On this page
Single-node databases typically use Write-Ahead Logging (WAL) to ensure atomicity, consistency, and durability of operations. Distributed databases, on the other hand, face more complex scenarios due to the coordination of state across multiple machines. When designing distributed systems, it's common to assume that all modules are unreliable, a principle known as the "fault-tolerance assumption". In distributed systems, modules may encounter failures, delays, communication failures, and other issues, necessitating the design of systems to handle such unreliability.
To support internal transactions in a distributed database, GreptimeDB has designed and implemented the Procedure framework to ensure the atomicity, consistency, and durability of modifications to multiple state data in the database. In our previous article, Procedure Framework - How GreptimeDB Improves the Fault Tolerance Capability, introduced the motivation and implementation of the Procedure framework, leaving some plans for the future work. This article builds upon the previous work and shares recent progress made by GreptimeDB in internal distributed transactions.
It's worth noting that such internal transaction frameworks exist in the majority of distributed systems. For example, Apache HBase has a Procedure V2 framework, and Apache Accumulo implements the Fault-Tolerant Executor (FATE), a distributed multi-step operation framework. Furthermore, for business applications, there's Temporal, a persistent execution framework built on the same design principles, which supports a unicorn company valued at $1.5 billion. We believe that the technology and experiences shared in this article are very helpful for developers looking to explore the realm of data processing. 😃
Rollback-capable Procedure
In PR-3625, we introduced a rollback mechanism for Procedures, enabling the system to roll back when encountering non-retryable errors.
