:41:16).
// In UTC, "hour" and "day" have uniform durations and can be truncated with simple arithmetic
if granularity.is_fine_granularity()
|| (parsed_tz.is_none() && granularity.is_fine_granularity_utc())
{
let result = general_date_trunc_array_fine_granularity(
T::UNIT,
array,
granularity,
tz_opt.clone(),
)?;
return Ok(ColumnarValue::Array(result));
}By making more assumptions and pre-checks on input, and writing fast paths for common scenarios, overall performance significantly improves. This PR delivered a 7× speedup in some scenarios.
There's an even more interesting follow-up PR for date_trunc DataFusion#18356, which demonstrates some of the miscellaneous optimization techniques we'll discuss in part three.
Case Study 3: Data Range Specialization
Is your data a UUID or a u128? Or a smaller u8 or u16?
If the number range is small, you can directly use an array to simulate map behavior, completely avoiding hash computation.
The Cost of Specialization
Of course, specialization shouldn't be overdone. Here's a real example (slightly tongue-in-cheek):
Once, for static dispatch, we wrote a macro in GreptimeDB that matches on input data types and dispatches to specific type computation functions. This macro was nested three levels deep, with about a dozen types at each level. It compiled just fine—until it expanded to over 1,000 match arms.
The result? It even segfaulted at runtime. If the default stack size isn't increased, these 1000 branches would directly blow the stack.
rust
macro_rules! define_eval {
