On this page
The Role of Storage Architecture in Observability Databases
The design of a database’s storage architecture directly impacts its performance, operational cost, and data reliability. Recently, GreptimeDB demonstrated exceptional results in ClickHouse’s official JSONBench evaluation, ranking 1st in Cold Run and 4th in Hot Run.
This article provides an in-depth analysis of how GreptimeDB’s storage architecture optimizes read and write performance while achieving an optimal balance across multiple performance dimensions. Ultimately, these innovations enable a more efficient solution for managing observability data.
Storage Economics: Why Object Storage?
Observability data is inherently massive in scale. Discussions with numerous companies worldwide indicate that medium to large enterprises with digital business clusters, as well as IoT device manufacturers, generate daily volumes of metrics, logs, and trace data reaching TB (terabytes) to PB (petabytes), making efficient storage a critical challenge.
One of the core challenges for observability databases is how to store vast amounts of data cost-effectively. From its inception, GreptimeDB has prioritized storage cost efficiency as a key design principle.
Object Storage vs. Block Storage
Object storage systems (e.g., Amazon S3, Google Cloud Storage) are designed primarily for high throughput rather than low latency, yet they offer significant cost advantages:
- Compared to block storage solutions (e.g., Amazon EBS), object storage is typically 3-5 times cheaper.
- Object storage provides virtually unlimited scalability, making it well-suited for the continuous growth of monitoring and IoT data.