Taking the rollback-enabled Drop Table DDL (PR-3692) as an example. Initially, the Drop Table DDL consisted of the following four steps:
- Preparation
- Physical deletion of metadata
- Notification of Region deletion to the datanode
- Cache deletion
In this process, if a non-retryable error occurs during step 3, the entire procedure cannot be rolled back because the metadata has already been deleted. At this point, the Region without metadata becomes data fragments, which might lead to data leakage or other more serious issues.
To ensure atomicity when this operation fails, we refactored the steps of the Drop Table Procedure to support rollback. The rollback-capable Drop Table Procedure now includes the following five steps:
- Preparation
- Logical deletion of metadata
- Notification of Region deletion to the datanode
- Cache deletion
- Physical deletion of metadata
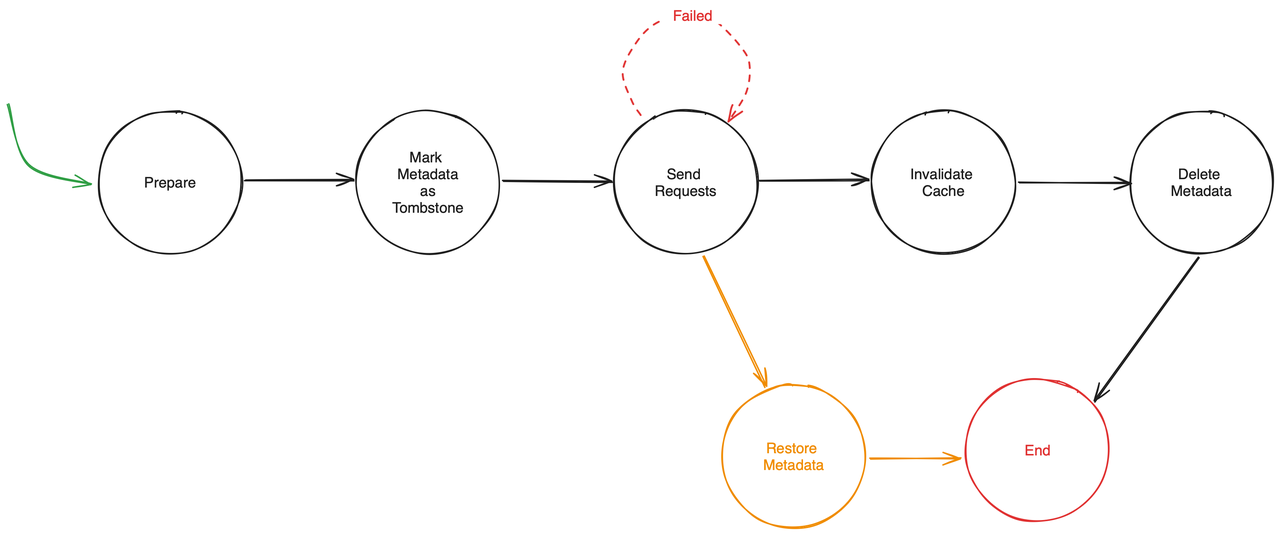
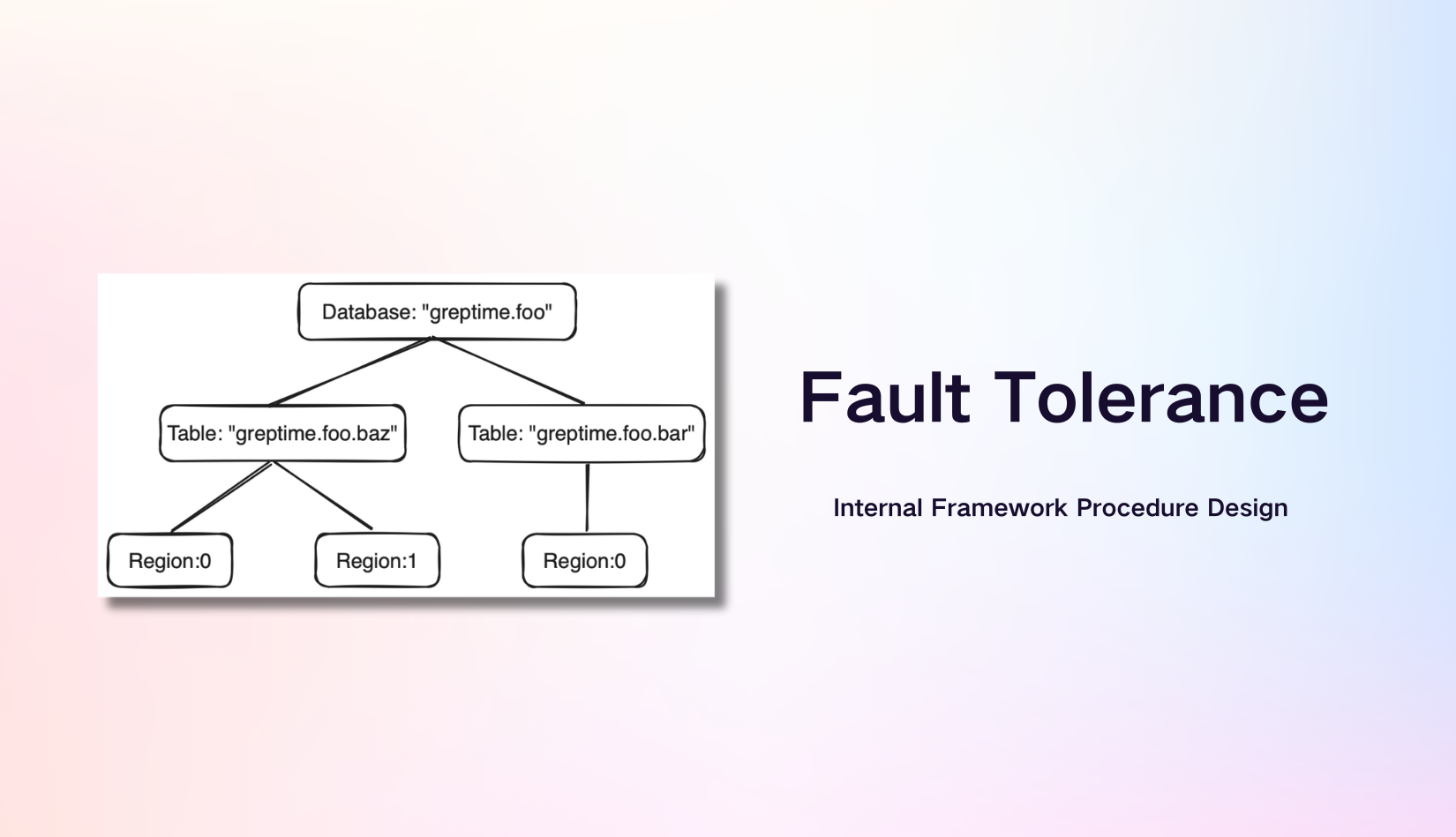
The yellow path in Figure 1 represents the rollback steps. If a non-retryable error occurs in step 3, you can roll back along the yellow path to ensure data integrity.
Fine-grained Locks in Procedures
Why Introducing Fine-grained Locks
Before introducing fine-grained locks (PR-3061), we only supported locking resources at the level of Tables using mutex locks within the Procedures.
However, this method might lead to the following issues:
- Drop Database requires locking all data table resources;
- During the execution of Drop Database, it was also possible to create tables in the database being deleted;
- When operating on resources smaller than a table, Procedures could only be executed serially.
For instance, the Region Migration of different Regions within the same table cannot be executed in parallel. This is because the Region Migration Procedure requires acquiring a lock at the table level, rather than at the more granular Region level.
