Object Storage Economics for Time-Series Databases

Introduction
Observability data grows on a curve that block storage cannot keep up with. A medium-sized digital business or an IoT fleet routinely generates terabytes to petabytes of metrics, logs, and traces per day, and most of that data has to be retained for weeks or months for debugging and audit. Provision that on attached SSDs and the storage bill becomes the dominant line item; provision conservatively and queries hit a retention wall right when they are most needed.
The cost relief sits in object storage. Amazon S3, Google Cloud Storage, and Azure Blob are an order of magnitude cheaper than EBS-class block storage for the same gigabyte, and they scale without capacity planning. The catch is that object storage was designed for throughput, not latency, so naively layering a time-series database on top of S3 buys cost at the price of query performance.
This article walks through where the cost gap actually comes from, what a time-series database has to do internally to capture the gap without losing query speed, and what the numbers look like in production. The reference point throughout is GreptimeDB, whose storage architecture is object-storage-first by design.
The Storage Cost Curve: Block Storage vs Object Storage
Storage cost matters most when retention is long and data volume is high — exactly the workload profile of metrics, logs, and traces. The relevant comparison is hot tier to hot tier, not list price to list price.
Public AWS pricing as of writing:
| Tier | Service | Price per GB-month |
|---|---|---|
| Object storage, hot | S3 Standard | $0.023 |
| Object storage, cold | S3 Glacier Deep Archive | $0.00099 |
| Block storage, throughput HDD | EBS st1 | $0.045 |
| Block storage, general SSD | EBS gp3 | $0.08 |
| Block storage, performance SSD | EBS io2 | $0.125 |
S3 Standard is roughly 2× cheaper than the cheapest block tier (st1) and 3–5× cheaper than the SSDs most production observability databases actually run on. Push old data into S3 Glacier tiers and the gap widens by another order of magnitude. The same comparison holds on the other major clouds.
That headline ratio is only the start. Block storage volumes have to be provisioned to the maximum capacity any cluster might need, including headroom for spikes, replicas, and snapshots, and any unused capacity is paid for whether queries touch it or not. Object storage is pay-per-byte-stored, with no provisioning overhead and no replica multiplier on top of S3's built-in eleven nines of durability. The total cost gap in practice is therefore wider than the per-GB list price implies.
The flip side is latency. Object stores are designed for throughput, not low latency, with non-trivial per-request and API overhead. A naive engine that translates every query into S3 GetObject calls will be cheap on storage and unusable on query latency. The architecture has to compensate.
Compute-Storage Disaggregation: The Architectural Prerequisite
Object storage only pays off if the database is built around it. In monolithic time-series engines the storage layer is tightly coupled to compute nodes: data lives on local disks, scaling means moving data, and shrinking a cluster risks losing it. Object storage in that model is a backup target, not a primary store.
A disaggregated architecture inverts this. Compute nodes are stateless. The authoritative copy of the data lives in S3, GCS, or Azure Blob. Compute capacity scales horizontally without rebalancing data, and storage capacity scales independently to whatever the cloud provider supports.
GreptimeDB is built this way from the ground up. The architecture documentation describes the split: a frontend handles queries, datanodes hold the storage engine and write Parquet files to object storage, and a metasrv coordinates the cluster. Datanodes are stateless in the sense that data ownership can move between them without copying the underlying files; the files stay in S3 and the routing changes. Adding a node adds query and ingest capacity. Removing a node removes capacity, not data.
This is what makes the cost story credible. The product page for GreptimeDB OSS leads with "up to 50× cost reduction." That number compounds the object-storage price gap, columnar compression, and the absence of replica multiplication on storage. None of it works without disaggregation.
Compression: The Multiplier on Top
Storage tier is the base; compression is the multiplier.
Observability data compresses well. Metrics are mostly low-cardinality dimensions and numeric series. Logs and traces are repetitive structured records with shared field names. Columnar storage lays out values from the same column contiguously, which is where general-purpose compressors like zstd capture order-of-magnitude gains over row-oriented formats.
The numbers from published benchmarks:
- Logs vs Loki: a 2025 benchmark ingested 83 GB of raw NDJSON into both systems. GreptimeDB persisted 3.03 GB on disk (about 3% of the raw size); Loki persisted 6.59 GB (roughly 8%). Same dataset, 50% lower storage at parity ingestion throughput.