- Operational overhead is low, eliminating the need for complex capacity planning.
However, object storage’s inherent high-latency characteristics create a natural barrier to real-time query performance. Instead of making a binary choice between storage types, GreptimeDB’s architecture seamlessly integrates both approaches, maximizing their respective advantages.
For a detailed performance evaluation of object storage, see our colleague’s analysis: "Research Paper Sharing - Exploiting Cloud Object Storage for High-Performance Analytics".
Cost Comparison: Object Storage vs. Block Storage
Focusing purely on storage costs (excluding throughput, IOPS, and API call overhead): (1) Object Storage Pricing (Amazon S3)
- Amazon S3 Standard (for hot data): $0.023/GB/month
- Amazon S3 Glacier (for cold data): as low as $0.004/GB/month
(2)Block Storage Pricing (Amazon EBS)
- EBS General SSD (gp3): $0.08/GB/month
- EBS Throughput-Optimized HDD (st1): $0.045/GB/month
Relative Cost Differences
- Hot storage: Even compared to the cheapest EBS option (throughput-optimized HDD), S3 Standard is about 2x cheaper ($0.045 / $0.023).
- High-performance block storage: S3 Standard is 3-4x cheaper than general SSD (gp3).
- Cold storage: S3 Glacier can be up to 10x cheaper than block storage solutions.
Multi-Tiered Caching Architecture: Overcoming Latency Challenges
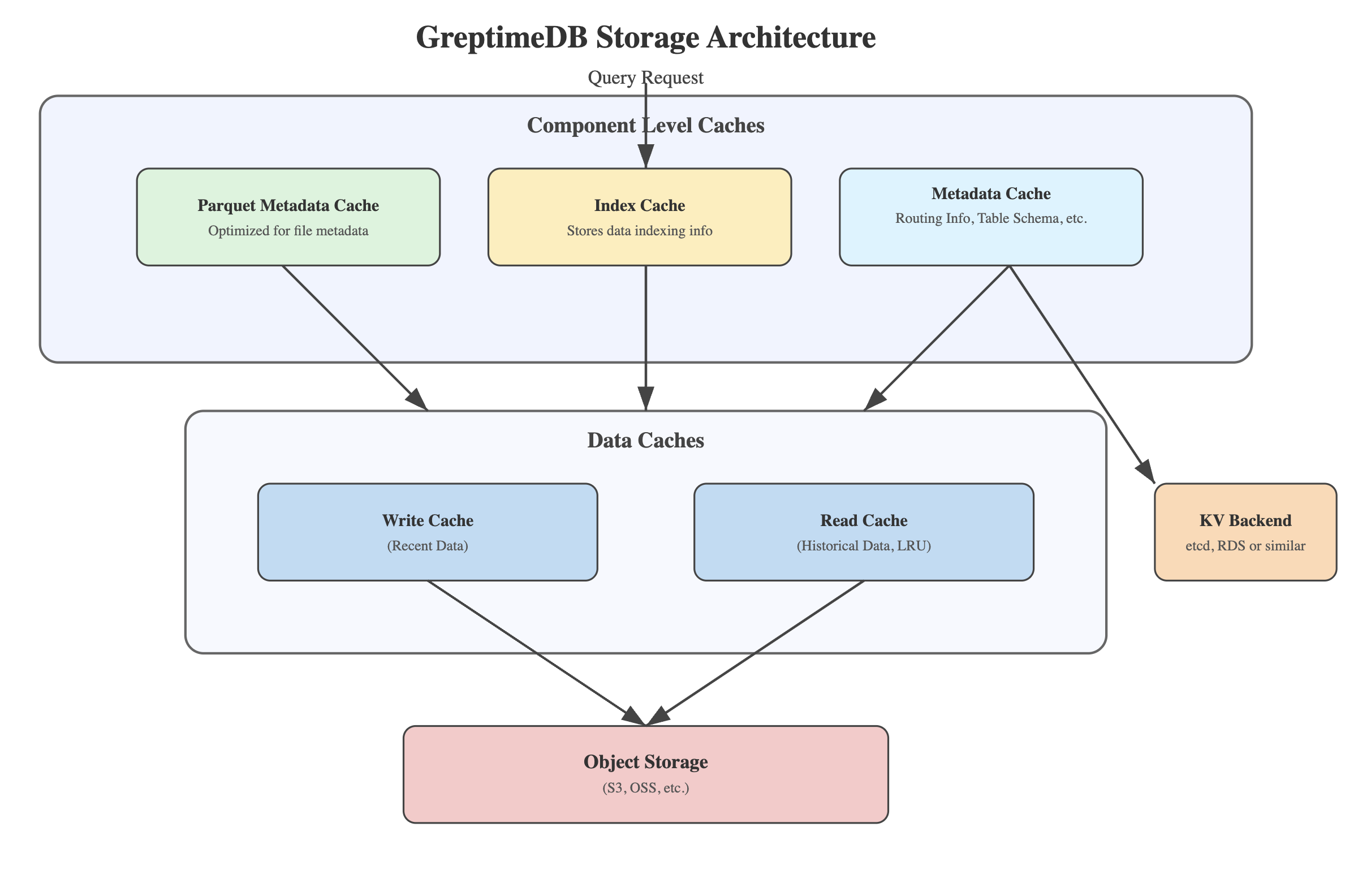
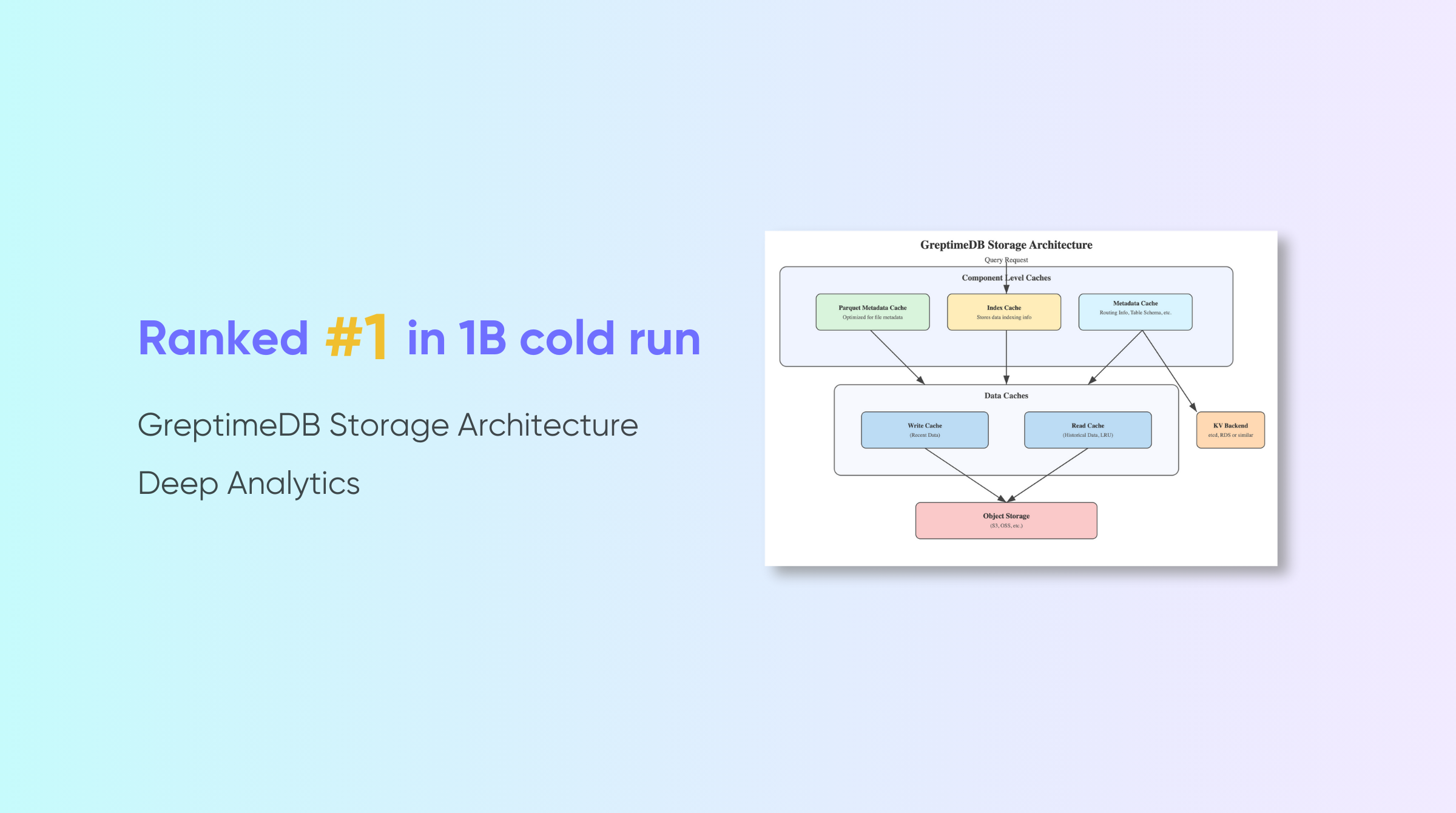
Inspired by OS (operating system) Page Cache, GreptimeDB employs a multi-tiered caching system that leverages object storage’s cost advantages while mitigating its latency issues.