At this point, astute students might be eager to answer, "Have you considered using Hierarchical Lock, a staple in university database exams?"
As you suspect, the implementation of fine-grained locks in Procedures is heavily inspired by the design principles of hierarchical locks. At the outset, we researched the implementation of hierarchical locks and dug up this landmark paper from 1975, Granularity of Locks and Degrees of Consistency in a Shared Data Base.
This paper on Hierarchical Locks is a milestone in the database field, authored by the IBM System R team. They published a series of articles on database topics during the same period, such as The Notions of Consistency and Predicate Locks in a Database System. These articles are still widely cited over the past decade. It's also worth mentioning that Predicate Locks haven't been entirely phased out by the times; there are applications of its variants in libraries like Rust Moka. These works laid the foundation for many concepts in today's relational databases, such as transactions, consistency, etc.
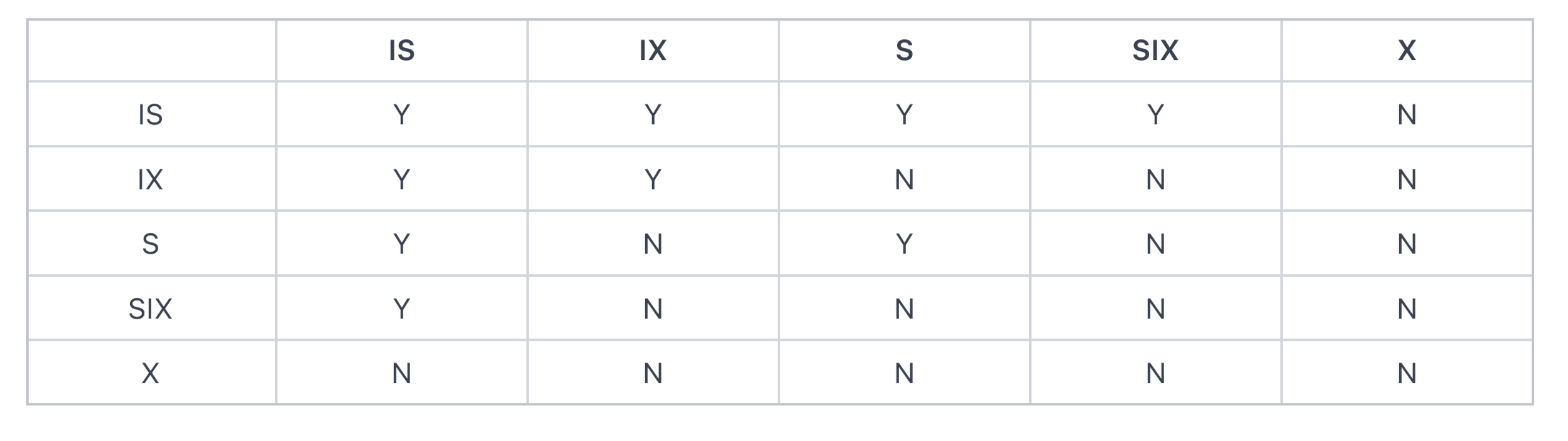
The core design goal of Hierarchical Locks in the original paper was to achieve a way of implicitly locking the entire subtree. Besides implicit subtree locking, there's also a way of explicitly locking the subtree, by obtaining locks from leaf nodes to root nodes step by step.
Design of Fine-grained Locks in GreptimeDB
Inspired by the approach of explicitly locking subtrees, we decided to integrate these two methods of subtree locking in designing fine-grained locks. This means we allow both implicit locking of the entire subtree and explicit locking of subtrees. By adopting this approach, we can manage concurrent Procedure executions more flexibly, thereby enhancing the performance and efficiency of the database.
Additionally, in the original paper, Hierarchical Locks offered multiple locking modes to provide more flexible concurrency control. However, these features are not necessary in our scenario. We have discarded these complex modes and retained only the shared mode and exclusive mode to simplify lock management.
