On this page

We are thrilled to announce the release of our latest version, GreptimeDB v0.3, the fruit of our unwavering hard work and dedication! In our previous version, v0.2, we primarily aimed to ensure standalone functionality, enhance compatibility with PromQL, and optimize write performance, among other features.
Building on our standalone v0.2 version, in the latest v0.3 version, we've shifted our focus towards distributed capabilities. This means all performance improvement and function updates are targeted towards the distributed version, offering qualities that the standalone version does not possess, such as scalability, high availability, and fault tolerance.
To summarize, the core enhancements of this release are as follows:
- Distributed performance optimization: support Region-level high availability, and provide fast fault-tolerant switchover scheduling. The distributed write performance is also optimized.
- Query capability enhancement: support for distributed query optimization, improvement of important SQL queries (e.g. TopK) and optimization of data compaction strategy to boost query speed.
- Stability improvement: to increase the robustness and reliability of the system, the Procedure framework is introduced to guarantee the eventual consistency of multi-step operations. A finer-grained Hybrid-flush strategy is also provided to improve write stability, and more buried performance metrics are added to improve system observability, supporting tools such as the Tokio console.
In just a month and a half, from v0.2 to v0.3, GreptimeDB has made significant strides. We have successfully merged 222 Pull Requests, implemented changes across 674 files, carried out 120+ feature optimizations, rectified 50+ issues, and performed 20+ refactorings.
These substantial achievements are a testament to the diligent work of our 27 community contributors. We owe a special debt of gratitude to our community and team for their unwavering commitment.
Now, let's delve into the core enhancements introduced in GreptimeDB v0.3.
Highlights of GreptimeDB v0.3
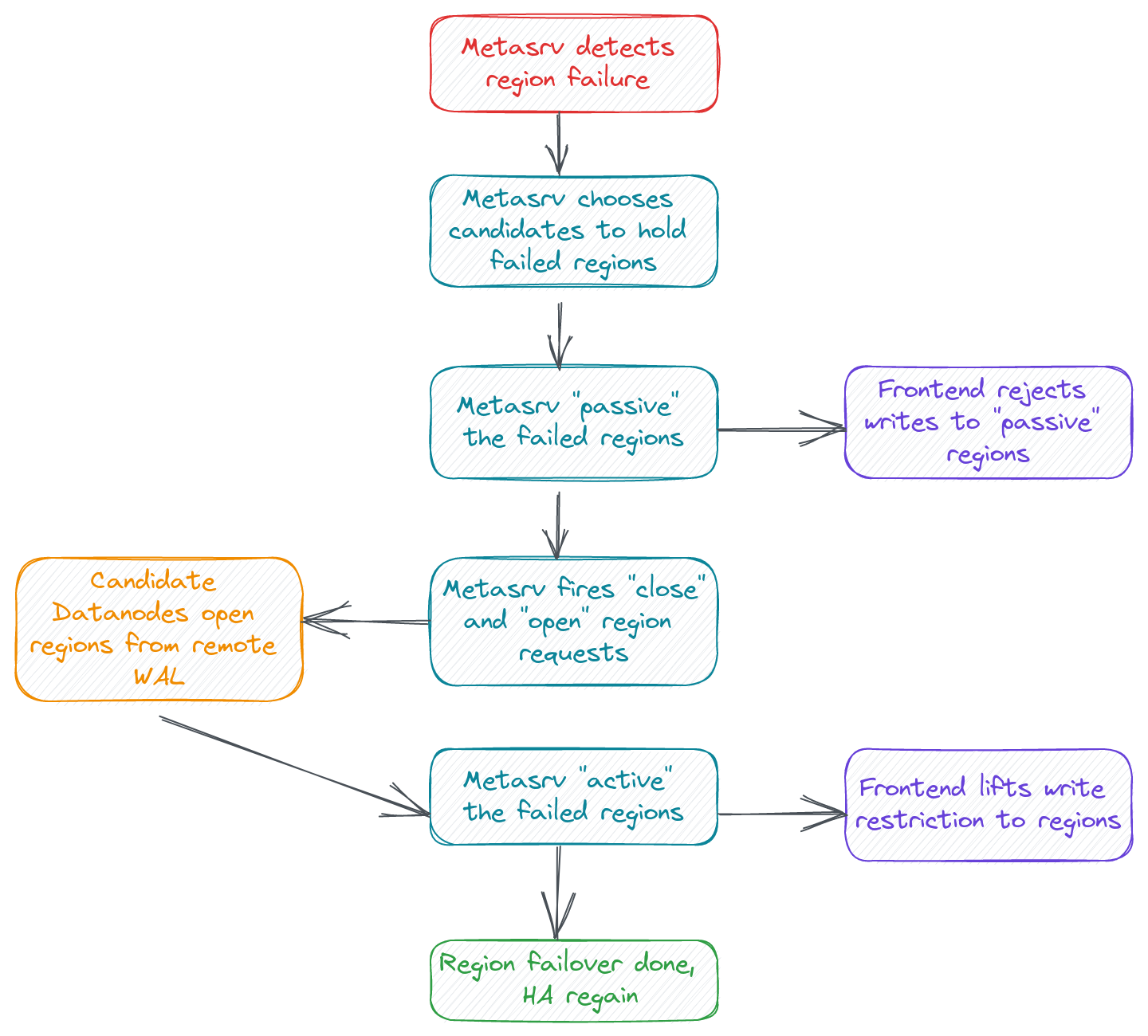
Region-level High Availability
GreptimeDB supports Region-level fault-tolerance in v0.3, which is an important milestone to finally achieve distributed high availability. As it involves different components such as Frontend, Meta and Datanode, we track the whole implementation process via Issue# 1126. If you are interested in this, you're welcome to contribute. Everything starts from RFC: Region Fault Tolerance.
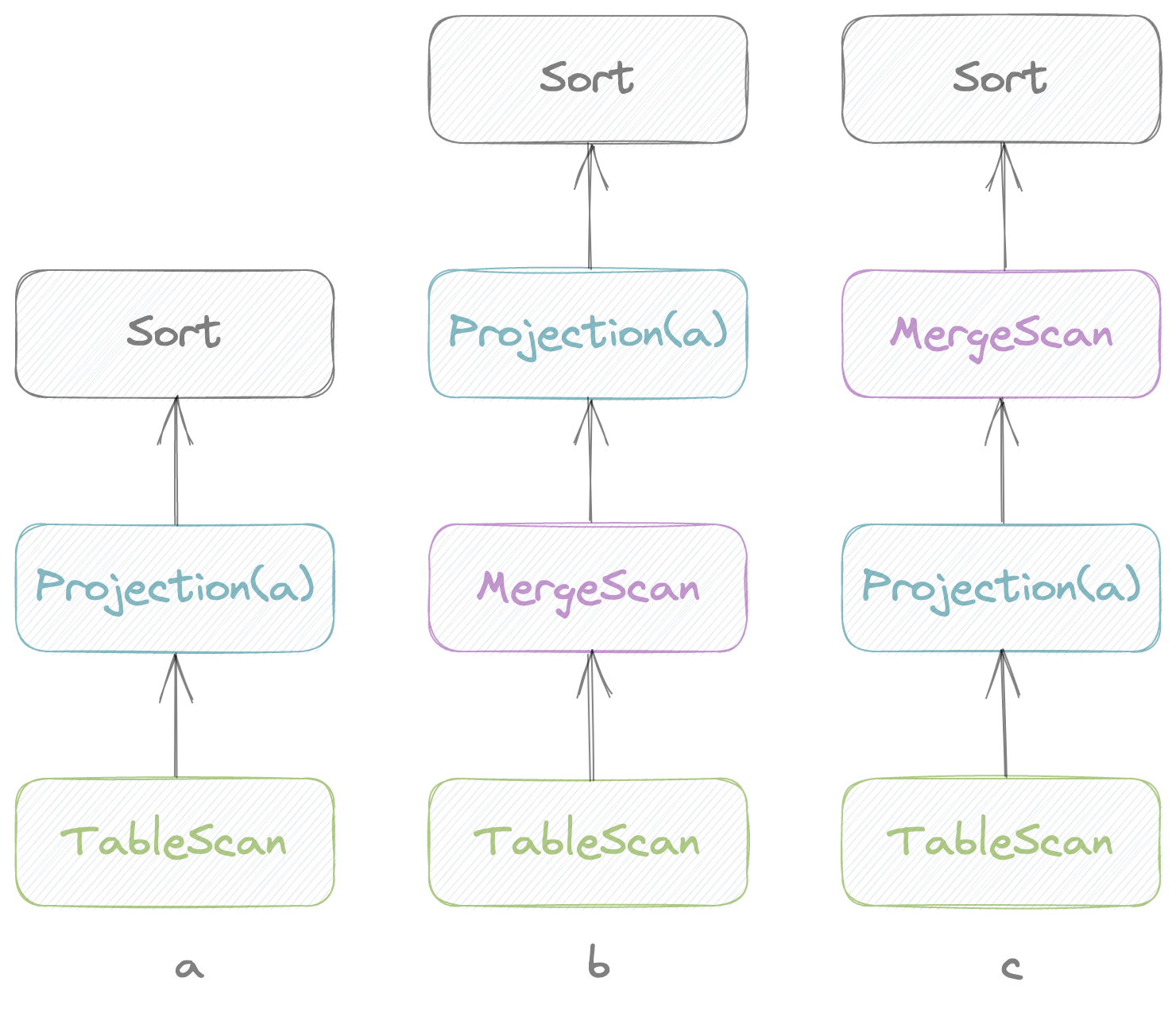
Optimization of important SQL query scenarios
Based on our past business experience, we emphasized optimizing the most common query scenarios in GreptimeDB v0.3, such as TopK, etc. Using the pruning strategy, we divided the whole work into multiple subtasks, and tracked them through Issue#1286.