- Logs vs Elasticsearch: a log benchmark measured GreptimeDB at 12.7% of Elasticsearch's persistent storage footprint on the same dataset, while running on 408 MB of memory versus Elasticsearch's 9.9 GB at the same 20K rows/sec write rate.
- Metrics vs TimescaleDB: a TSBS benchmark measured GreptimeDB at 1.1 GB versus TimescaleDB's 20 GB on the same cpu-only dataset, roughly 1/18 the storage size.
Compression interacts with object storage in a useful way: smaller files mean fewer GET requests per query, lower egress costs, and faster cache fills. The compression ratio shows up everywhere downstream of the storage tier choice.
The Multi-Tier Cache: Hiding Object Storage Latency Without Paying for It
A cost story is incomplete if queries get slower. The architectural piece that closes the loop is a multi-tier cache between compute nodes and object storage.
GreptimeDB's storage architecture layers three caches:
- Write cache: a write-through cache on local disk that absorbs recent ingest. Data written to the WAL flushes through this cache before reaching S3, so the most recent hours of data answer queries from local disk without ever touching object storage.
- Read cache: an LRU-managed local-disk cache holding Parquet data pages for historical reads. Frequently scanned ranges stay hot; rarely scanned ranges spill to S3.
- Metadata and index caches: schema, file metadata, and index data live in memory and on disk, sized for fast lookup without object storage round-trips.
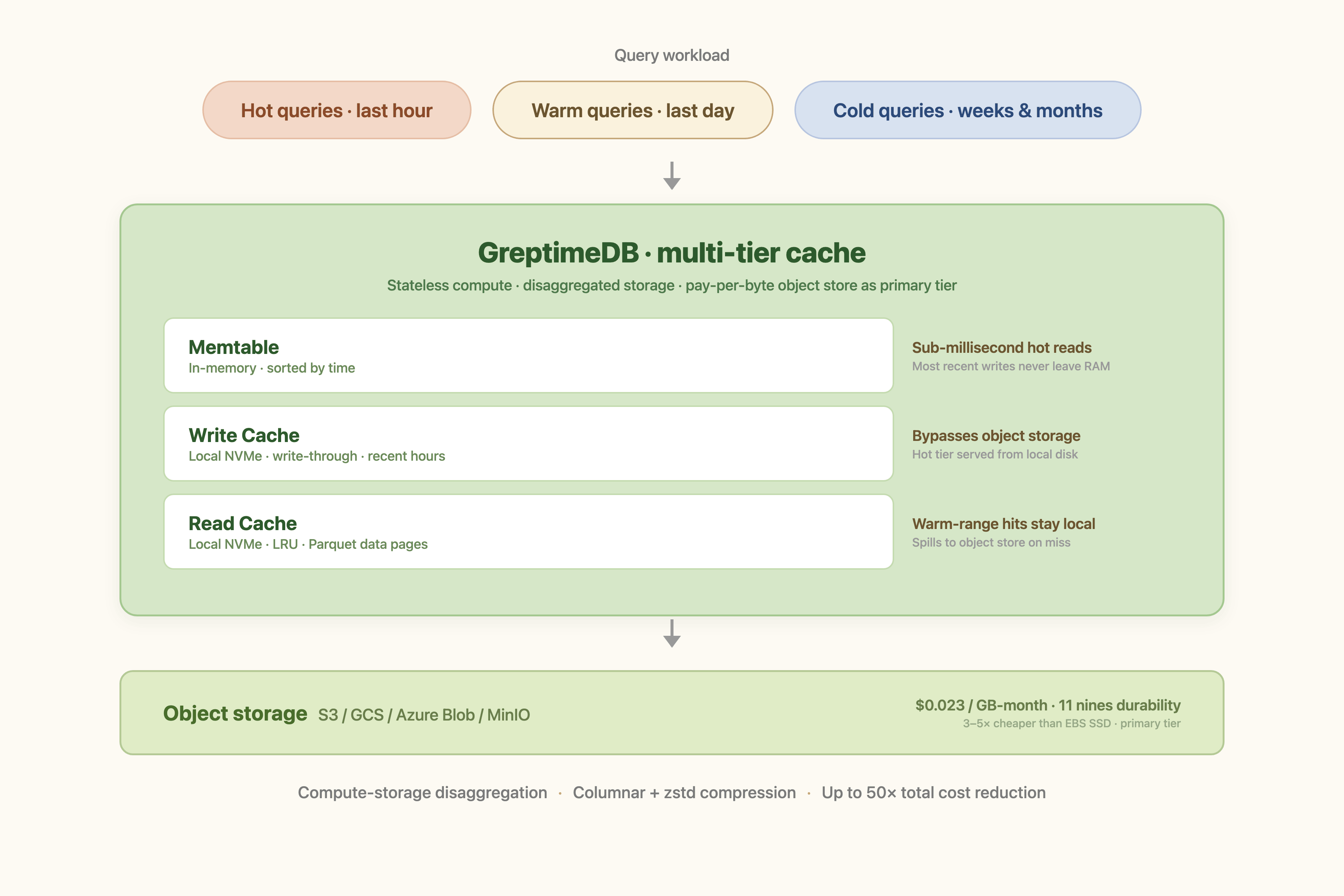
The behavioral effect: hot data queries run at memtable or local-disk speed, warm queries run at local-disk speed, and only true cold queries pay the S3 latency tax. The cache sizes are configurable per workload, so an operator can trade disk for hit rate without giving up the underlying object-storage economics.
