
On this page
This isn't a victory lap. It's a checkpoint — why we started, how we chose, what we missed, and why we're still here.
On the evening of November 15, 2022, we sat in the office waiting for that GitHub repo — the one we'd spent six months building — to flip from private to public. When I clicked the button, I got so excited I forgot my GitHub password. Xiaodan, our CEO, recorded a video and joked that this was a future $500 million company. That was the whole ceremony. We laughed, went back to our desks, and kept writing code.
Four years later, GreptimeDB has gone from a startup idea for a time-series database to v1.0. Milestones, features, and community metrics matter. But looking back, what's really worth revisiting are the choices themselves: which ones turned out right, and which costs we didn't see coming.
I'm Jeremy Feng, co-founder of GreptimeDB and the engineering lead for the database kernel. Xiaodan has written before about the founding story and the business-side lessons. This post covers the last four years from the technical side: the decisions we made, the mistakes we own, how the community grew piece by piece, and how I actually feel about all of it.
I. Why this problem
When we decided to build GreptimeDB in 2022, the time-series database space was already well-established. InfluxDB, TimescaleDB, and TDengine all had significant user bases. We weren't blind to the competition — we just saw problems we believed still weren't solved well. That belief came from building one ourselves.
For four years before starting the company, most of our team had been building a proprietary time-series database at a major tech company. We put together an end-to-end observability data processing system: collecting metrics, modeling entities and relationships, combining large-scale data mining with expert knowledge and ML-based algorithms (what people now call AIOps) to build a real-time observability data mart. It powered anomaly detection, availability monitoring, alerting, and root cause analysis — and worked remarkably well. Later it expanded to container auto-scaling, site-wide performance diagnostics, and more. At peak, the system handled over 100 million data points per second in writes.
Even a system proven at that scale had a ceiling.
Storage costs were exploding. Trillions of new data points per day on top of historical data meant ever-growing bills that only got worse with business growth. Real-time analysis was painful — time-series data is inherently high-cardinality, and the architecture couldn't keep up with fast, accurate, or ML-powered queries. Every time the data science team ran a batch pull, we braced for impact. And the data model was too narrow: it could only store metrics. Logs and traces had no place in it, so observability data was fragmented across separate systems.
We looked at alternatives on the market. None solved all three problems. The "ideal product" had been living in our heads for a long time, but we'd never had the bandwidth to build it. Until one day, Xiaodan casually said over coffee, "Let's go start a company and build this." That was all it took.
Why open source? If you're building infrastructure software, users need to inspect your code before they'll trust you. That's the most fundamental reason. Most of us grew up in the open-source community, and we wanted to give back what we'd gained over the years. So from day one, we coded as if the repo were already public: code style, commit messages, branch management, PR conventions — all built up gradually from the very first line of code. The long-term payoff turned out larger than we expected.
Our understanding of open source was pretty shallow at the time, though. We thought it meant "put code on GitHub, slap on Apache 2.0, write a decent README." The biggest shift over four years: open source is a way of working, not just a way of publishing. Design docs need to spell out trade-offs. PRs need to be written as if the reader has zero context. Issue responses can't be hit-or-miss. Open source means tidying the house so that strangers can walk in, make sense of things, and stay.
Open source doesn't equal community, either. Stars don't mean users. Users don't mean trust. A database earns production trust through years of stability, a responsible release cadence, and how fast you show up when something breaks.
II. A few decisions that changed everything
Over four years we made countless decisions, but only a handful truly changed the trajectory. This section skips the timeline and focuses on the moments where choosing differently would have led to a completely different outcome.
Decision 1: Choosing Rust

Picking Rust for a database in 2022 was a minority choice. For us there was almost no debate — the team had been writing Rust for nearly four years, so experience wasn't a concern. More importantly, a database demands precise memory control, complex concurrency management, and stable latency under high throughput. That points squarely at a systems language with no GC and predictable performance. Go and Java's GC works fine for most scenarios, but at the storage engine level, a single GC pause can mean a latency spike. That was unacceptable. Rust's ownership model inherently guarantees memory and thread safety, and zero-cost abstractions mean we don't have to choose between clean design and raw performance.
Four years later, the benefits have been even larger than expected, but so were the barrier to entry and ongoing costs.