Workflow of Procedures with Fine-grained Locks
Here are a few examples illustrating how fine-grained locks in Procedures help us solve the aforementioned issues:
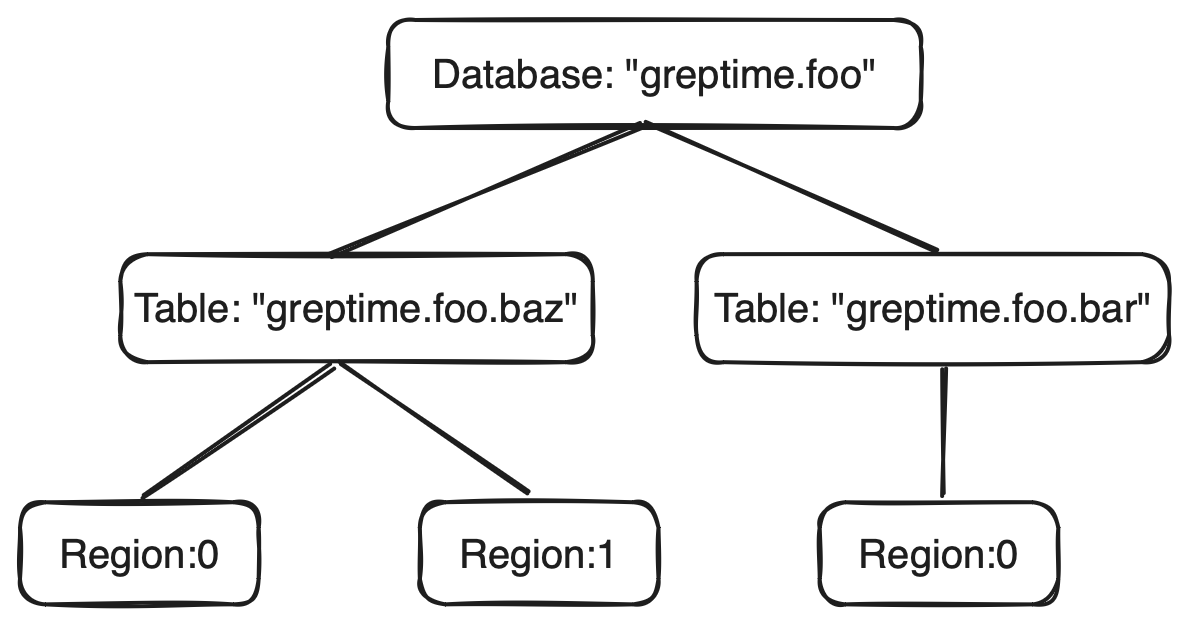
DDL Procedure
For Procedures that modify databases, let's consider an operation aimed at deleting the greptime.foo database. First, we need to acquire an exclusive lock on the database resource named greptime.foo. This operation actually allows us to implicitly lock the entire subtree of resources under the greptime.foo database, thereby addressing the following two issues:
- We don't need to explicitly acquire locks for the entire subtree; we can implicitly lock all resources under this database.
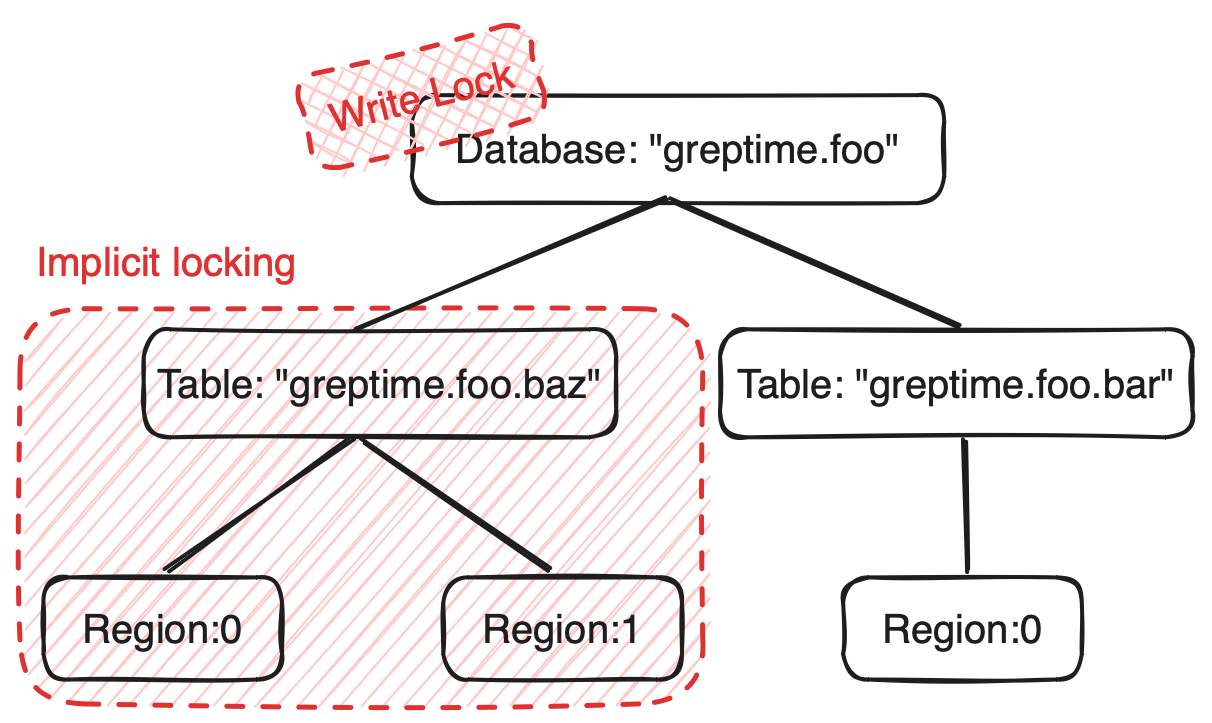
- When executing Procedures for creating or deleting databases, corresponding DDL Procedures for tables under the database and Region Migration Procedures (ISSUE-2700) will not execute because they cannot obtain shared locks on the
greptime.foodatabase resource.
