On this page

Time-series databases are domain-specific databases designed for time-series data, featuring efficient concurrent writing, data compression, and query performance. With the widespread use of IoT devices, a large amount of time-series data is generated and collected. We have written another blog on What is a Time-Series Database, if you're unfamiliar with time-series databases, give it a read first.
What is Our-of-Order Data
Time-series databases are optimized by considering the specific characteristics of time-series scenarios, such as frequent writes, few updates and deletions, and data written in chronological order. Ideally, we assume that data is written in real-time and in a sequential manner. However, in the real world, the situations are often more complex, and there is no guarantee that data will be written in sequence.
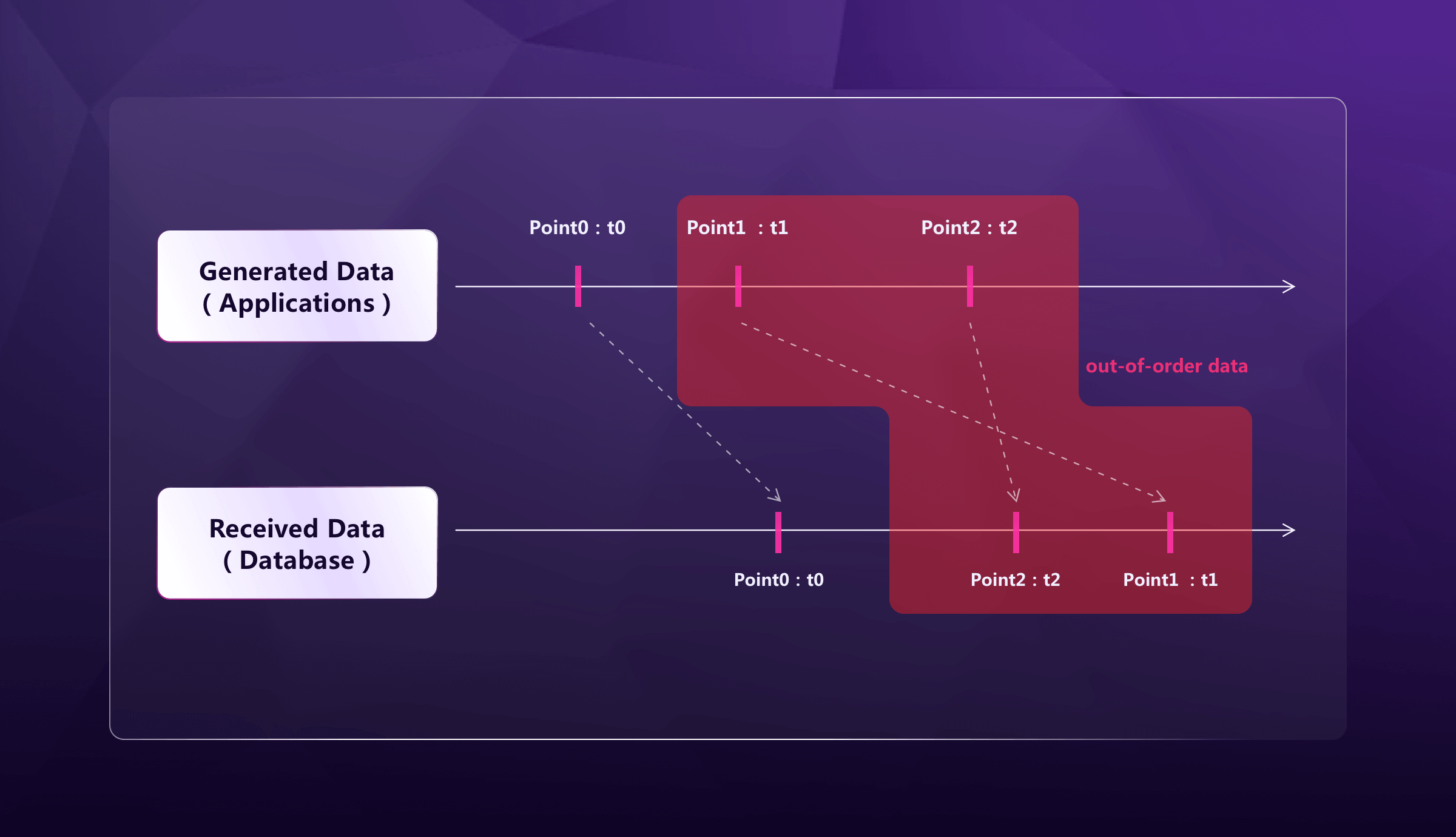
To better illustrate, let me first explain what out-of-order data is. In time-series scenarios, there are usually data-generating endpoints and receiving endpoints. There is a certain delay for data to travel from the generating endpoint to the receiving endpoint. If the sequence of the received data is consistent with which of the generated data, data is considered to be "in-order". However, if the data generated earlier is received later, it is considered to be "out-of-order" data.
