
On this page
Logs: A Key Player in Monitoring and Data Analytics
Logs play a crucial role in monitoring, operations, and data analytics. They are indispensable in troubleshooting online systems, analyzing user behavior, tracking ad clicks, and monitoring edge IoT devices. Log data includes server logs, application logs, and security records, often reaching terabytes or even petabytes per day for mid-to-large-scale enterprises. The challenge lies in efficiently and in real-time processing these vast amounts of log data within IT infrastructures.
ClickHouse has become a major choice for log storage systems worldwide, covering even specialized log types like traces. Its high compression rates and performance make it a strong alternative to ELK (Elasticsearch). Since 2024, GreptimeDB has been developing its log processing engine and has recently demonstrated outstanding results in ClickHouse’s official JSONBench benchmark, ranking first in Cold Run and fourth in Hot Run.
This article compares the features and performance of ClickHouse and GreptimeDB in log processing scenarios to assist users in choosing the right log storage system.
Core Differences: General-Purpose OLAP vs. Observability-Optimized Design
ClickHouse is a general-purpose OLAP database that efficiently handles a wide range of analytical queries. It excels in log analysis, financial processing, and IoT scenarios due to its flexible design and mature SQL ecosystem.
In contrast, GreptimeDB is a cloud-native database designed for observability data, making it well-suited for metric collection, log storage, and real-time monitoring. Its architecture is optimized for high-frequency time-stamped data ingestion and querying, such as metrics, logs and events.
Feature Comparison
| Product | ClickHouse | GreptimeDB |
|---|---|---|
| Data Model | Columnar storage, table-based, general OLAP | Columnar storage, table-based, unified model for metrics, logs, and traces |
| Performance | Strong OLAP performance, balanced for time-series data | Optimized for observability workloads, excelling in read/write performance and compression |
| Scalability | Horizontal scaling with manual configuration | Cloud-native auto-scaling via Kubernetes |
| Query Language | SQL | SQL, native PromQL support |
| Cost Efficiency | Hardware-dependent | Primarily based on object storage such as S3, separation of storage and compute for efficiency |
| Ecosystem Compatibility | Rich plugin ecosystem; mature SQL support | Supports multiple ingestion protocols; compatible with MySQL/PostgreSQL protocols; Parquet storage for big data integration |
| Community Support | Large, stable community | Growing community focused on observability |
Log-Specific Feature Comparison
Beyond the core features, log storage systems also require additional capabilities. Here’s how ClickHouse and GreptimeDB compare in this domain:
| Product | ClickHouse | GreptimeDB |
|---|---|---|
| Visualization | Integrates with Grafana, Kibana | Built-in log views; integrates with Grafana, Kibana |
| Elasticsearch API Compatibility | Not natively supported; possible via third-party tools | Enterprise edition supports Elasticsearch’s REST API |
| Log ETL | No built-in ETL | Built-in pipeline for converting unstructured logs to structured logs |
| Logs to Metrics Conversion | Materialized views; pre-aggregated tables | Flow-based stream processing |
| Structured & Unstructured Logs | Supports both; experimental full-text search (high write impact) | Supports both; built-in full-text indexing |
| Traces Ingestion & Query | Requires manual modeling; SQL-based queries | Built-in Otel Traces modeling; supports SQL and Jaeger query protocols |
Performance Analysis
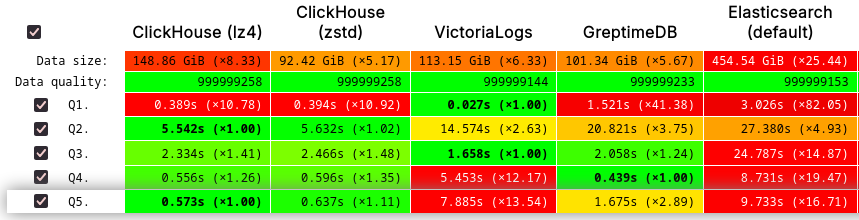
The performance differences between the two can be summarized as follows. For detailed data, refer to our benchmark study: “67.5% Boost in Write Performance, 50% Lower Storage Cost —— GreptimeDB v0.12 Log Performance Benchmark.”
| Product | GreptimeDB | ClickHouse |
|---|---|---|
| Version | v0.12 | 24.9.1.219 |
| Data Model | Supports structured & unstructured logs (full-text indexing enabled) | Supports structured & unstructured logs (experimental full-text search) |
| Write Performance (TPS) | 185,535 (structured); 159,502 (unstructured) | 166,667 (structured); 136,612 (unstructured) |
| Write Throughput (HTTP Protocol) | 470% of Elasticsearch | Better than Elasticsearch, slightly below GreptimeDB |
| Query Performance (Structured Data) | COUNT query: 6ms; Keyword search: 22.8ms | COUNT query: 46ms; Keyword search: 52ms |
| Query Performance (Unstructured Data) | COUNT query: 6ms; Keyword search: ~2547ms | COUNT query: 8ms; Keyword search: ~2080ms |
| Compression Rate | 13%-33% (best efficiency) | 26%-51% |
| CPU Usage (%) | Structured: 13.2%; Unstructured: 10.29% | Structured: 9.56%; Unstructured: 26.77% |
| Memory Usage (MB) | Structured: 408MB; Unstructured: 624MB | Structured: 611MB; Unstructured: 732MB |
| Object Storage (S3) | 1%-2% performance loss | Natively supported |
In summary, GreptimeDB achieves comparable read/write performance to ClickHouse while offering advantages in compression rates and resource efficiency. Notably, its object storage performance remains nearly unaffected.