This is the part most "S3-backed" claims miss. Putting Parquet files on S3 is the easy half. The hard half is making queries land on the right cache tier (write cache for the last hour, read cache for the last day, S3 for the rest), which is what keeps the system usable while the storage bill stays small.
Production Numbers: 300 TB at OceanBase Cloud
The clearest case study to date is OceanBase Cloud, which migrated its multi-cloud log platform off Grafana Loki onto GreptimeDB in 2024 and reported a year of production data in 2025.
Where it landed:
- Scale: 80+ GreptimeDB clusters in production, 300 TB of logs and SQL audit data under a 7-day retention, largest single cluster at 50 TB.
- Throughput: about 1 GB/s of sustained write traffic on average.
- Cost: overall log storage cost down by more than 60% compared to the Loki-based stack it replaced.
- Topology: a dedicated cluster in each of seven public clouds (Alibaba, Huawei, Tencent, Baidu, AWS, Azure, GCP), each backed by that cloud's native object storage.
The cost reduction breaks down predictably: object storage as the primary tier, columnar compression on top, full-text and skipping indexes that replaced Loki's brute-force scan, and a 95-percent-cold access pattern that's a textbook fit for cache-tiered object storage. OB Cloud passed more than 60% of the SQL audit savings through to its own end customers in lower pricing.
This is the data point that grounds the architectural argument. A 300 TB observability workload running on commodity object storage, with sub-second to single-second query latency on a full day of logs, is what the cost curve looks like when the database is built around it.
When Object Storage Doesn't Fit
Object-storage-first is not universal. A few legitimate exceptions:
- Sub-millisecond P99 latency: trading-floor metrics or HFT-adjacent workloads that need single-digit-millisecond query response on every query, including cold ones. The cache hits will be fine; the cache misses will not.
- Air-gapped or regulated deployments without an S3-compatible store: some on-premises environments have no object store available, in which case the deployment falls back to local disk with the corresponding cost profile. MinIO and Ceph cover most of these cases, but not all.
- Very small total volumes: under a few hundred GB, the cost gap is small enough that operational simplicity of a single local volume can outweigh the savings.
For everything else (observability, IoT, application metrics, log retention beyond a few days), the cost math points one direction.
Conclusion
The cost story for time-series databases now sits on three multiplicative factors: an object-storage tier that is 3–5× cheaper than block storage at list price, columnar compression that shrinks the on-disk footprint by another order of magnitude, and a multi-tier cache that protects query latency from the underlying object-storage round-trip. None of these are individually new. What changes the economics is having all three composed inside the database, with no manual tiering, no separate cache layer, and no replica-multiplier on storage.
If the time-series stack today is provisioned on EBS SSDs with metrics in one system, logs in another, and traces in a third, the immediate question is not which engine to swap in. It is whether the storage tier the data lives on still makes sense at the volume the workload has grown to. That is usually where the savings come from. The engine choice follows.
About Greptime
GreptimeDB is an open-source, cloud-native database purpose-built for real-time observability. Built in Rust and optimized for cloud-native environments, it provides unified storage and processing for metrics, logs, and traces, delivering sub-second insights from edge to cloud at any scale.
- GreptimeDB OSS: the open-source database for observability and IoT workloads, with compute-storage disaggregation and object storage as the primary tier.
- GreptimeDB Enterprise: adds operational features for production scale, including 5× bulk ingestion, auto-repartition, read replicas, LDAP/RBAC, management console, and 24/7 expert support.
Stay in the loop
Join our community
Get the latest updates and discuss with other users.