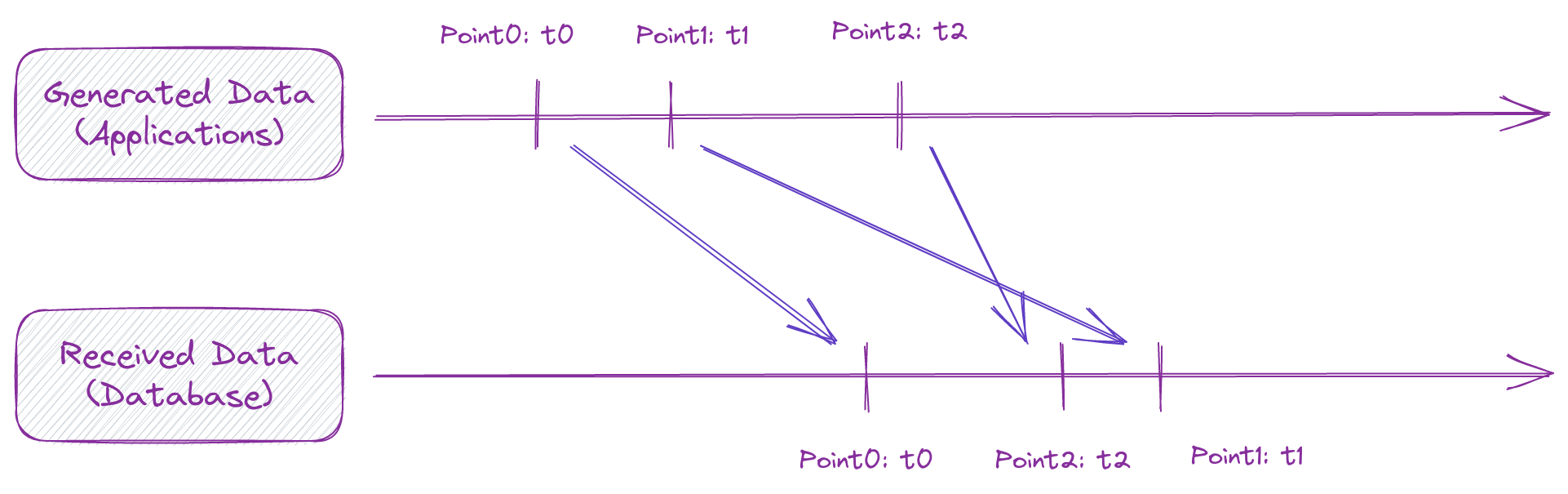
Above is a timeline where data points are generated at specific points in time. In an ideal scenario, these data points would be received by the receiving endpoint in the same order as they were generated. However, in the case of out-of-order data, some data points like Point1 arrive at the receiving endpoint later than expected, causing them to be out of sequence with the rest of the data.
Cause of Out-of-Order Data
Data may be out of order due to sensor failures, network latency, power outage,etc, posing challenges to time-series databases, such as:
- Data insertion and updates: out-of-order data creates challenges for data insertion and update therefore, affecting write performance.