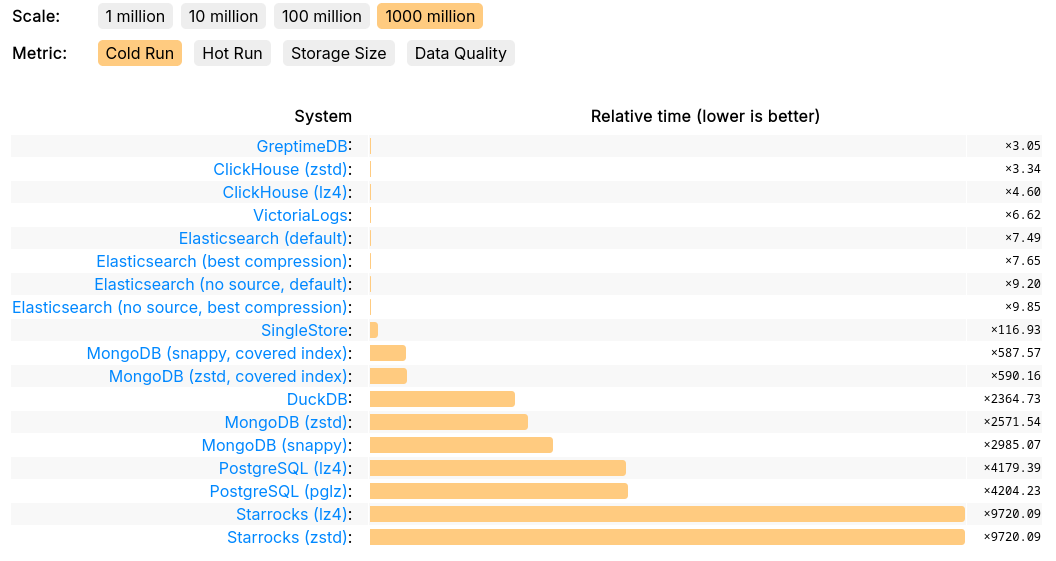
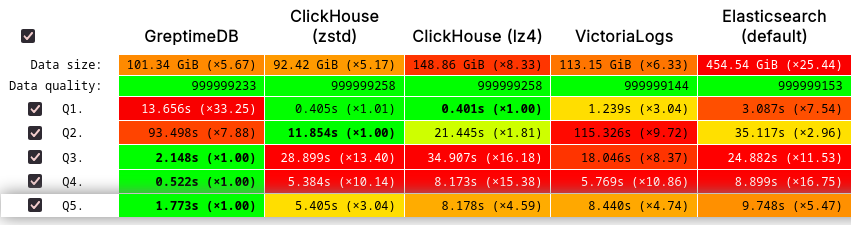
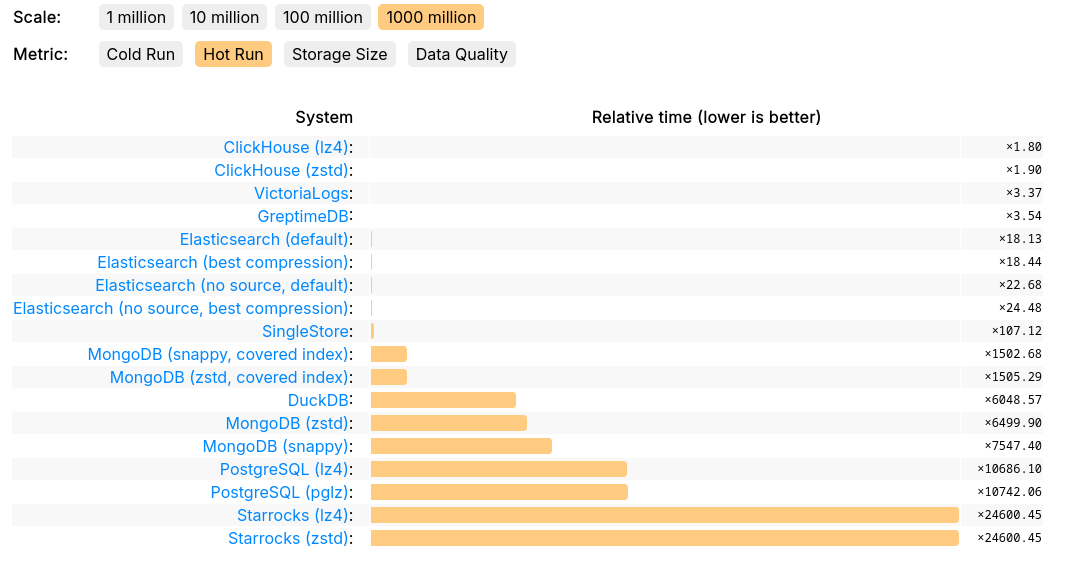
Furthermore, GreptimeDB’s performance was validated in ClickHouse’s official JSONBench, showcasing its competitiveness in handling large-scale datasets:
- Ranked 1st in 1-billion document Cold Run
- Ranked 4th in 1-billion document Hot Run
Scalability: A Key Differentiator
Scalability is often a decisive factor in database selection. ClickHouse and GreptimeDB take fundamentally different approaches in this aspect. For more information about GreptimeDB storage architecture, please read this blog.