($O: ident) => {
paste! {
fn [<eval_ $O>](columns: &[VectorRef]) -> Result<VectorRef> {
with_match_primitive_type_id!(columns[0].data_type().logical_type_id(), |$S| {
with_match_primitive_type_id!(columns[1].data_type().logical_type_id(), |$T| {
with_match_primitive_type_id!(columns[2].data_type().logical_type_id(), |$R| {
// clip(a, min, max) is equals to min(max(a, min), max)
let col: VectorRef = Arc::new(scalar_binary_op::<
<$S as LogicalPrimitiveType>::Wrapper,
<$T as LogicalPrimitiveType>::Wrapper,
$O,
_,
....(An example of over-specialization)
So: appropriate specialization is fine, but don't overdo it; don't blindly specialize everything, as it doesn't always pay off.
The Cost of Compile Time
Besides manual specialization, we often write monomorphized code using Rust's type system with generic parameters, letting the compiler specialize for us.
But this brings another problem: compile times keep getting longer.
I tracked DataFusion's compile time changes over a period:
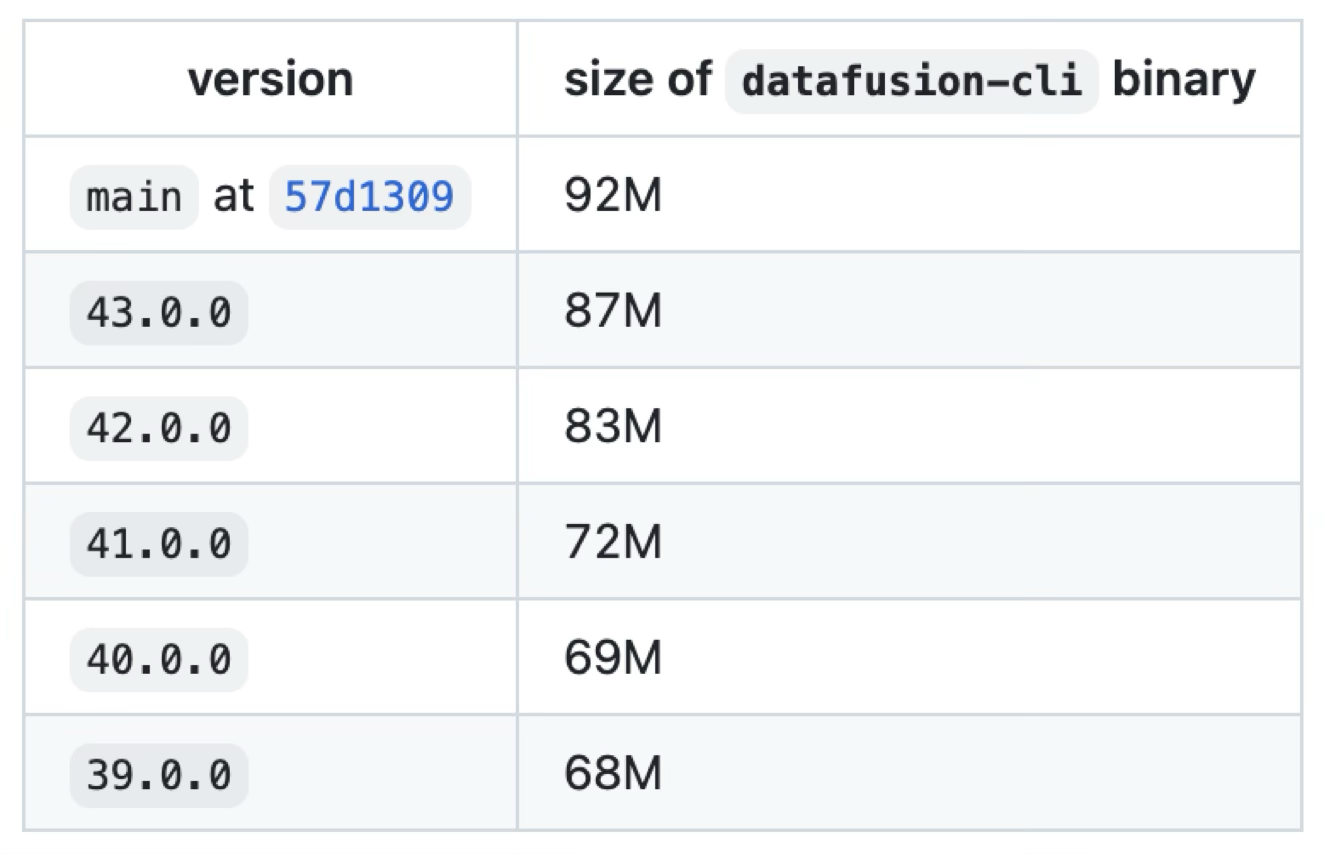
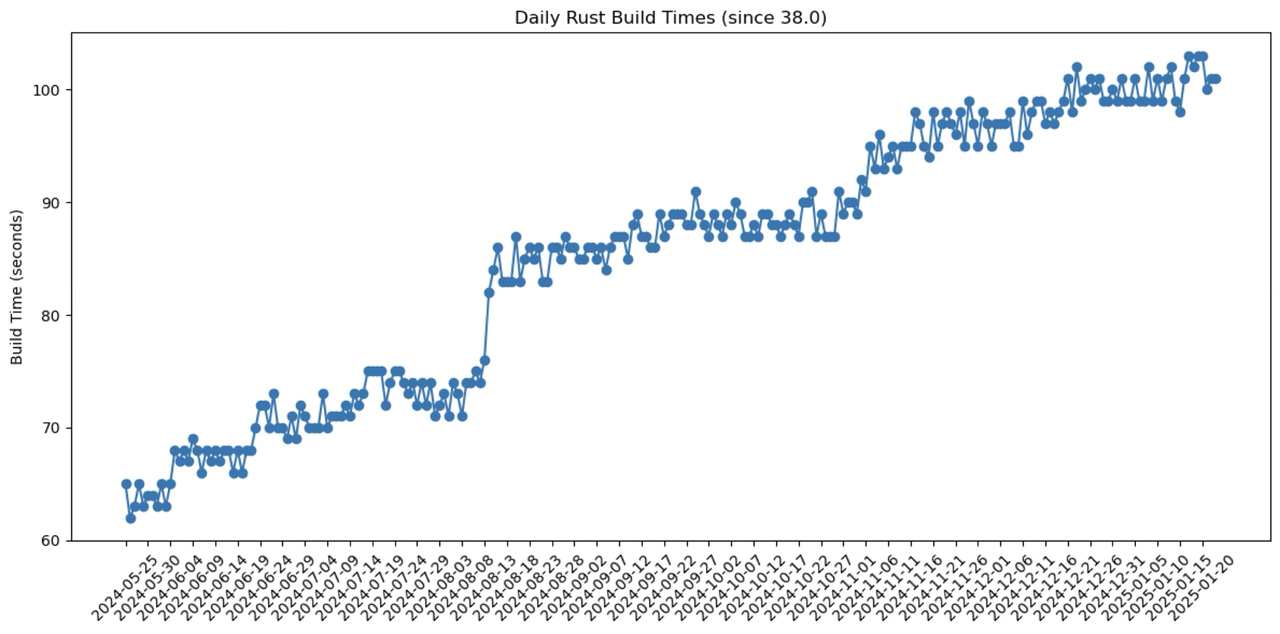
Over about half a year, DataFusion's compile time on my machine increased by about 80%, and binary size grew from 68M to 92M.
We don't have a definitive conclusion yet (feedback welcome), but we suspect it's due to excessive monomorphization. For example:
- Each operator and type gets expanded once
- Standard library iterator traits expand the most
- DataFusion's own tree visitor structures also expand heavily (because closures in parameters generate new code each time they're used)