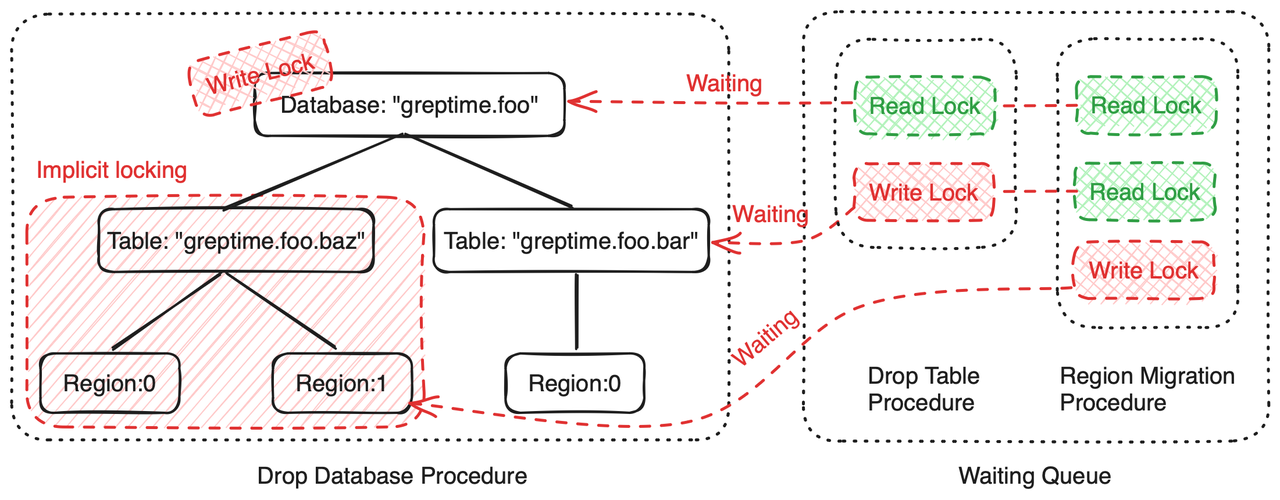
Region Migration Procedure
For the Region Migration Procedure, we need to explicitly lock the entire subtree, obtaining locks from leaf nodes to root nodes step by step to fulfills our requirements:
- Region Migration Procedures for Different Regions of the Same Table can be Executed in Parallel.
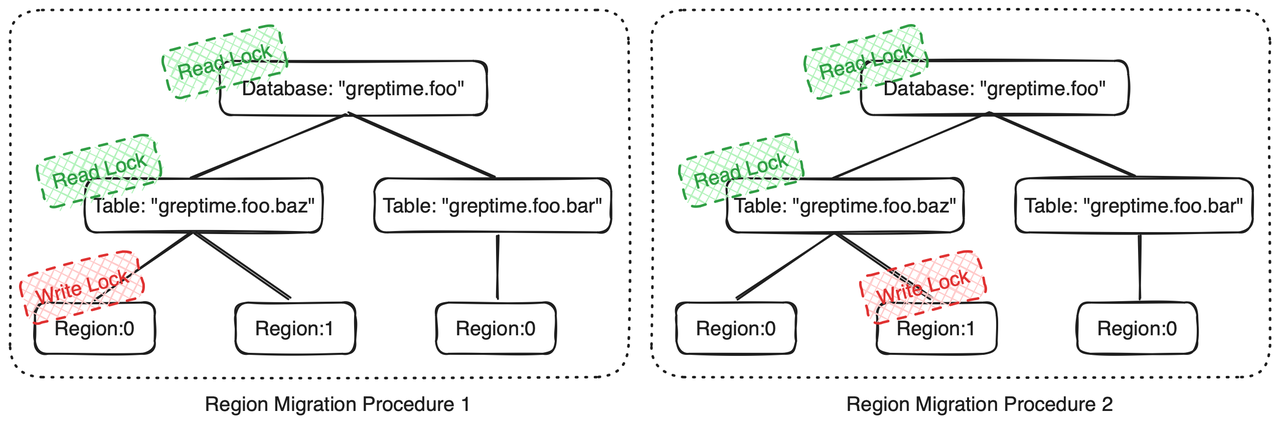
- When executing the Region Migration Procedure, DDL Procedures for the same table will not be executed because they cannot obtain an exclusive lock on the
greptime.foo.baztable resource.