Complex Scaling with ClickHouse
ClickHouse supports horizontal scaling through sharding and replication, along with vertical scaling. However, horizontal scaling requires manual configuration, including adding nodes and rebalancing data. ClickHouse Cloud offers auto-scaling but lacks the flexibility of GreptimeDB’s open-source elastic scaling.
Seamless Auto-Scaling with GreptimeDB
As a cloud-native database, GreptimeDB employs a storage-compute separation architecture. Built on Kubernetes, it enables seamless elastic scaling, making it ideal for cloud environments. Independent resource scaling ensures cost efficiency and stable performance under high-demand workloads—requiring minimal manual intervention.
Storage-Compute Separation Architecture
While ClickHouse allows storing data on object storage like S3 (reference), this architecture has some limitations:
First, scaling still requires data replication, even though the data is already in S3. This results in a cumbersome expansion process and unnecessary storage overhead. Although ClickHouse provides Zero-Copy Replication, it still has many bugs and is not recommended for production use. In fact, ClickHouse officially recommends using the closed-source SharedMergeTree.
Second, ClickHouse only moves data files to object storage, while metadata (such as table schemas and data files metadata) is still managed locally and synchronized via Zookeeper. This easily leads to consistent issues between local and object storage metadata, along with various scalability and reliability challenges.
In contrast, GreptimeDB stores table metadata in MetaSrv and places data file metadata directly in object storage. This eliminates local storage dependencies, enhancing scalability and reliability in cloud-native environments.
| Product | ClickHouse | GreptimeDB |
|---|---|---|
| Scaling Method | Supports both horizontal and vertical scaling, but horizontal scaling requires manual configuration (adding nodes, rebalancing data), making large-scale expansion complex. | Built on a cloud-native architecture with storage-compute separation, enabling seamless elastic scaling—ideal for cloud environments. |
| Cloud Support | ClickHouse Cloud offers auto-scaling options, but still has limitations compared to the elastic scalability of open-source GreptimeDB. | Kubernetes-native deployment with independent resource scaling, ensuring cost efficiency, flexibility, and stable performance without manual intervention. |
| Storage-Compute Separation | Data can be stored on object storage like S3, but scaling still requires data replication, making the process complex and leading to storage waste. Zero-Copy Replication has numerous issues and bugs. | Metadata and data are stored separately—table metadata in MetaSrv, while data file metadata is managed in object storage. This lightweight architecture offers better scalability. |
| Metadata Management | Table schemas and data files metadata are still stored locally and synchronized using Zookeeper, leading to inconsistencies and scalability challenges. | Centralized metadata management in MetaSrv, with data file metadata managed in object storage, ensuring better consistency and scalability. |
| Use Cases | Broad OLAP query and analysis, but limited scalability and cloud-native compatibility. | Excels in observability and IoT scenarios, making it ideal for high-scalability and elasticity-demanding applications. |
Choosing Your Right Database: A Practical Guide
Choosing between ClickHouse and GreptimeDB depends on your specific workload requirements:
✅ When to Choose ClickHouse
- Broad analytical queries across multiple domains
- Requires a mature community and extensive documentation
- Mixed OLAP workloads with observability use cases
✅ When to Choose GreptimeDB
- High-frequency, time-stamped data (e.g., metrics, logs, observability data)
- Cloud-native architectures requiring elastic scalability and cost efficiency
- Workloads needing PromQL integration and compatibility with Prometheus
Conclusion for Database Selection
ClickHouse is a powerful general-purpose OLAP database with excellent performance, flexibility, and a large ecosystem. However, GreptimeDB excels in observability scenarios, offering optimized log and metric storage, high ingestion speed, and a scalable, cloud-native architecture tailored for monitoring and IoT workloads.
Both solutions are open-source, providing flexibility for different use cases. The choice ultimately depends on data characteristics, scalability needs, and cost considerations.
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