Although we have these suspicions, there's no particularly good solution yet. These are fairly fundamental structures that are hard to change, and changing them might save compilation overhead but increase runtime overhead.
For comparison: although DataFusion now compiles quite slowly (over 100 seconds locally), this problem is even more severe in C++ projects—for example, ClickHouse takes half an hour to compile, so it's still acceptable.
Optimization #3: Miscellaneous Techniques
Compiler Limitations
Modern compilers are very powerful, but there are still many typical cases they can't optimize away.
1. Allocation in Combinators
Code like this:
rust
// ❌ Bad: allocates every time
foo.unwrap_or(String::from("empty"));
// ✅ Better: lazy evaluation
foo.unwrap_or_else(|| String::from("empty"));Using closures in combinators is recommended, but direct memory allocation might trigger a clippy warning (or_fun_call rule). Even if this branch isn't taken, you still pay the allocation cost.
Wrapping in a closure enables lazy evaluation, only allocating when needed.
GreptimeDB's code style guide specifically mentions this:
Prefer with_context() over context() when allocation is needed to construct an error.
2. Constant Hoisting
It's easy to assume the compiler would hoist "constant allocations" out of loops, or expand iterators into for loops, but in practice this isn't always the case.
DataFusion#12305 is an example: moving a format! call out of an iterator significantly reduced end-to-end latency.