- Data compression: out-of-order data may impact the effectiveness of data compression algorithms, increasing storage requirements.
- Query performance: out-of-order data may reduce query performance, increasing the consumption of computational resources.
Traditional LSM Tree Model for Time-Series Data Storage
Many time-series databases adopt the LSMT (log-structured merge-tree) storage model, which is a key-value data structure proposed by Patrick O'Neil and others in 1996 for disk-based, real-time low-cost indexing with continuous high-concurrency writes (and deletions). This particular data structure is an ideal for time-series scenarios as it allows for continuous high-concurrency writes and time-dimensional ordering. It is implemented in the GreptimeDB storage engine, and a simplified diagram of its architecture is provided below.
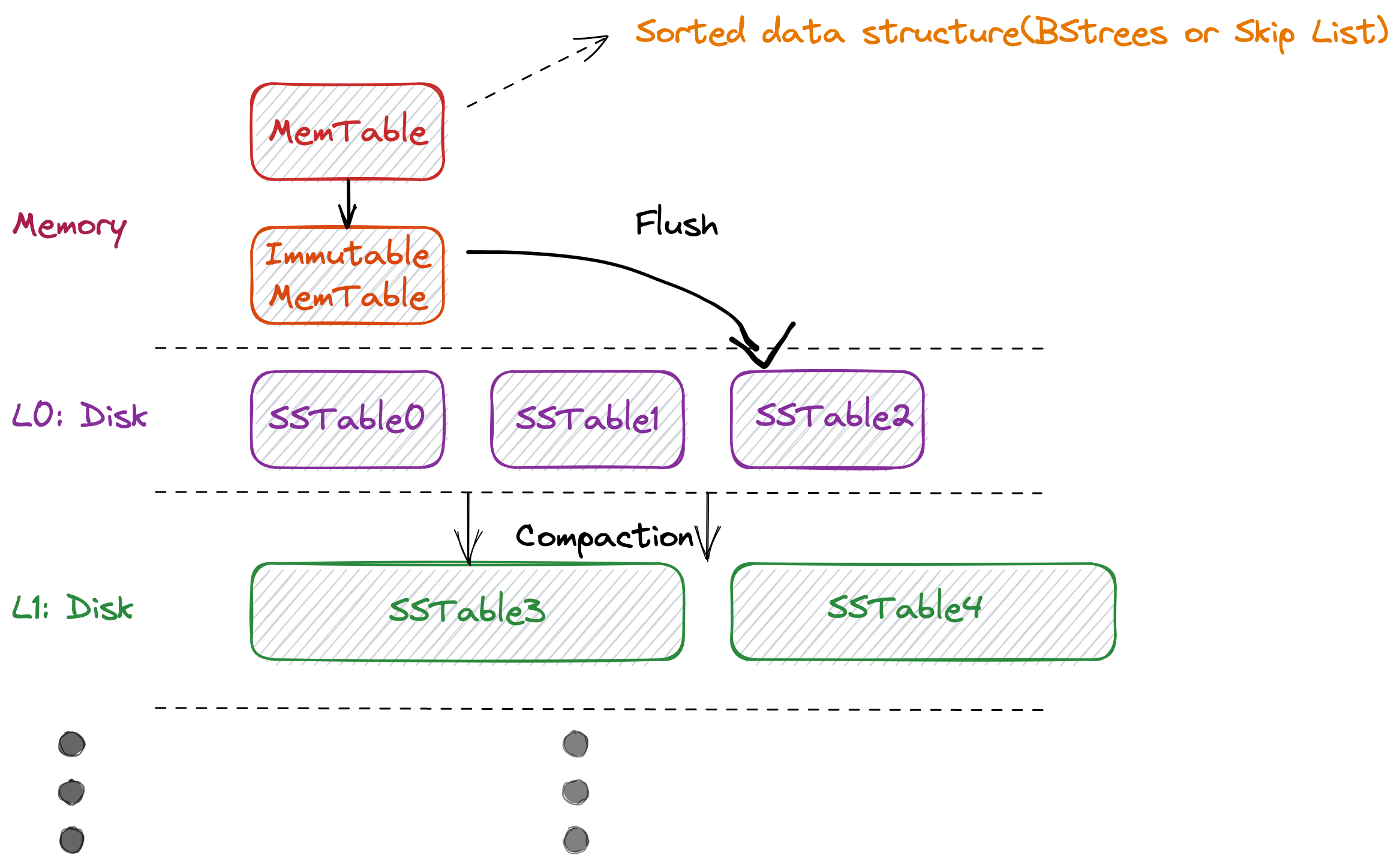
Main Components of LSM Tree
The main components of an LSM Tree include:
- MemTable: a sorted in-memory data structure, typically implemented using a Skip List in engineering practice, although B-Tree implementations also exist.