The good: Rust eliminated entire classes of concurrency and memory bugs. Our CI almost never produces a segfault — hard to imagine in a C++ database project. An unexpected bonus was community appeal. Rust developers are naturally drawn to infrastructure projects, and contributors who showed up often went beyond typo fixes to working on the engine itself.
The hard: hiring. The Rust talent pool is an order of magnitude smaller than Java or Go, and the intersection of "knows databases" and "knows Rust" is smaller still. Every new team member needed patience and ramp-up time. Compile times and disk usage — let's not go there.
Then in 2025, Rust gave us a gift we never anticipated: it may be the best language for vibe coding. AI writes plenty of buggy Rust, but the compiler catches errors precisely and kicks them right back, creating a tight generate-error-fix loop. In other languages, AI-generated code can "look right" while bugs hide in runtime corners. If Rust code compiles, a whole category of memory and concurrency errors is already gone. We had no idea this dividend was coming when we made the choice.
If we had to do it over, we'd pick Rust again. The early phase is harder, but over a longer timeline, worth it.
Decision 2: Rewriting the storage engine
The storage engine before v0.3 was more of a "get the system running" first-generation implementation. The memtable was essentially row-oriented data stuffed into a BTreeMap, with each region maintaining its own write state. It helped us sketch out the product quickly, but it wasn't friendly to time-series workloads. The defining trait of time-series data is that the same timeline gets written to repeatedly, with mostly unchanged tags. Stuffing that into a row-oriented BTreeMap meant keys and tags were duplicated again and again, inflating memory. Flushed SSTs were undersized, dragging down queries and compaction. The write path had similar problems: each region wrote independently, with scattered locks and state, making efficient batching nearly impossible.
From v0.1 to v0.3, benchmarks and profiling kept confirming the same thing. The bottleneck wasn't in any particular function — it was in how data was organized. Patching the old architecture could only yield incremental gains, not order-of-magnitude improvements. Waiting longer meant piling on more technical debt.
So at v0.4 we did a full rewrite: Mito2. The memtable switched to a timeline-organized Series structure, compaction adopted Cassandra-inspired TWCS, and storage moved to columnar. A ground-up rebuild. For an open-source project, this is especially painful. Users were already running the old engine; contributors were submitting PRs against it. The rewrite wasn't just a code problem — we had to explain on GitHub why we were rewriting, what the new design looked like, and how migration would work, all while maintaining the old engine in parallel.