Write Cache Design
The Write Cache is a critical component of this architecture, functioning as a write-through cache:
- Incoming data is first written to a disk-backed buffer known as the Write Cache.
- Data is organized by time, enabling fast access to recent data.
- The Write Cache size is configurable, typically storing the most recent hours or days of data. This approach ensures that frequently accessed recent data can be retrieved with low latency, bypassing object storage.
Read Cache for Historical Data
To optimize historical queries, GreptimeDB implements a dedicated read cache:
- Uses an LRU (Least Recently Used) eviction policy to manage cache contents.
- Backed by local disk storage, offering much faster access than object storage.
- Caches Parquet Data Pages, optimized for time-series query patterns.
Metadata & Index Caching
Beyond data caching, GreptimeDB optimizes metadata access through dedicated in-memory and disk-based caching:
- Table schema and distributed routing metadata.
- Parquet file metadata caching.
- Index data caching, ensuring full in-memory & disk indexing for faster lookups.
The metadata of the file is also obtained from object storage. Similar information, such as the schema of a table and shard routing, is stored in the KV Backend. It is a KV abstraction layer for metadata storage, which can be backed by etcd or cloud databases like RDS.
Optimized LSM Tree Architecture for Observability Data
GreptimeDB's core storage engine features a deeply optimized LSM (Log-Structured Merge Tree) architecture, specifically designed for the high-write intensity of observability data.