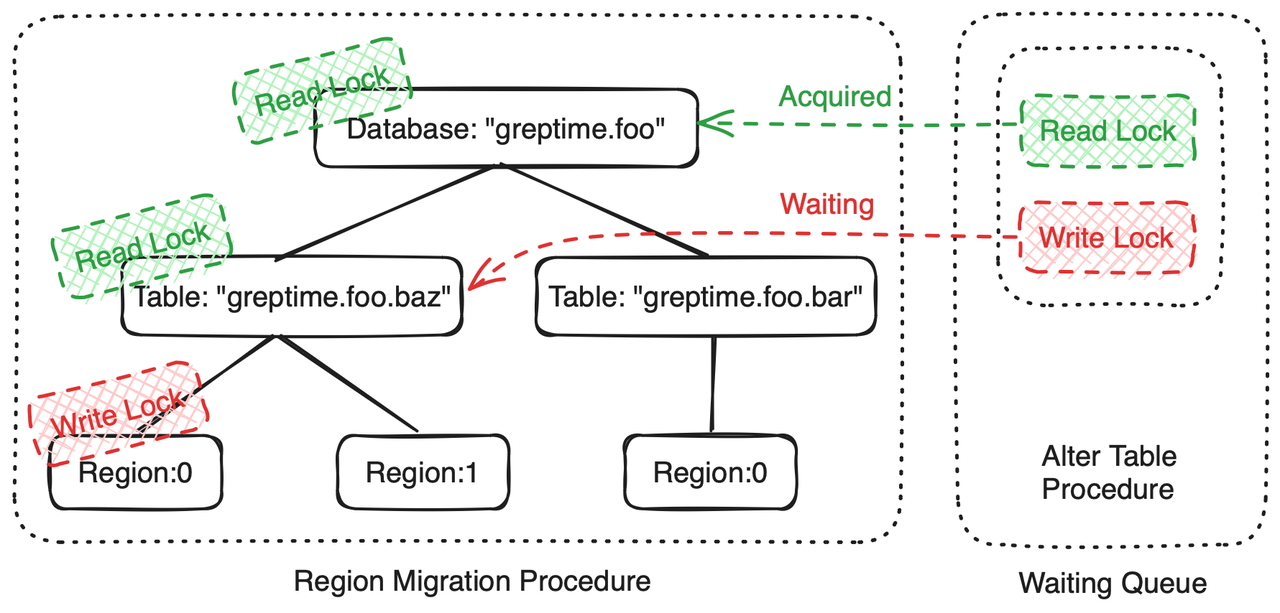
Implementation of Drop Database
With the support of fine-grained locks, we were able to implement the Drop Database Procedure (ISSUE-3516) in a more elegant manner.
The state machine of the Drop Database Procedure is illustrated in the diagram below:

In essence, the Drop Database Procedure can be divided into the following steps:
- Acquire an exclusive lock on the database being deleted.