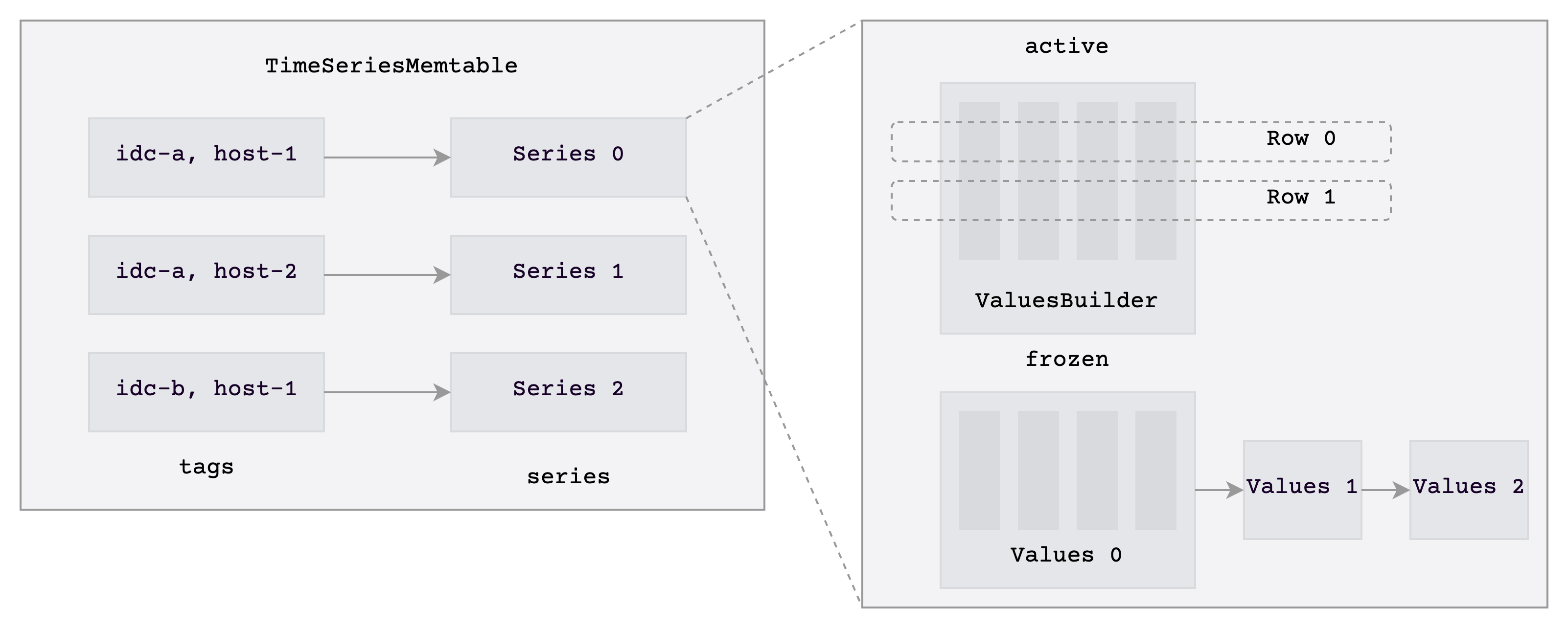
After Mito2 shipped, results were clear: consistent write throughput gains, scan queries several times faster, some scenarios over 10x, and even bigger improvements in memtable efficiency and memory usage. Behind those numbers were months of high-pressure development. The hardest part wasn't the engine itself — it was the blast radius. The new engine forced changes to the distributed communication protocol and scheduling architecture. And the real anxiety: after investing this much, would we get the expected results? No one could guarantee it, but someone had to make the call.
The storage engine kept evolving through v1.0. As more users put high-cardinality columns (like request IDs) into primary keys, we hit a new bottleneck: the old primary_key format maintained separate structures per timeline, so once timelines multiplied, memory efficiency and query performance degraded badly. One user's table had to process over 14 million timelines per flush — writes were essentially unusable. For v1.0, we introduced the Flat format, which adds independent storage for tag columns and pairs with the new BulkMemtable to eliminate per-timeline buffer maintenance. At 2 million timelines, write throughput improved over 4x; some queries dropped from 17 seconds to 3. The change looks like a storage format optimization, but the judgment is the same as Mito2: when the bottleneck is at the data organization layer, incremental fixes can't deliver fundamental improvement.
Looking back, the rewrite taught me one thing: "when to rewrite" matters more than "whether to rewrite." Too early, and you haven't understood your users' patterns. Too late, and tech debt drags you under. We chose v0.4 because the first three versions had accumulated enough real feedback and performance data. Had we started at v0.1, we'd most likely have built another engine that looked good but didn't solve real problems.
Decision 3: Unifying the metrics/logs/traces data model
In retrospect, it's tempting to frame this as a grand vision designed from day one. That's not what happened.
Our starting point was metrics. The team had deep experience, the pain was real, and the Prometheus ecosystem was mature — getting metrics right first was the most pragmatic choice. But from previous work, we'd suffered the cost of three siloed systems: when something went wrong, users didn't just look at metric curves. They asked about the logs from that moment, the trace for that call, which layer was the root cause. Three types of data scattered across different systems, with misaligned label schemas, data that existed but couldn't be correlated. So even starting with metrics, one question kept nagging: could we stop forcing users to jump between three separate systems?