Data Ingestion Workflow
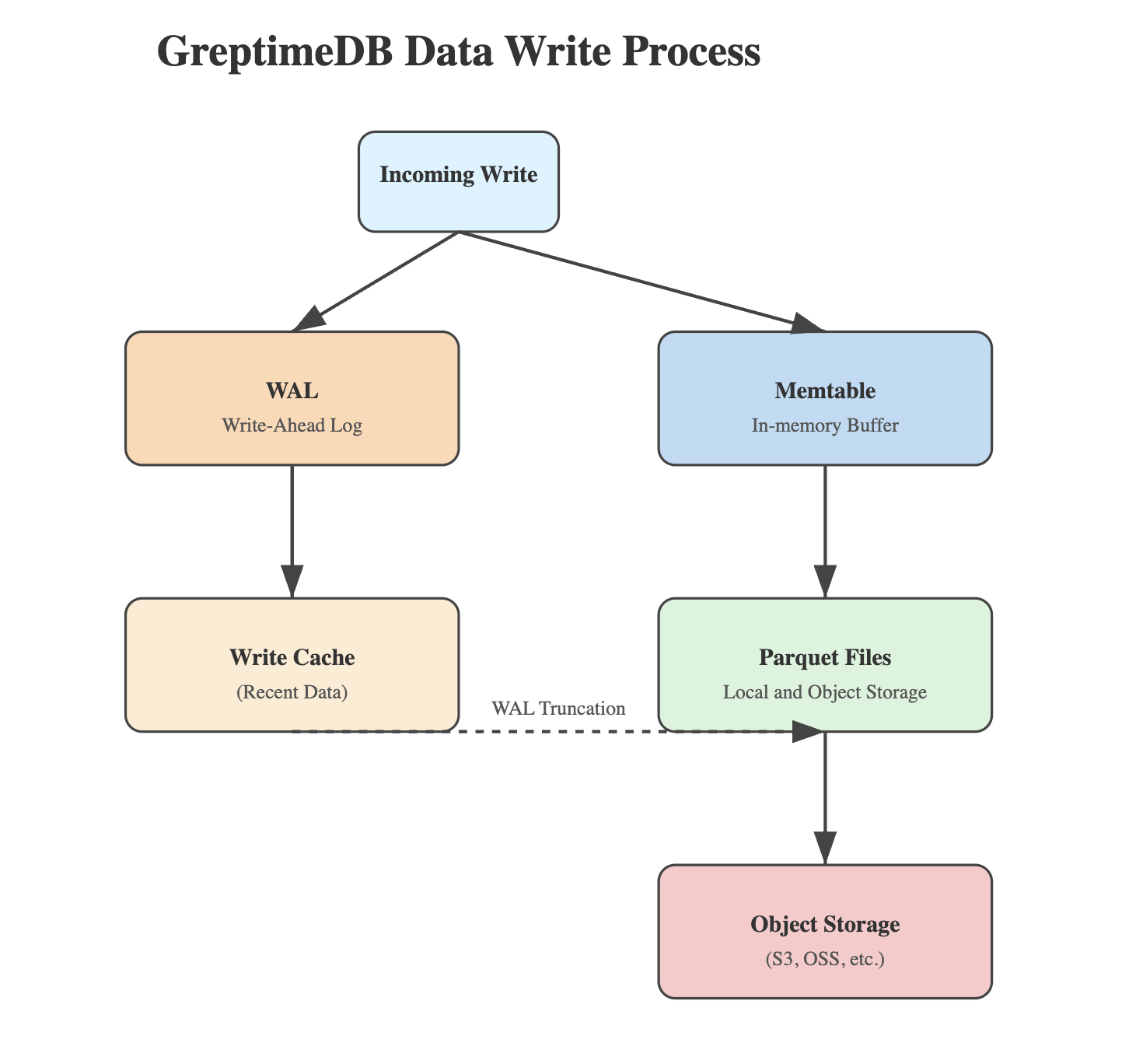
- WAL (Write-Ahead Logging)
- All writes are first logged to WAL.
- In distributed deployments, WAL can be backed by Kafka or mounted via PVC (Persistent Volume Claim).