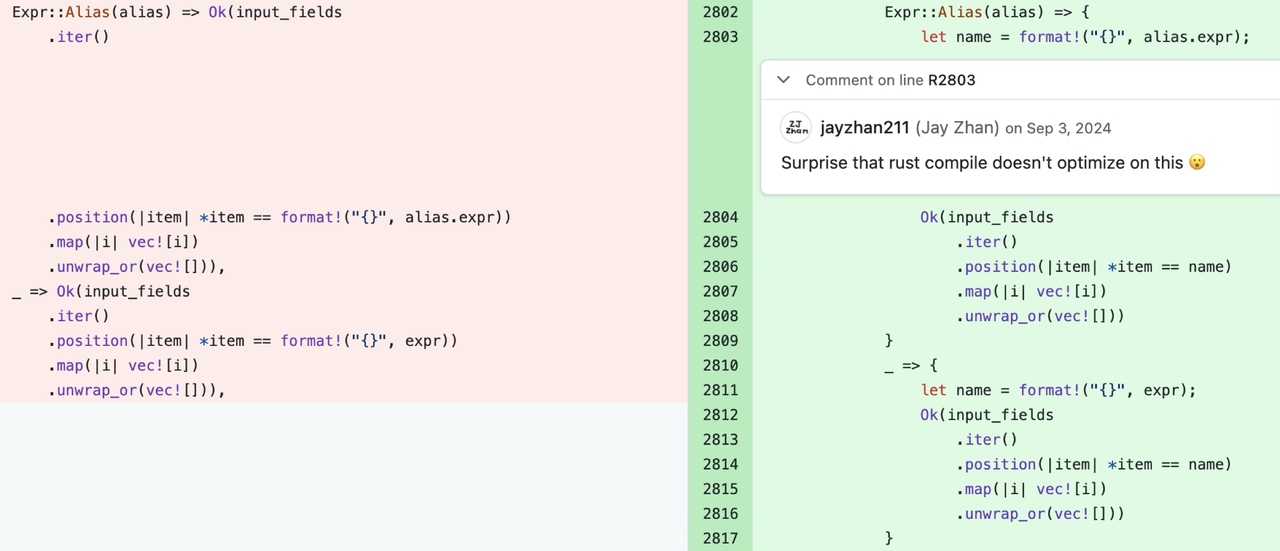
Reducing Memory Allocations
Beyond the scenarios mentioned above, we should minimize allocations everywhere possible.
3. Reusing Heap Objects
The most direct approach is to reuse structures. Rust doesn't have GC, and everyone usually thinks "no GC = good," but in practice you'll find: when a variable is constantly allocated and freed, you'll wish the language had built-in object pooling.
Rust doesn't have such mechanisms, so you have to do it yourself—reuse heap objects as much as possible.
For example (DataFusion#16878):

Previously, each call created a new String and returned it; changing to reuse the same String, passing it in and modifying in place. This simple change reduced latency by about 15% in microbenchmarks.
4. Lessons from prost
Another memorable example: prost, the Rust protobuf library.
Rust touts "zero-cost abstractions," but libraries don't necessarily achieve this. According to our tests, prost can be over 8x slower than Go's gogo/protobuf.
The reason is that prost, like the negative examples above, just directly news wherever needed, or directly generates String and Vector. Whatever you write in proto, it translates directly to Rust code without any optimization.
After discovering this issue, we made some optimizations (GreptimeDB#3425), and found that end-to-end system throughput improved by over 40% just from optimizing protocol serialization (modifying prost-generated code).
Editor's note: We have an excellent article about this optimization, recommended reading: Rust Decoding Protobuf Data 5x Slower Than Go? A Performance Tuning Journey
Beware the Cost of Syntactic Sugar
.collect(), .clone(), or .to_string() can be expensive.
Some examples:
- Speed up chr UDF (~4x faster) #14700
- Improve substr() performance by avoiding using owned string #13688
The usual patterns are:
- Previously might
collect()into aVectorfirst, then process - Or
to_string()at every step to work around lifetime issues
A slight change, like inserting data directly into the final container instead of creating intermediate variables first, can yield significant improvements in many scenarios.
Pre-allocating Capacity
Also, for containers like Vector, we can sometimes know in advance how large they'll be—output length can be derived from input length.
When reviewing code, I always take a second look at Vec::new() to see if it could be changed to Vec::with_capacity(). These changes are basically "free" performance improvements, and while they don't always help, as long as you don't go overboard, they rarely hurt.
I scanned DataFusion with ast-grep and found 271 instances of "directly create Vector then push" patterns:
bash
~/repo/arrow-datafusion on main *13 !2 ?10
> ast-grep scan -r unsized-vec.yml --report-style short | wc -l
271Among these 271 places, many are low-hanging fruit that can directly bring performance improvements. Try similar scans in your own projects.
The Importance of Benchmarking
After discussing all these optimization techniques, don't forget the most important point: performance must be measured.