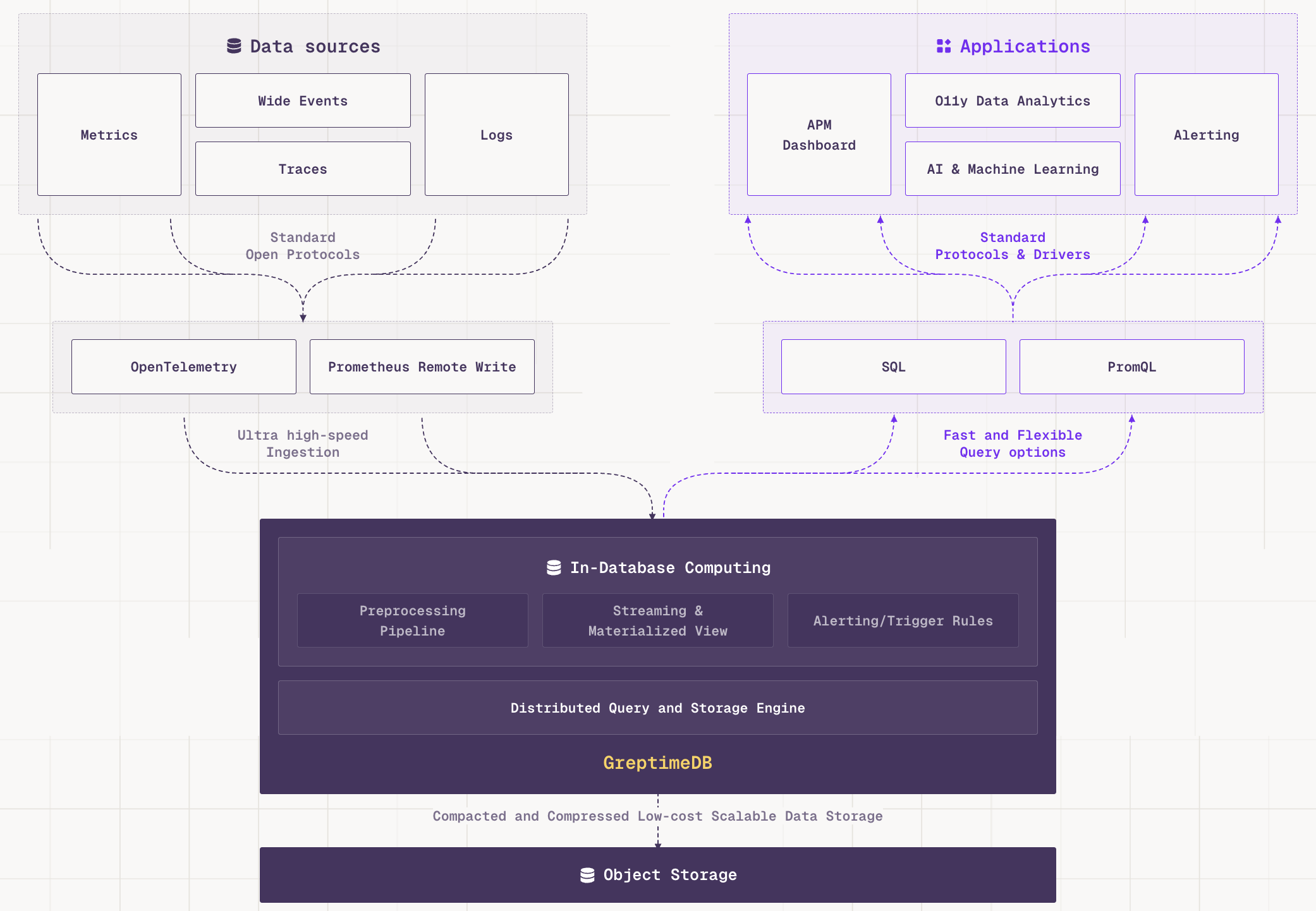
What gradually brought this direction into focus was a growing discomfort during product development: we kept hitting scenarios where metrics alone couldn't explain what was happening. We needed to cross-reference logs and traces, but could only stitch data together manually outside the system. Over time we realized that metrics, logs, and traces — despite looking different — are fundamentally timestamped, context-carrying events. They differ in payload and query patterns, but not in nature. They're less three separate data types and more different views of the same underlying observability data. The direction wasn't planned. Real problems pushed us there, one step at a time.
Building this out wasn't just a rebrand. We did it incrementally: first pushing the metrics model from Prometheus compatibility toward a more general table model, then bringing logs into a unified ingestion and query framework, and finally adding traces. Along the way, one thing became clear: what we're unifying is user mental models, data correlation patterns, and query entry points. The underlying layers can and should still be optimized per workload. Otherwise you don't get unification — you get a system that tries everything and does nothing well.