- Ensures durability, even in the event of node failure.
- WAL can be disabled by table for ingestion from message queues like Kafka, relying on replayability instead.
- Memtable Processing
- Data flows from WAL into an in-memory Memtable, structured by time.
- Memtables provide low-latency in-memory querying.
- Persistence & Compaction
- When Memtable reaches a size/time threshold, it is flushed to disk.
- Data is converted to columnar Parquet format.
- Parquet files are written to both Write Cache and object storage.
- WAL Truncation
- The corresponding WAL will only be truncated after confirming that the data has been successfully uploaded to the object storage. ensuring fault tolerance.
Although some systems like VictoriaMetrics argue that WAL is unnecessary for monitoring workloads ("WAL Usage in Modern Time-Series Databases"), GreptimeDB provides users the flexibility to decide, rather than forcing an all-or-nothing approach.
Compression & Compaction Strategies
GreptimeDB employs time-series-specific compression and compaction techniques:
- Time-based Partitioning
- Data is organized by time windows, enabling efficient range queries.
- Partitioning strategy is configurable based on query patterns.
- Multi-Level Compression
- Newer data is stored in smaller files for efficient access.
- Older data undergoes progressive compaction, reducing fragmentation.
- Columnar Storage Optimization
- Utilizing Parquet’s columnar storage format, GreptimeDB achieves efficient data compression.
- Supports column pruning and predicate pushdown, reducing the volume of data scanned during queries.
For more details on GreptimeDB’s compaction strategy, refer to our documentation: GreptimeDB Compaction Guide.
Query Performance Optimization