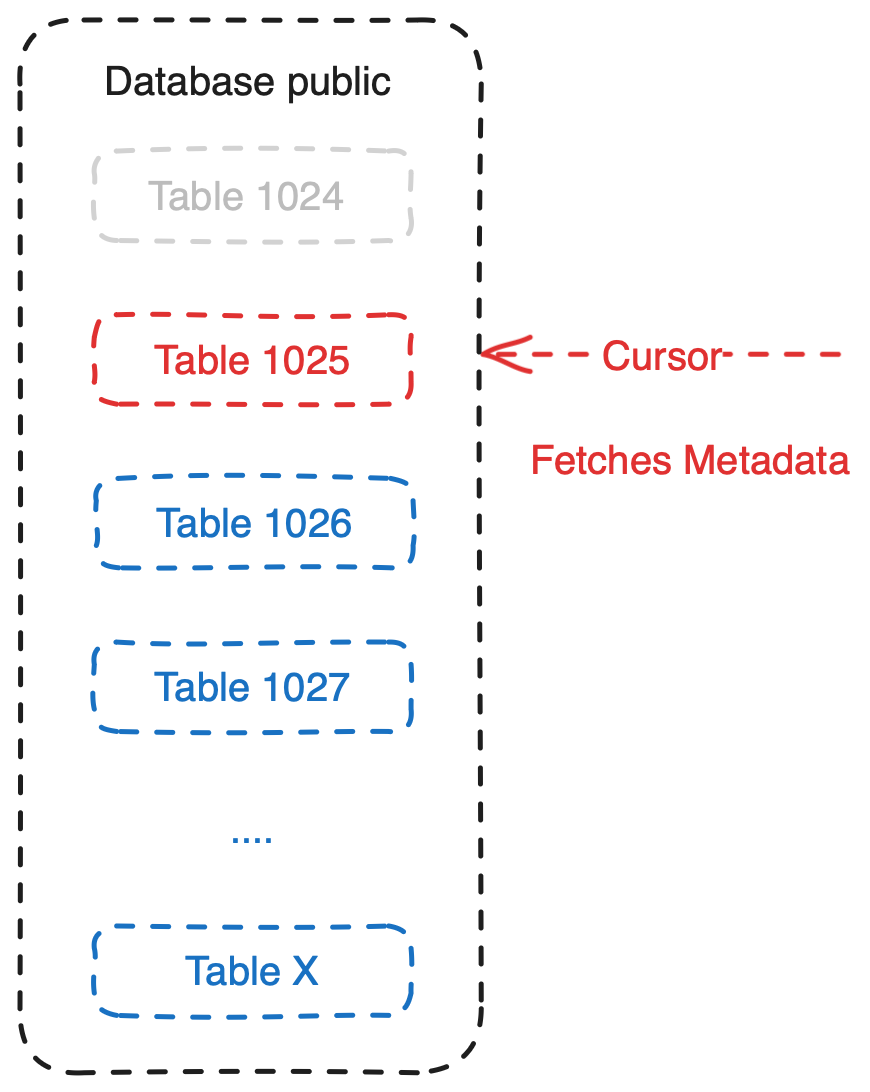
- The cursor is responsible for loading the metadata of the next table to be deleted.
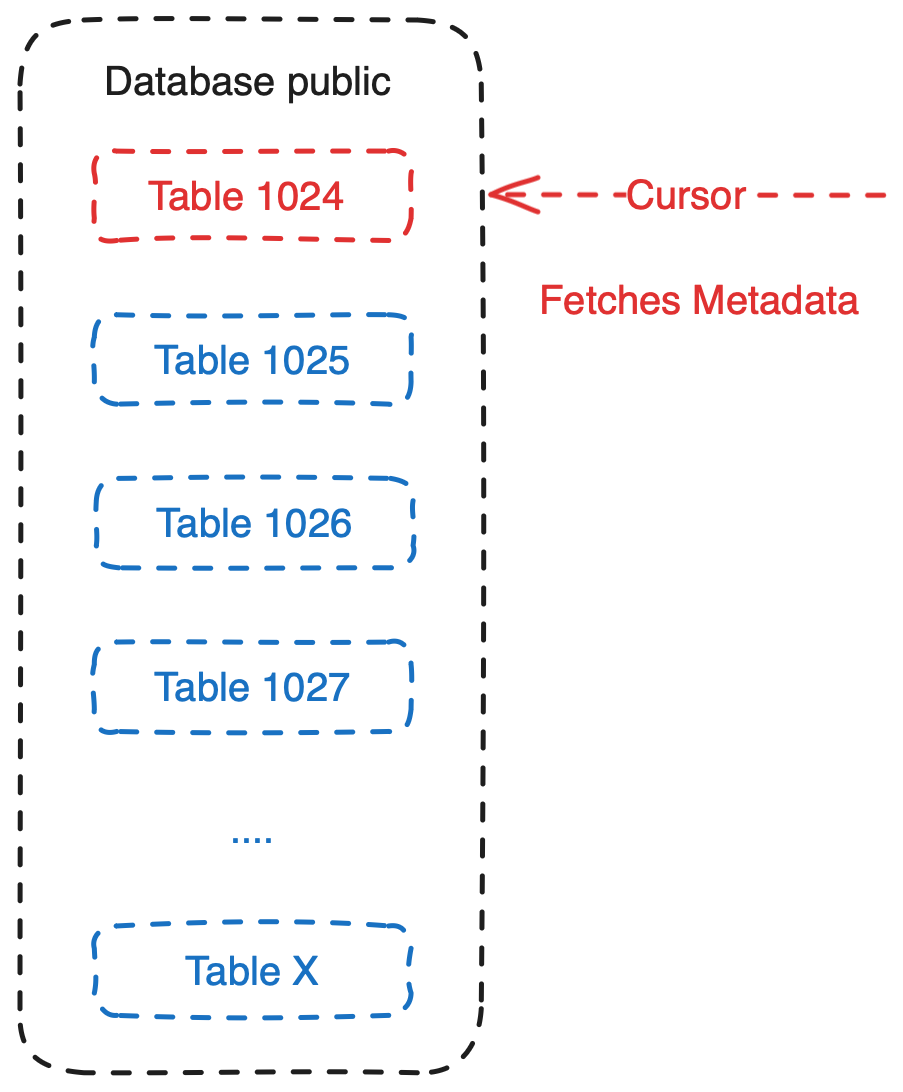
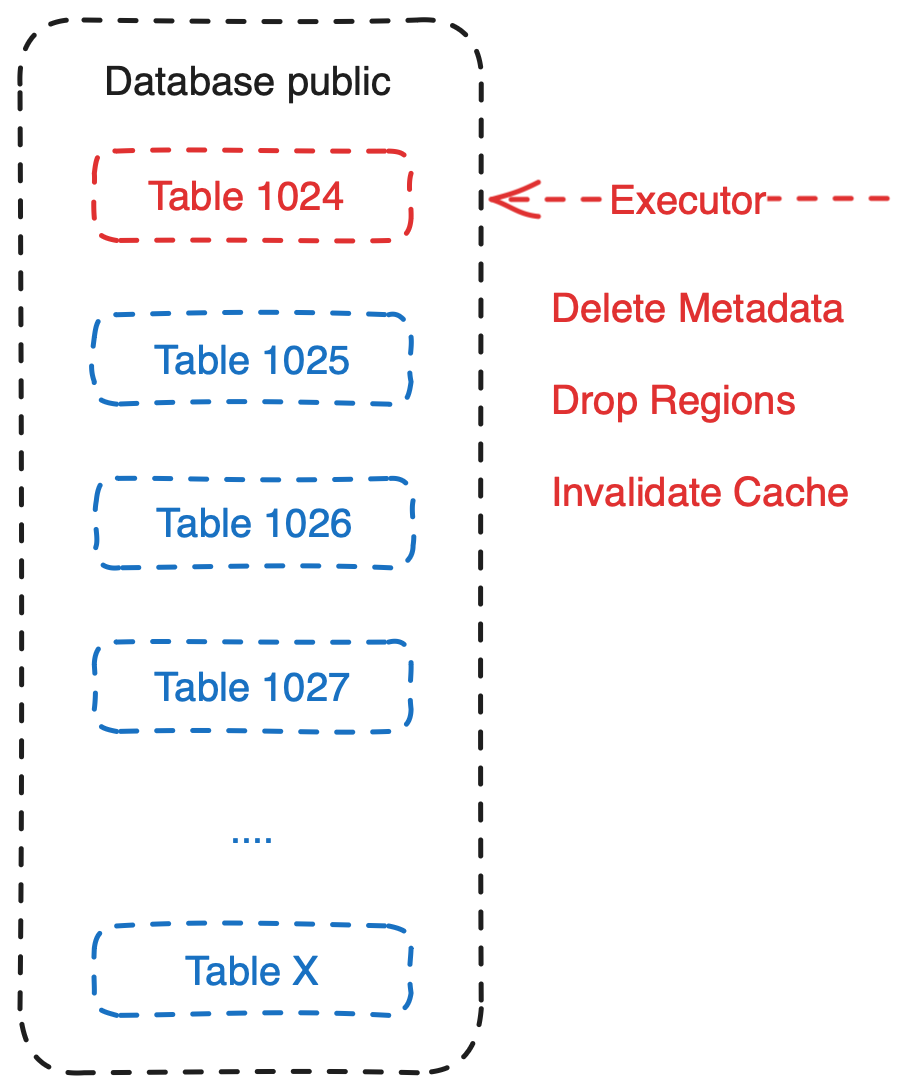
- The executor is responsible for deleting the corresponding metadata of the table, deleting the corresponding regions, and clearing the cache.
- Repeat the above steps until all tables under the database are deleted.
- Finally, delete the metadata of the database and clear the cache.
Future Work on Procedures
Currently, GreptimeDB's Procedure framework supports rollback and fine-grained locks. It can be said that all the basic functionalities required by GreptimeDB Procedures have been implemented. In the future, we will focus on adding more fuzz testing and chaos testing to the Procedure framework to improve its usage and optimization.
Additionally, there are still many DDL operations that have not been implemented. Their implementation will further utilize the Procedure framework, which may bring about more new requirements. Recent DDL support work includes:
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