- Immutable MemTable: similar to MemTable, a sorted in-memory data structure, but read-only. It is created when the MemTable reaches its size limit.
- SSTable (Sorted String Table): similar to Immutable MemTable, a read-only sorted data structure, but persisted on disk. The common implementation method generally involves flushing the Immutable MemTable directly to disk.
SSTable Compaction and Optimization for Improved Query and Storage
To improve query and storage efficiency, compaction is often performed on SSTables. During the compaction process, SSTables from the same level are typically merged to generate new time-span SSTables for the next level (L+1). Other optimizations may also be performed, such as compressing to save storage space for historical data.
To better understand, here we will reference two facts without proof:
- In the implementation of a Skip List, the average time complexity for inserting is O(logN);
- In the implementation of a Skip List, the average time complexity for searching is O(logN); where N refers to the maximum number of key-value (KV) pairs that a MemTable can contain.
How Out-of-Order Data is Handled in LSM Tree model
Now let's return to the issue of out-of-order data and see how exactly is out-of-order data handled in the LSM Tree model.
The primary objective of handling out-of-order data is to ensure that the data is retrieved in chronological order in query processing, regardless of how it was originally received.
Ideally, time-series data is collected chronologically before received and written to the database in order. With no additional operation needed, the write complexity is O(logN). In this case, each SSTable is arranged sequentially within the file with no overlap between files. When we query data within a specific time range, we'll retrieve the SSTables that intersect with the query time range (it probably includes Immutable MemTable and MemTable). Then, search the first and last SSTable files to find the start and end points. Next, the contents of the files is concatenated and the time complexity can be controlled at O(2*logN + k), where k is a constant. We will not explain the methods of swiftly copying data to memory and retrieving it in detail here.(Of course, in the ideal world, it is entirely possible to achieve O(1) write time complexity using an append-only data structure.)
However, the real world is full of uncertainties and disordered data is inevitable. As illustrated above, SSTables cannot guarantee the absolute order between files, especially at L0 level. Then what impact will this bring?