Benchmarking is ultimately a numbers game, but it has many benefits:
- Quantified understanding: You know how fast your program can run in what scenarios, giving you confidence
- Effective communication: Concrete numbers to discuss with others. Is this an optimization? By how much? Numbers make it quantifiable
- Continuous momentum: Without numbers, you might not even know if you're doing the right thing, and overall optimization pace slows down
Benchmarks should also be "easy to run." If the barrier is lowered, newcomers who just joined the project and don't know what to do can run benchmarks first and might discover new optimization opportunities. You can also conveniently regression-test for performance degradation.
DataFusion's Benchmarks
DataFusion has two types of ready-made benchmarks:
- Micro-benchmarks: Using criterion, targeting specific functions or modules
- End-to-end tests: Including ClickBench, TPC-H, etc.
These benchmarks come with wrapper scripts:
bash
# Create data
./benchmarks/bench.sh data
# Run TPCH benchmark
./benchmarks/bench.sh run tpch
# Compare two branches
git checkout mybranch
./benchmarks/bench.sh run tpch
./bench.sh compare main mybranchOne-click execution, including data generation, specifying cases, and comparing results. Welcome to try them out—you might discover new optimization opportunities.
Beyond Fundamental Optimization
Finally, let me emphasize: fundamental optimization should be the second step. The first step, or at any time really, should be to consider "does this even need to be done here?" Only then should you ask "if it needs to be done, how can it be done faster?"
As the saying goes, "premature optimization is the root of all evil." Finding a shorter path is always better than studying how to walk faster (of course, I'm not discussing health here).
Optimization Comes with Constraints
Another point to emphasize: most of the time, optimization = adding constraints.
More constraints might mean better performance (like all the specializations above). But the cost is:
- More constraints mean greater cognitive burden—more things to remember
- Much code that could previously be written might no longer be possible
In terms of developer experience, I think one of the most painful things is Arrow's type system. Before encountering these, I rarely used downcast, but after, I write downcast every day.
I scanned DataFusion and found about 500+ downcast locations:
bash
~/repo/arrow-datafusion on main *13 !2 ?10
> rg ".downcast_ref::" | wc -l
539As a statically typed language, when I first saw this I thought: how did it come to this?
More constraints also bring more tribal knowledge. For example, two APIs can do the same thing, but one is faster than the other because it has additional optimizations. This kind of "tribal knowledge" is hard to spread and maintain.
Here are two DataFusion examples:
- Optimize iszero function (3-5x faster) #12881
- Speed up struct and named_struct using invoke_with_args #14276
Just switching APIs without changing logic can bring huge improvements. But this knowledge requires familiarity with the codebase to master.
Summary
Today I shared some fundamental optimization techniques practiced in DataFusion and GreptimeDB:
Strategic
HashMapUsageHashMapitself is an optimization- Consider replacing implementations (like
ahashmap) - Deep customization based on
HashTablewhen necessary
Code Specialization
- ASCII string optimizations
- Specific timezone optimizations
- Data range optimizations
- But don't over-specialize
Miscellaneous Techniques
- Pay attention to lazy evaluation in closures
- Reuse heap objects
- Reduce unnecessary allocations
- Pre-allocate container capacity
Benchmark-Driven
- Let numbers speak
- Make benchmarks easy to run
- Continuously monitor performance
Higher-Level Perspective
- Optimize the logic before you optimize performance
- Optimization equals constraints, balance is needed
These are all "fundamental" things—not because they're simple, but because they have broad applicability, clear benefits, and controllable risks. While pursuing high performance, we should also consider code maintainability and developer experience.
Thank you! If you're interested in DataFusion or performance optimization, feel free to join community discussions.
Related Links
- Apache DataFusion: https://github.com/apache/datafusion
- GreptimeDB: https://github.com/GreptimeTeam/greptimedb
- All PRs and Issues mentioned in this article are linked inline
Note: This article is based on a presentation at Apache CoC Asia 2025.




