On this page
Background of Buffer and Rate Limits
Pipeline tools are an essential part of modern observability systems. Beyond supporting multiple data protocols, their reliability in handling events—whether metrics, logs, or traces—is a critical consideration for users.
During upstream failures or business surges, pipelines often experience sudden traffic spikes. If downstream storage cannot handle the surge, it can trigger an "avalanche effect", resulting in abnormal observability pipelines. This not only causes loss of critical business metrics but also hinders troubleshooting by losing essential monitoring data.
To mitigate such scenarios, capacity planning typically accounts for traffic spikes, which may require dynamic scaling of downstream resources or adding queues to flatten the peaks. However, these solutions either depend on the design of downstream storage or support limited protocols. To address these limitations, Vector introduces buffer and rate limits mechanisms.
Buffer: Holding Events for Sink Consumption
A buffer acts like a reservoir to hold events before they are sent to the sink. In Vector, most sinks are split into two components: a buffer and a request handler. The request handler continuously fetches events from the buffer and sends them downstream per the specified protocol. Essentially, a buffer serves as a connecting pipeline between the source, transform, and sinks.
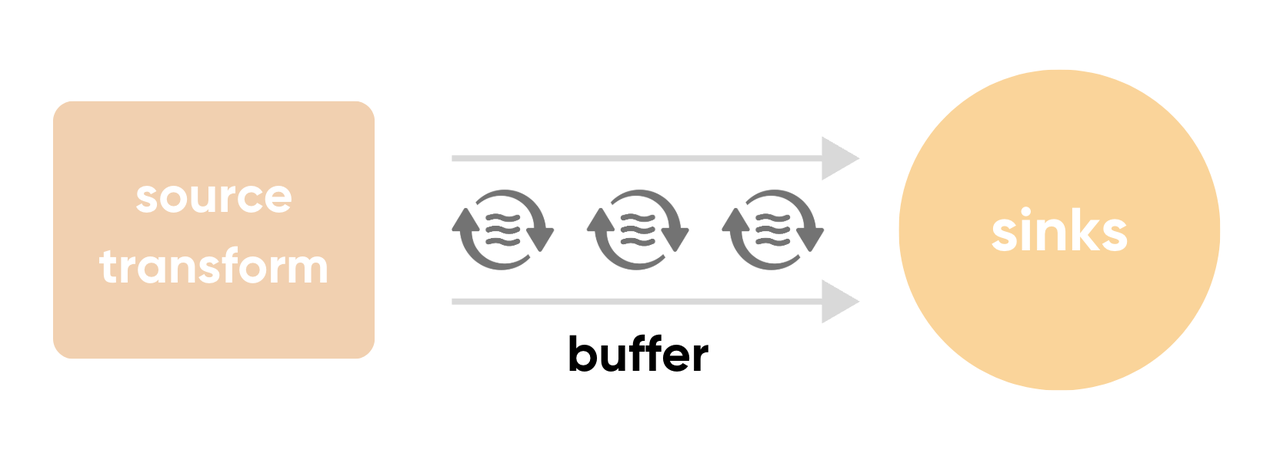
When an event arrives at a sink, it first attempts to enter the sink's buffer. The behavior depends on the buffer's status:
If space is available, the event is immediately added.
If the buffer is full due to slow downstream consumption, its configured policy determines the action.
Types of Buffers
Memory Buffers
Memory buffers store data in memory. By default, Vector allocates a memory buffer capable of holding 500 events per sourceand uses a when_full policy of block. Under this policy, upstream writes are blocked when the buffer reaches capacity, consuming upstream resources. For scenarios requiring higher data integrity without blocking writes, the drop_newest policy can be configured to discard new events when the buffer is full, avoiding upstream delays.
Memory buffers excel in speed and efficiency, incurring negligible overhead. However, they come with limitations:
Memory is a costly resource, requiring careful sizing to avoid waste or crashes.
Data in memory buffers is lost if the process or machine restarts, making them unsuitable for applications with stringent data integrity requirements.
To address these shortcomings, Vector provides disk buffers.
Disk Buffers
Disk buffers store data on disk, allowing recovery after process restarts. While they avoid data loss, they incur additional read/write overhead, making them slower than memory buffers. Disk buffers provide higher data integrity, although not as robust as database-grade mechanisms like Write-Ahead Logging (WAL). Events are written to disk at 500ms intervals, leading to potential inconsistencies between in-memory and on-disk data. As a result, some events might be replayed or lost during recovery.
While both types of buffers address the challenge of peak shaving to some extent, each comes with its own advantages and limitations. Users must choose the appropriate buffer type based on their specific requirements. Vector also provides a mechanism to combine the two buffer types, creating multi-tiered buffers. This capability, though powerful, will not be elaborated on here. Although buffers can temporarily store some data, Vector continues to dispatch data downstream at the highest possible rate. Consequently, traffic spikes may still propagate to downstream systems. To ensure a more stable flow within capacity planning constraints, rate-limiting measures are essential to protect downstream components.
Rate Limits and Batching
Batching is a common strategy in large-scale data ingestion, significantly improving throughput. In Vector, all HTTP-based sinks batch events, reducing protocol overhead and optimizing shared resources. When implementing the greptime_logs sink, Vector's robust HTTP component simplifies configuration with features like:
Multiple encoding formats (e.g., JSON, Protobuf)
Built-in
metricsintegrationAdaptive concurrency control, retries, and rate limits
The configuration of the Vector HTTP component is abstracted into a struct called TowerRequestConfig. When implementing a sink, you need to define a config struct to configure the sink. To integrate the functionality of the HTTP component into this config struct, you simply need to include TowerRequestConfig and use this configuration when constructing the sink service. This approach is highly convenient.
The HTTP component is built on Tower[1], a powerful framework for managing request states like concurrency, retries, and rate limits. Here's an example configuration:
toml
batch.max_events = 1000
request.rate_limit_duration_secs = 1
request.rate_limit_num = 1Key parameters:
batch.max_events: Maximum events per batchrequest.rate_limit_duration_secs: Rate limit window in secondsrequest.rate_limit_num: Maximum requests per window
The above configuration parameters, when translated into event volume, mean that the maximum number of events allowed per unit time is calculated as:
batch.max_events * request.rate_limit_num / request.rate_limit_duration_secs.
With such a configuration, the pressure on downstream components becomes stable. As long as the buffer size is set appropriately, data during traffic spikes will temporarily accumulate in the buffer. Thanks to rate limiting, downstream components are insulated from these traffic spikes. This acts as a protective measure for foundational downstream components, preventing the entire pipeline from being overwhelmed. It ensures the robustness of the entire pipeline and maintains data integrity.
Buffer and Rate limites Protect both upstream and downstream
By combining buffer and rate limits, Vector creates a resilient pipeline that protects both upstream and downstream components. This solution handles normal traffic fluctuations effectively while reducing hardware costs. Whether memory or disk buffers—or a combination—Vector enables flexible configurations to meet diverse user needs.
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