GreptimeDB’s query engine leverages a multi-tier caching architecture to deliver optimal performance across different time ranges.
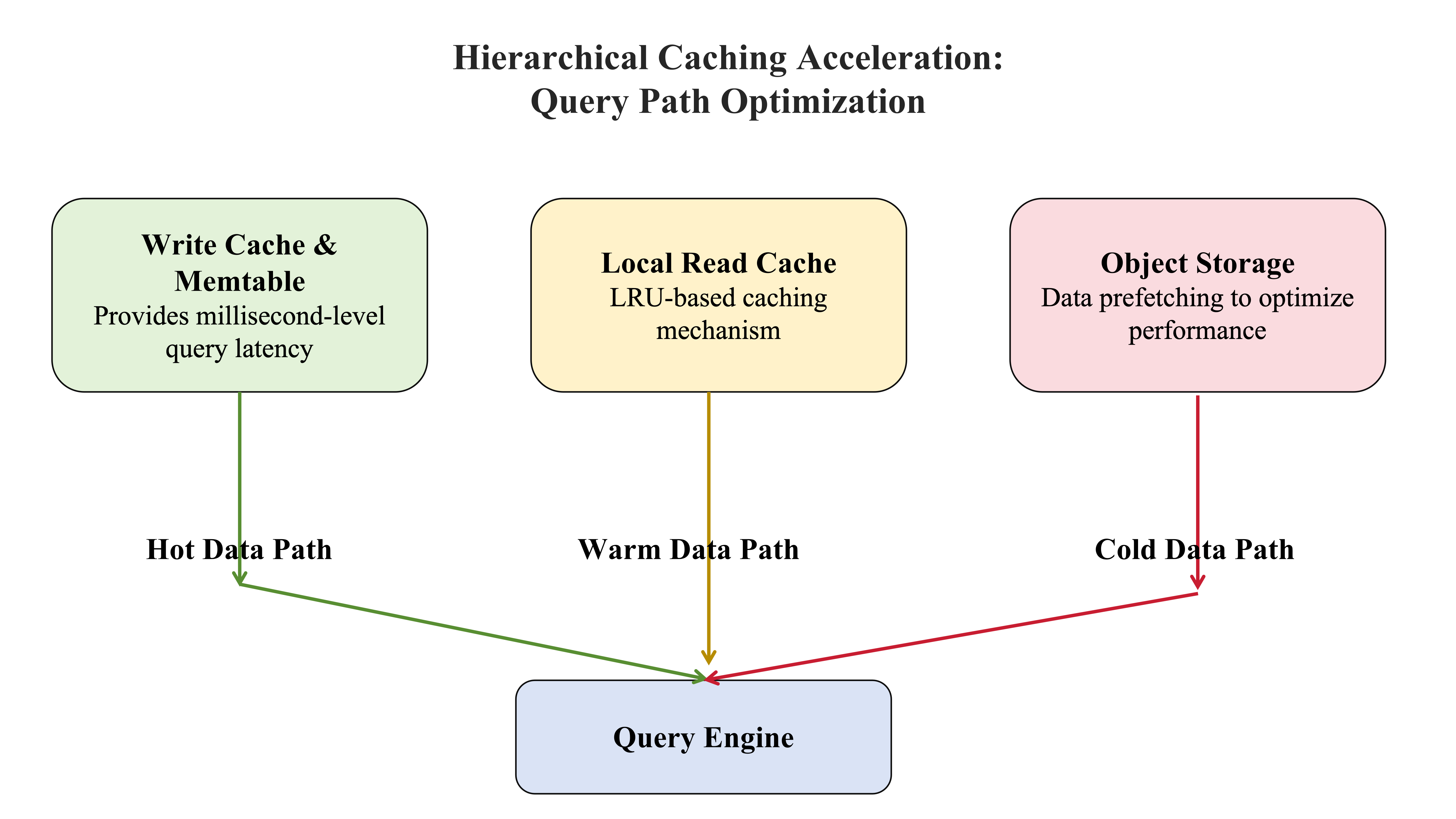
Query Path Optimization
- Hot Data Queries
- Recent data is retrieved directly from the Write Cache and Memtable.
- This bypasses object storage, ensuring sub-millisecond query latency.
- Warm Data Queries
- Recent historical data is fetched from local read caches.
- An LRU (Least Recently Used) mechanism ensures frequently accessed data remains in Read Cache.
- Cold Data Queries
- Long-term historical data may require retrieval from object storage.
- The system proactively prefetches relevant data into read caches for optimized performance.
Vectorized Execution and Parallel Processing
To further enhance query performance, GreptimeDB leverages Rust alongside Apache DataFusion and Apache Arrow:
- Vectorized execution maximizes the utilization of modern CPU SIMD instructions.
- Multicore parallel processing automatically decomposes complex queries into parallel tasks.
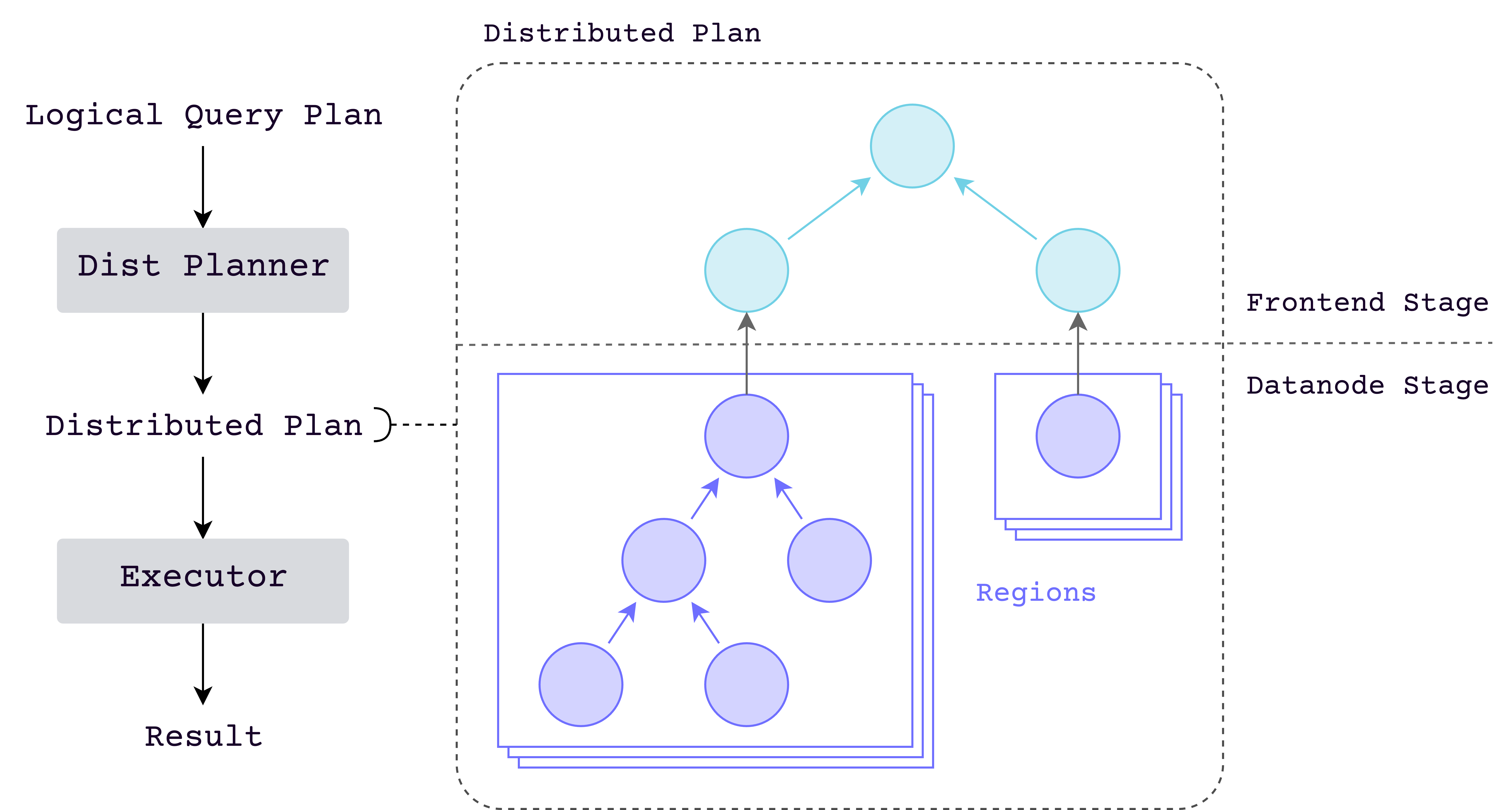
A distributed query engine decomposes queries into subqueries, each responsible for a portion of table data, then merges all results into the final output.
Future improvements will include enhanced query optimization strategies, enabling intelligent query planning that adapts execution plans based on data distribution and available resources.
Reliability and Disaster Recovery
Beyond performance and cost efficiency, GreptimeDB’s storage architecture prioritizes data reliability:
- Multi-Replica Strategy
- Object storage inherently offers high durability (e.g., AWS S3 provides 99.999999999% durability).