Today, our understanding has pushed further. Charity Majors at Honeycomb introduced the concept of Observability 2.0: the traditional "three pillars" operating in silos is 1.0; building around "wide events" as the core, deriving metrics/logs/traces from a single source of raw data, is 2.0. The unified data model we've been building is the database-layer foundation for 2.0.
The AI Agent era makes this even more urgent. Agent observability data is inherently high-cardinality, high-dimensional, and context-rich: a single Agent execution might carry dozens or hundreds of fields — prompt, response, tool calls, reasoning, memory state. Traditional approaches either stuff this into logs (losing structure) or into traces (too rigid a schema). The Hebo team built their AI Agent observability platform on GreptimeDB because unified storage plus native OTLP ingestion lets them query and analyze GenAI traces, token usage, and inference latency in one place. We've also published a working demo showing how to use GreptimeDB as a unified backend for GenAI traces, metrics, and conversations via OpenTelemetry GenAI semantic conventions. This has made us increasingly certain: what we're building is the database for Observability 2.0.
The unified data model is one of GreptimeDB's core bets. It wasn't planned from the start — and that's why it ended up closer to real needs. What we've always wanted to unify isn't three file formats or three protocols. It's the way users understand a single system's behavior. If the database layer keeps metrics, logs, and traces siloed, users end up doing the "unification" themselves outside the system. We'd rather do it for them.
III. Mistakes: some detours can't be summarized in one sentence
If this post only covered what we got right, it would read like a press release. The valuable part is being specific about where our judgment was wrong.
Building things users didn't actually need
The most telling example is the Python coprocessor. From an engineer's perspective, the direction was exciting: a database that executes user-defined logic right next to the data would be flexible and open up possibilities. We'd seen analysis scenarios that seemed like natural fits. The decision wasn't about showing off — we genuinely believed programmability might become a key requirement.
But we gradually realized that at that stage, users didn't care about writing Python inside the database. They cared about more basic things: ease of integration with existing systems, protocol compatibility, query stability, predictable performance, clear documentation, responsive support when things break. We'd invested effort in a direction that was genuinely valuable but wrongly prioritized.
This taught me that the most common mistake a technical lead makes is building things too early that would "look great if they worked." The Python coprocessor wasn't a bad idea — it just shouldn't have ranked above usability, compatibility, and stability.
Underestimating how hard community building is
Community doesn't just happen because you open-sourced the repo. We learned this the hard way.
Early on, our understanding was naive. We assumed that if the product direction was right, the code quality was high, and the repo was clean, community would naturally grow. What we missed was fundamental: for external contributors, the first impression isn't your architecture's elegance. It's whether someone responds to issues, whether docs make sense, and whether a first PR gets stuck on unwritten rules. We weren't deliberately unfriendly — but for a long time, we hadn't treated "how to let strangers participate" as a design problem.
The gaps were concrete: inconsistent issue responses, contributor guides written too late, feedback on external PRs sometimes too slow. Context that felt obvious internally was completely absent for outsiders. Database projects have inherently high contribution barriers. Many so-called Good First Issues weren't very "first" at all — what looked like a small code change actually required understanding an execution flow, two abstraction boundaries, and background knowledge just to get started. We eventually put real effort into lowering the bar: contributor guides, architecture walkthrough videos, real-time Q&A on Slack's #contributors channel. But these were built up gradually, not there from the start.
Technical debt and architectural costs
If I had to name the most expensive category of technical debt, it would be boundaries we didn't draw clearly enough in the rush to get the system running.
This is common in early-stage startups, and often the right trade-off. You can't perfectly define abstraction boundaries between the standalone engine, distributed protocols, scheduling, and storage formats in v0.1. Getting the system running and into users' hands matters more.
But once boundaries aren't managed early, they amplify the blast radius of every subsequent change. The "pull one thread and the whole thing shifts" feeling during the storage engine rewrite was largely interest on this kind of debt. What looked like an internal engine evolution ended up requiring changes to the distributed protocol and scheduling architecture. These costs are invisible early on — when the system is small, the core team's contextual memory papers over the gaps. As the product evolves and the team grows, those "deal with it later" spots become debt that demands real investment to repay. We knew they'd need attention. We just underestimated how fast the costs would compound.