Distributed query optimization
To improve the performance of database analysis capabilities, near data processing (NDP) is the alternative, which refers to augmenting the memory or the storage with processing power so that it can process the data stored therein. This approach mitigates the need to transfer large volumes of raw data, thereby improving efficiency. Operator push-down is the most common method of implementation.
GreptimeDB v0.3 supports pushdown of most PromQL operators and predicates to optimize distributed queries. Such an important feature is also discussed in advance in RFC: Distributed Planner, the detailed implementation strategy can be found in PR#1660.
Greptime's internal team protocols: we typically discourage PRs involving more than 1000 lines of code changes. However, the author of this particular PR has generously offered to treat the team to coffee, prompting us to make an exception. 😃
Introduce the Procedure framework
To increase the robustness and reliability of the system, inspired by Apache HBase's ProcedureV2 framework, GreptimeDB has also written a Procedure framework in Rust to guarantee the ultimate consistency of multi-step operations. This is another example from RFC: Procedure Framework with a super huge Issue#286 on the track. v0.3 is not the end of the story, we'll continue to improve the performance. (If reading through RFC is too boring for you, you can also refer to this article to understand what exactly Procedure is.)
Add more performance metrics
As a reliable storage solution under the Observability system, the observability of GreptimeDB itself must be done well. In v0.3, more metric indicators have been added to check the operation of the system, which can be found in every component, see PR list
Other minor optimizations:
- Support querying external data, importing and exporting files in the format of CSV/JSON/Parquet
- Support for
TQL EXPLAIN/TQL ANALYZEclauses to analyze PromQL query performance - Improve PromQL compatibility
- Support for enabling Tokio console in cluster mode
- etc.
Overall, v0.3 represents our initial foray into a distributed version, featuring region-level service high availability (with high data reliability to be accomplished in upcoming versions), and distributed query capabilities for key scenarios (emphasizing on PromQL query compatibility). Additionally, its write performance either matches or slightly exceeds that of comparable mainstream databases.
Upgrade Note: If you're upgrading from version 0.2, please pay special attention to the following points:
- If you're using local storage, the configuration of
data_dirneeds to be modified, as this option has been deprecated. If you previously setdata_dir = "/greptimedb/data", you need to change this todata_home = "/greptimedb", wheredata_homenow specifies the root directory for data. - It is recommended to backup your data using the 'COPY' command before upgrading.
Plan for GreptimeDB v0.4
Starting from v0.3, we've shifted our development focus to distributed systems and have established a medium to long-term plan, iterating on a monthly basis. The main focus for v0.4 will be improving performance and refining existing features, with a specific focus on the following functionalities:
- Support distributed DDL statements like Create Table, Drop Table, etc. to be connected to the Procedure framework to ensure correct execution of distributed multi-step operations
- Asynchronous recompression and indexing to improve query performance
- In v0.3 we supported most operator-pushdown and predicate-pushdown of PromQL, v0.4 will focus on pushdown of common operators in SQL to improve SQL query performance
Acknowledgement
A heartfelt THANK YOU to all our community and contributors. Your valuable suggestions, bug fixes, and code contributions have consistently fortified and advanced this project.


