- Critical metadata and index information are replicated across nodes using distributed consensus protocols or cloud databases like RDS.
- Failure Recovery
- In case of node failure, data can be quickly restored using WAL (Write-Ahead Log) and object storage.
- Cross-region replication enhances disaster recovery capabilities.
- Data Integrity Verification
- All data written to object storage undergoes checksum validation.
- Background processes periodically verify data integrity, proactively detecting and correcting potential issues.
The Art of Architectural Balance: GreptimeDB
GreptimeDB’s storage architecture strikes a fine balance between multiple demands in observability data management:
✅ Cost Efficiency: Leverages object storage to significantly reduce costs.
✅ Query Performance: Multi-tier caching mitigates object storage latency.
✅ Write Throughput: LSM-tree design enables high ingestion rates.
✅ Data Reliability: WAL and multi-layered validation ensure data safety.
✅ Scalability: Object storage-backed design offers virtually unlimited capacity expansion.
For enterprises managing large-scale observability data, this well-balanced architecture delivers both cost-effectiveness and high performance. As IoT, 5G, and edge computing continue to drive explosive data growth, GreptimeDB’s innovative architecture is poised to play a crucial role in the future of data management.
By seamlessly integrating the cost advantages of object storage with the performance benefits of block storage, GreptimeDB unlocks new possibilities for time-series databases. Whether for cost-sensitive enterprise applications or real-time monitoring systems demanding ultra-low latency, this architecture provides a compelling solution.
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