When we cannot guarantee that SSTables are ordered, in the worst-case scenario, all SSTables that intersect with the query time need to undergo a multi-way merge during the query process. The time complexity calculated using a conventional algorithm (min-heap multi-way merge) can be up to O(NlogM), where N is the number of K-V data points to be returned, and M is the number of SSTables, which is much higher than the O(klogN) time complexity in an ideal situation. Fortunately, the real world does not always present the worst-case scenarios. We can simplify the problem into four cases based on the timestamp range of the out-of-order data:
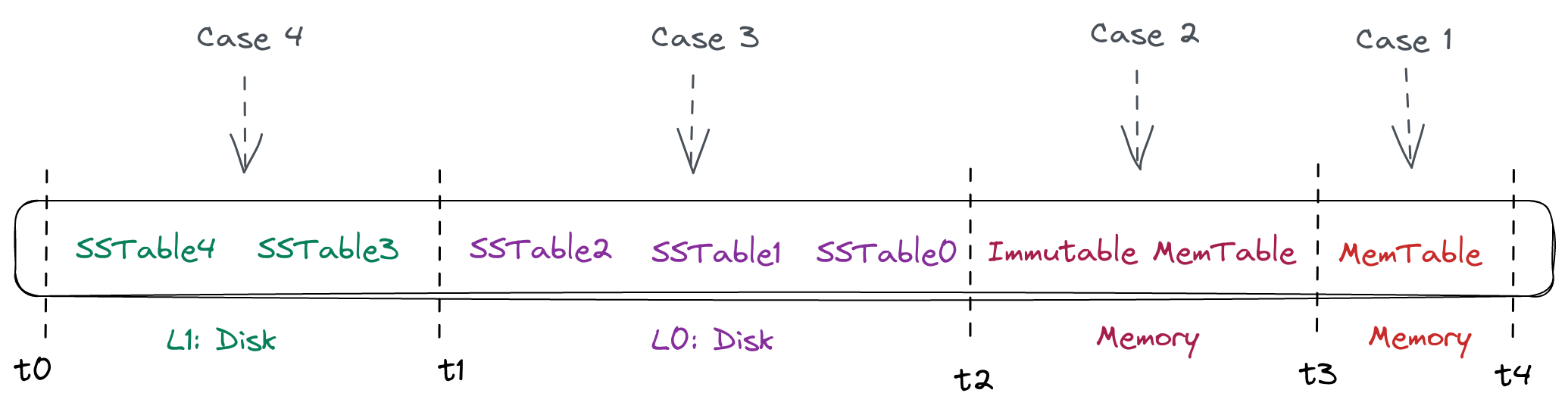
- Case 1: The timestamp of the out-of-order data occurs only between t3 and t4, i.e., in the MemTable layer. This situation aligns with the ideal case since the MemTable itself is an ordered data structure. When out-of-order data comes in, it will be sorted simultaneously.
- Case 2: The timestamp of the out-of-order data occurs only between t2 and t3, i.e., possibly in the Immutable MemTable layer. This case is similar to Case 1. When querying, you can read the MemTable and Immutable MemTable simultaneously and perform merge sorting. As both operations take place in memory and the volume of data isn't substantial, the impact is relatively minimal.
- Case 3: The timestamp of the out-of-order data occurs between t1 and t2. This scenario is more challenging as it involves on-disk storage. On one hand, it may involve merging more data files, and on the other hand, it involves disk I/O operations.
- Case 4: The timestamp of the out-of-order data occurs between t0 and t1. In this case, the situation is similar to Case 3 but more complicated. This suggests that even the SSTables at the L1 layer cannot guarantee sequential order between data files, thereby increasing the necessity for additional merge sorting operations.
Summary
To summarize, various types of out-of-order data can lead to an increase in merge operations, which in turn results in heightened disk activities. This subsequently induces a notable performance loss and a rise in resource utilization cost.
Understanding these underlying reasons allows us to implement corresponding optimizations. For example, the simplest way is to set restrictions at the product level, allowing only out-of-order data that occur within a short period of time to be written into the database. In this way, it confines the out-of-order data to be within Case 1 and Case 2, discarding the ones outside these cases. For time-series scenarios, this may already be sufficient for the majority of situations.
Of course, in very strict scenarios where handling out-of-order data up to Case 4 is necessary, detailed optimizations can also be made. For example, when new data arrives, if its timestamp differs a lot from the one of the latest data, consider writing it into a separate MemTable and delaying the disk write to reduce the frequency of merge operations. However, this approach still compromises query performance, leading to a trade-off between functionality and performance.
In time-series databases, there are also cases that do not use the LSM tree model, such as TimescaleDB, which is based on PostgreSQL. When handling out-of-order data, it utilizes its hypertable and PostgreSQL's built-in capabilities, which may impose more limitations.
GreptimeDB is a time-series database based on the LSM tree model, natively supporting out-of-order data processing. To ensure richer user scenarios, we are continuously optimizing the handling of out-of-order data in different situations and will share these insights in upcoming articles. Please stay tuned.
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