IV. What the community gave us — beyond numbers
The GitHub numbers look good: 6,100+ stars, 5,200+ commits, 226 releases. But what makes open source feel meaningful to me has never been the numbers. It's specific people and specific moments.

A contributor story that stuck with me
One contributor who left a deep impression is Lanqing (lyang24 on GitHub). His trajectory shows what separates "passing through" from "actually staying" in an open-source database project.
He started with a 2023 PR (#2765) improving the compression type UX — a typical peripheral contribution, solving a small concrete problem. He didn't stop there. His work gradually went deeper: from the metadata service's KvBackend, to system tables and Postgres protocol adaptation, to Mito engine observability and performance closer to the kernel. Step by step, he ground through the context until he'd entered the system's internals. In 2025, he became a committer.
What struck me wasn't "we gained another committer." It was watching someone who started with a casual PR slowly become an important part of the project through successive issues and small contributions.
What users taught us: enter their world first
One user story has stayed with me. In 2024, DeepXplore publicly documented their migration from Thanos to GreptimeDB. What resonated wasn't "they thought we were faster" — it was the rationale: they didn't want to keep spending time maintaining a complex long-term storage system. They wanted to redirect energy to their own product. For a startup team, that reasoning is deeply relatable. What users compare is always which approach requires less hassle and lets them focus on what they actually care about.
The migration was viable precisely because it didn't require a rewrite. They switched the remote write URL in Grafana Alloy to GreptimeDB; the PromQL query side needed almost no adjustment — just a different endpoint. This reinforced what we'd been learning: users want something that plugs into their existing stack with minimal disruption.
This kind of feedback doesn't just change a feature. It changes how we see the product. Users don't live in our architecture diagrams. They live in their own production environments. You have to enter that environment first. Everything else follows.
V. On v1.0
As I write this, GreptimeDB v1.0 is in RC. For us, v1.0 isn't the finish line — it's where we start holding ourselves to the standard of long-term responsibility.
It means some core bets have been validated: unifying metrics/logs/traces works, and the product must fit into existing ecosystems rather than demanding users rewrite their pipelines. These were convictions early on. By v1.0, enough users, use cases, and engineering experience have confirmed the path works. Core capabilities have moved from "it runs" to "you can depend on it" — when something breaks, we know how to diagnose, fix, and keep evolving.
v1.0 isn't the end. Architecture will keep evolving, the product definition won't be locked down, and community building is far from finished. Before v1.0, we were mostly validating whether this path was viable. After, the focus shifts to making it work well long-term and being accountable to users.
VI. What four years taught us
Four years in, what's clearer isn't just what to do next — it's which things are worth sustained investment over many years.
All the decisions and lessons above converge on one question: making a choice isn't the hard part. The hard part is whether the team keeps pushing forward before the choice has been proven right.
During the engine rewrite, no one could guarantee the outcome. The unified data model was, for a long time, just a belief the market hadn't fully validated. These things worked out — not because we had everything figured out, but because at critical junctures where the path was uncertain, we didn't stop. In infrastructure software, judgment matters. But what's often scarcer is patience.
Four years have left me with one conviction: what creates differentiation over time isn't who's smarter. It's who stays with a hard problem for years without switching topics. The people I consider fellow travelers aren't just those who agree with our technical direction — they're the ones willing to face complexity together, accepting that this work simply takes time.
VII. Thank you — and an invitation
Thank you to everyone who's filed an issue, submitted a PR, or asked a question in Slack. Thank you to the early users — those who tried and pointed out problems when the project was still rough.
You might think it was just a small bug report or an inconsequential docs fix. For us, every interaction was a signal: someone is using this. Someone cares.
If you're interested in where observability data is heading, or you're drawn to work that isn't flashy short-term but matters long-term, come take a look:
- GitHub: https://github.com/GreptimeTeam/greptimedb
- Contributor Guide: https://docs.greptime.com/contributor-guide/overview
- Slack: https://greptime.com/slack
- 2026 Roadmap: https://github.com/GreptimeTeam/greptimedb/issues/7685
Whether you're a user, contributor, peer, or hearing about us for the first time — we'd love to connect. Four years isn't long for an infrastructure project. Not long enough for everything to settle. But long enough for some bets to be validated, and some relationships to take root.




